Validating Bounding Box Annotations
April 23, 2026
Ritabrata Chakraborty
Software Engineering Intern
Harshith Batchu
Machine Learning Engineer II
Ishan Nigam
Senior Machine Learning Engineer
1+
Introduction
Despite advancements in open-source models, enterprises often require use-case-specific models to solve their unique business challenges. Training these models necessitates high-quality data, which is frequently collected via human annotations. While effective, these annotations often suffer from human errors, which affect model quality.
Uber AI Solutions provides industry-leading data labeling solutions for enterprise customers and plays a crucial role in enabling organizations to annotate data efficiently. To guarantee high-quality data for our clients, we’ve developed several internal technologies. This blog focuses on one such technology: our ML-based bounding box validation system. This process specifically detects and helps resolve labeling errors in bounding boxes in videos, ensuring issues are fixed before submission.
Background
Bounding box annotation in videos is essential for building object trackers, which are core components of ML and robotics systems. These videos are usually very long. To mitigate fatigue during the annotation process, they are typically split into smaller segments, with different operators working on each. The segments are then joined post-annotation. However, this split and merge is a potential source of errors.
The reliance on human annotators inherently leads to mistakes. While traditional approaches mitigate this through an edit-review workflow, where a second operator reviews the first’s work, this process remains susceptible to human inconsistency. Furthermore, a review step significantly increases both annotation cost (due to two people working on each sample) and total time (due to the sequential nature of the steps).
To address these challenges, we’ve developed a real-time ML-based in-tool and post-annotation validation system for video bounding box annotations which runs in our in-house labeling tool, uLabel. This system enhances data quality by providing automated outlier detection with confidence scoring, clustering detected errors into actionable groups for human review.
This system is designed to catch critical annotation errors, including:
- ID swaps: A tracker incorrectly shifts to a different object.
- Position jumps: Sudden, uncharacteristic coordinate shifts.
- Freeze errors: The bounding box stalls while the tracked object continues to move.
- Scale/aspect distortions: Incorrect dimensions for the bounding box.
In the current iteration, we prioritize the first two error types (ID swaps and position jumps) as they represent the most common and impactful annotation failures. Support for freeze errors and scale distortions is planned for future releases.
Why This Is a Hard Problem
Detecting tracking errors is more nuanced than it appears. What constitutes an anomaly in one video can be perfectly normal behavior in another. What qualifies as an error changes depending on the object, the camera, the scene, and even the frame rate, as we describe below.
- Object size. A 10-pixel coordinate shift on a vehicle spanning half the frame is invisible noise. The same 10-pixel shift on a tiny distant pedestrian moves the box completely off-target. There’s no universal threshold for what’s suspicious—the system has to interpret movements relative to the object’s own scale.
- Object motion. A fast-moving athlete naturally shifts over 50 pixels per frame. A parked car shifts zero. The same coordinate change is perfectly normal in one case and a clear error in the other. Worse, objects can switch behavior mid-track: a person walks, stops, then suddenly runs, so even per-object averages aren’t reliable.
- Camera motion. When the camera is mounted on a moving vehicle or a drone, every bounding box in the frame shifts between frames, even for stationary objects. These shifts look identical to position-jump errors, and the system has no direct way of knowing if the camera has moved. Handheld footage introduces jitter that affects all objects simultaneously.
- Scene complexity. In simple scenes with a single object, errors stand out clearly. In crowded scenes, when two people walk past each other and the tracker swaps their IDs, the bounding box might only move a few pixels because the people were close together. These subtle swaps are both the hardest to catch and the most common in real annotation workflows.
- Visual conditions. Comparing what’s inside a bounding box across frames is a strong error signal, until you’re dealing with low-light footage, thermal imagery, or a fleet of identical-looking objects. In these cases, visual content looks the same regardless of whether an error occurred, and the system needs to fall back on motion and geometric signals instead.
- Frame rate and resolution. A 100-pixel jump between consecutive frames at 30 FPS is almost certainly an error. At 5 FPS, it might be perfectly normal for a fast-moving object. Resolution compounds this on 4K footage, absolute pixel distances are large—on 360p, the same relative movement is just a few pixels.
