Hybrid Core Allocation: From Overallocation to Reliable Sharing
April 21, 2026
Alexandr Sudakov
Senior Software Engineer
Ivan Shibitov
Staff Software Engineer

Introduction
Some time ago, we introduced cpusets into Odin, Uber’s stateful container orchestration system. This change gives us stricter control over how CPU time is allocated, which helps cut down on throttling, and reduces latency, but comes at the cost of assigning full dedicated CPUs.
For years, our vertical CPU scaler operated under the assumptions that CPU usage could be accurately measured using one-minute averages, that cores allocated to a node were dedicated and not shared, and that CPU utilization targets could adjust to changes in failover load.
While these assumptions provided a baseline for managing workloads, they proved insufficient for handling bursty CPU usage patterns. In this post, we describe how we use cpusets, cpu_shares, and our key observation at the host level to improve the performance, reliability, and cost-effectiveness of colocated workloads.
From Dedicated to Hybrid
The Odin platform is evolving to handle workloads with bursty CPU profiles more intelligently. The new model introduces shared core allocation alongside dedicated cores:
- Hybrid allocation. Workloads now receive both dedicated (reserved) cores and an optional number of shared cores.
- Over-allocation control. Shared cores are pooled per host and over-allocated using a defined ratio.
- Fair contention handling. Linux® cpu.shares dynamically distribute shared CPU time based on allocation size.
- Vertical scaler upgrade. The scaler calculates optimal dedicated and shared core allocations for each workload.
Empirical Study of CPU Shares
We conducted an extensive proof of concept using Linux cpuset.cpus and cpu.shares to simulate and measure how shared core configurations behave under different load profiles.
We found that while there’s no contention and only a few workloads cause light contention, the Linux scheduler balances workloads between CPUs and satisfies the requested cpu.shares ratio. However, the real ratio during severe contention becomes strongly skewed. Similar results were observed in rkube (SoCC’21). Keep this in mind when you place a lot of active workloads in a shared pool.
The final formula we use for specifying shares is the following:
cpu.shares = round((dedicated_CPUs + shared_CPUs_for_contention) × 100)
Dedicated CPUs are always integer, while shared CPUs can be float. This is why we use a factor of 100 to make it work since the final value should be an integer. Also, a factor of 100 helps to think of the value as percentages of one CPU.
For example, if a container should have two dedicated CPUs plus half of a shared CPU, the calculation works out as:
cpu.shares = round((2 + 0.5) × 100) = 250
With this approach, cpu.shares directly mirrors the CPU resources you intend to allocate, striking a balance between precision and simplicity.
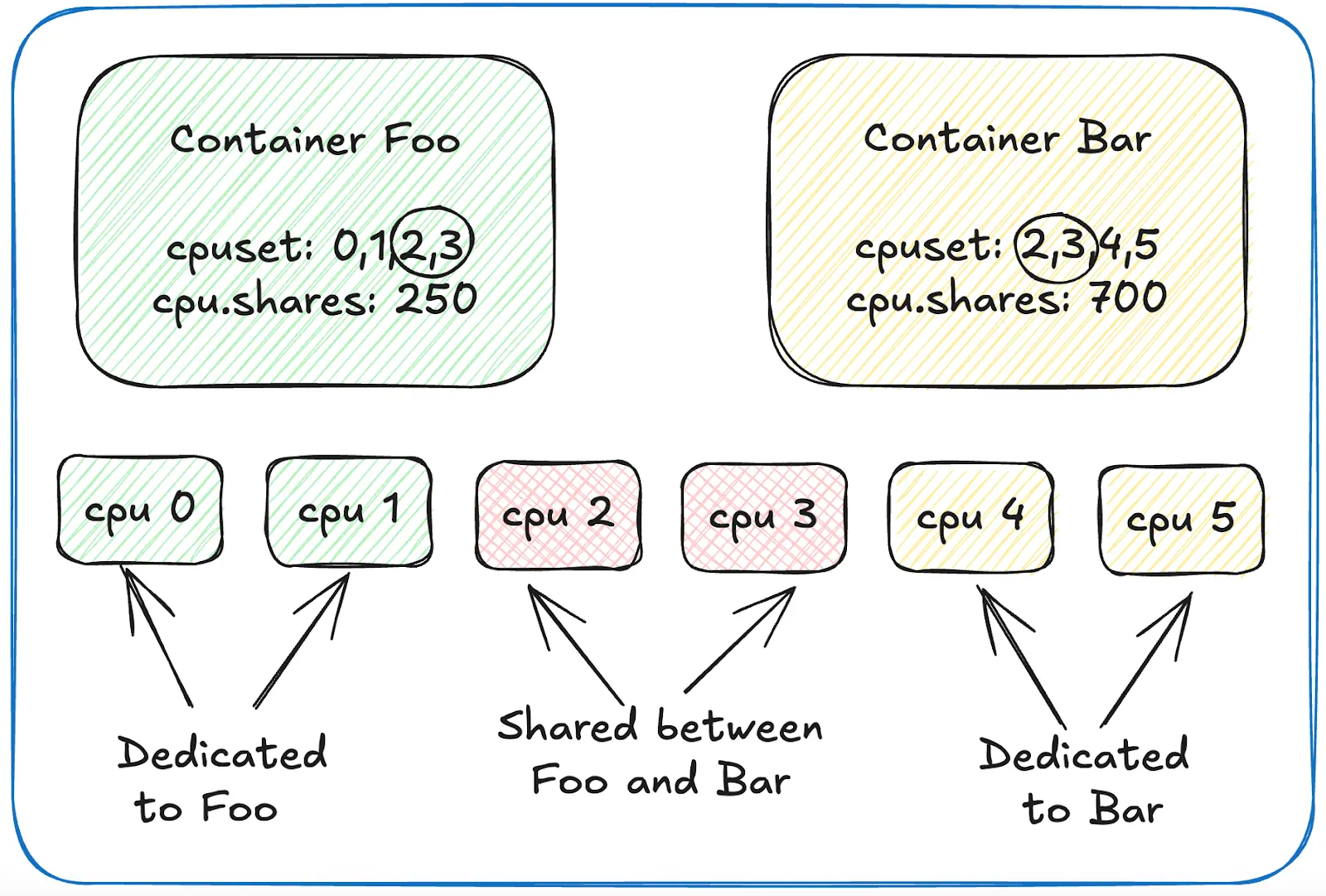
Figure 1. Colocation of multiple workload containers on shared and dedicated cores.
.
NUMA Considerations: Understanding CPU and Memory Affinity in Linux
Efficient memory access is crucial for application performance, especially on multi-socket systems with NUMA (Non-Uniform Memory Access). During our thorough testing, we observed the following.
- Memory allocation for a given CPU. The Linux scheduler generally picks the CPU closest to where most of a process’s memory resides. When constrained with cgroups, if a process’s memory is mostly on a given NUMA socket, it tends to run on CPUs from that socket. However, shared libraries can skew this balance.
- CPU selection after memory allocation. By default, Linux allocates memory from the NUMA node nearest to the CPU running the allocation. If local memory isn’t available, it falls back to other nodes.
- Memory migration/balancing. Automatic NUMA balancing can migrate pages to the nodes that use them most. This can be controlled globally via /proc/sys/kernel/numa_balancing or per-cgroup with cpuset.memory_migrate.
We took away that the kernel already optimizes for local memory usage. Explicit NUMA pinning isn’t always necessary. We also found that memory migration tuning is possible, but requires benchmarking for real benefits. Our strategy is to allocate dedicated cores within the same NUMA node while spreading shared pools across multiple NUMA nodes. This configuration optimally satisfies both workload performance and host agent efficiency
CPU Allocation Strategy for the Hybrid Model
Odin uses a hybrid model for CPU allocation, combining dedicated and shared cores to keep workloads efficient and balanced across NUMA nodes. The host agent—odin-agent—is responsible for managing this distribution, making decisions that prevent overload and optimize resource use.
For shared cores, the process begins by trying to balance them evenly across all nodes. If more shared cores are needed, the agent prioritizes placing them on nodes that already have a heavier dedicated CPU load. This approach avoids overburdening less busy nodes and helps maintain an even distribution of work.
When allocating dedicated cores, the agent prefers to keep them on the same node as the workload’s shared cores, reducing latency and keeping processing local. It makes sure that dedicated cores don’t overlap with shared ones, and if the preferred node can’t provide enough capacity, it moves on to other nodes until the requirement is met.
Before any allocation happens, Odin checks if the requested number of CPUs can actually be provided. If this is not possible, the process returns an error; however, an “ensure” loop automatically retries until the desired state is reached.
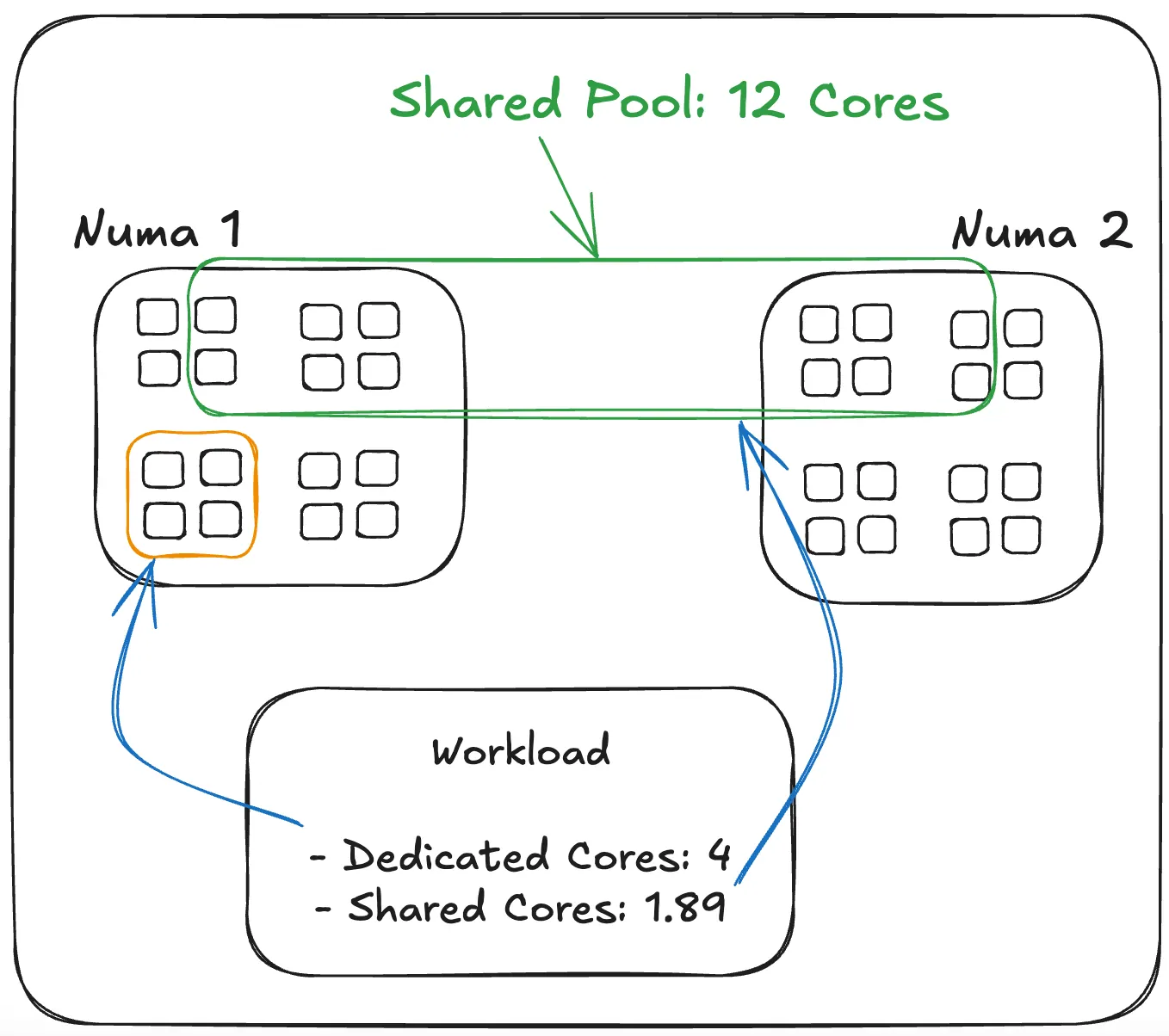
Figure 2. NUMA-aware dedicated and shared cores allocation on the host level.
One of the most impactful features we’ve built is in-place vertical scaling on the host level. This is especially important for our stateful fleet, where workloads run on local disks. Moving a workload to another host means copying all of its data, which is both slow and disruptive.
With in-place CPU autoscaling, we can right-size resources on the fly, without relocating workloads. This reduces churn across the fleet and makes the system more reliable. It’s not entirely seamless—some workloads still need a restart to pick up new CPU limits—but even then, it’s far less costly than moving them to a different host.
In practice, this hybrid approach allows Odin to efficiently use CPU resources, balance load across the system, and maintain stability even under varying workload demands.
Behind the Scenes: How Vertical Scaling Decides on the Number of Cores
The scaler decides how many CPUs each workload gets by looking at two things: the average CPU usage for dedicated cores and the deviation from that average for shared cores. This means dedicated CPUs are sized for steady demand, while shared CPUs are there to handle occasional bursts.
There’s a more complex calculation that determines the total shared CPU pool for each host. Overall, the sum of all shared CPUs allocated to workloads is usually greater than the total shared CPUs available on a host. During contention, cpu.shares is set proportionally so each workload gets a fair slice of the host’s shared CPU pool. While this can still fall short if multiple spikes happen simultaneously, it’s rare enough that the system can tolerate it. More details will be provided in a separate blog post.
Bridging Kubernetes Gaps for Odin
We are aligning Odin with cloud-native patterns and standards where feasible, a move that brings both architectural changes and paradigm shifts. One key challenge is host-level support. Today, Kubernetes® lacks built-in support for hybrid core allocation—a feature that has become essential for Odin’s efficiency and reliability. To bridge this gap, we factored out our cgroups management code into a standalone library. This library is then wrapped into a Kubernetes CRI plugin, ensuring Odin can adopt Kubernetes without sacrificing host-level efficiency.
Limitations of the Current Solution
As shown, all CPU allocation decisions are currently made at the host level. This could be improved by moving the decision-making to a higher level—the workload scheduler—which has a cross-host view of the entire fleet.
Another consideration is CPU allocation fragmentation, which can occur over time after multiple workload placements and migrations. To address this, the host agent—odin-agent—could periodically perform a defragmentation pass to optimize CPU allocations.
Conclusion
The introduction of shared cores marks a major step toward smarter CPU resource allocation. By combining dedicated cores for guaranteed performance with shared cores for elastic bursts, we can:
- Reduce overprovisioning for bursty workloads
- Increase overall CPU utilization fleet-wide
- Maintain service-level performance guarantees
This hybrid model aligns with our long-term vision of configuration-free CPU management, making our fleet more adaptive, efficient, and resilient.
Acknowledgments
Cover Photo Attribution: Ivan Shibitov
Kubernetes® and its logo are registered trademarks of The Linux Foundation® in the United States and other countries. No endorsement by The Linux Foundation is implied by the use of these marks.
Linux® is the registered trademark of Linus Torvalds in the U.S. and other countries.
Category
Written by
Alexandr Sudakov
Senior Software Engineer
Working on Odin. Built hybrid CPU, leading cgroups v2 migration and memory optimization.
Ivan Shibitov
Staff Software Engineer
Working on Odin. Leading Remote Storage adoption.
Select your preferred language
-
Products
-
Advertising
Learn more about advertising on Uber. Reach consumers as they go anywhere and get anything.
- Earn Resources for driving and delivering with Uber
- Ride Experiences and information for people on the move
- Eat Ordering meals for delivery is just the beginning with Uber Eats
- Merchants Putting stores within reach of a world of customers
- Business Transforming the way companies move and feed their people
- Health Moving care forward together with medical providers
- Higher Education Enhancing campus transportation
- Transit Expanding the reach of public transportation
-
Advertising
Learn more about advertising on Uber. Reach consumers as they go anywhere and get anything.
-
Company
- Help