A validation system that works well on slow-moving vehicles in static camera footage might completely fail on fast-moving pedestrians in a crowded scene captured by a shaky handheld camera. These axes don’t exist in isolation—they combine, and a system must handle the full spectrum without per-scenario tuning. This is precisely why hand-crafted rules like “flag any jump greater than N pixels” fall short. Any fixed threshold will inevitably be too aggressive for challenging scenarios and too lenient for straightforward ones. Our approach needed to generalize across all these axes, detecting errors reliably regardless of object characteristics, motion dynamics, or capture conditions, which is what led us to a learned, data-driven solution.
Architecture
To address these challenges, we designed an end-to-end validation pipeline that takes raw video and annotations as input and produces actionable error clusters as output.
The system is built around four core stages:
- Input processing. The system ingests video frames alongside per-frame bounding box annotations and object IDs. Each tracked object is processed independently through the pipeline.
- Feature extraction. For each object, we compute a rich set of features over a sliding 11-frame window spanning visual, motion, and coordinate signals, producing a multi-dimensional feature vector per frame.
- ML classification. An XGBoost classifier scores each frame with an error probability (0.0 = clean, 1.0 = error), trained on synthetically generated anomalies across diverse scenarios.
- Post-processing and clustering. Raw frame-level predictions are grouped into contiguous error clusters using 2D clustering (frame index × confidence). The result is a set of actionable error regions for human review.
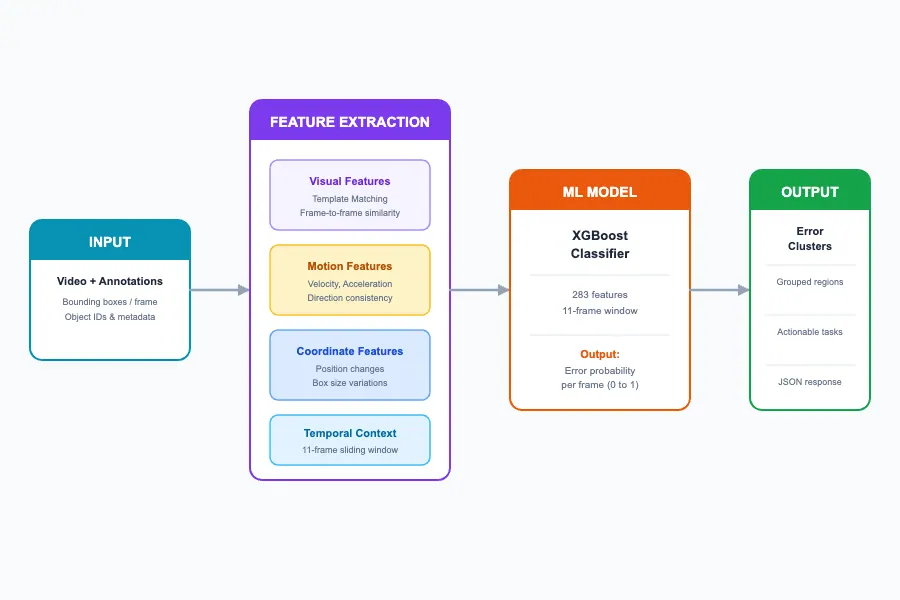
Figure 1: Overview of the validation modeling.
We share details on building our validation system below.
Dataset
Since these errors don’t occur very often, we can’t collect this type of data organically. We generate data where we introduce perturbations to emulate real-world human errors. The data is sourced from 6 open-source datasets to make sure the system works across a diverse range of domains and characteristics including multi-object, autonomous driving, crowded scenes, and unmanned aerial vehicles.
For this iteration, we focus on the two most prevalent error types. We use two perturbation strategies with realistic magnitudes: jump perturbation and ID swap perturbation.
Jump perturbation (50% of anomalies) simulates a tracker snapping to the wrong location with 3 magnitude ranges:
- Small (2-8% of image): around 20-80px on 1080p (50% weight)
- Medium (8-15% of image): around 80-150px (35% weight)
- Large (15-30% of image): around 150-300px (15% weight)
It applies the translation at the error frame and propagates forward.
ID swap perturbation (50% of anomalies) simulates a tracker jumping to a different object. For multi-object tracking (MOT) datasets, it uses nearby object bounding boxes (realistic). For SOT datasets, it generates a random location at a realistic distance (5-30% of the frame). Both perturbations modify only coordinates, leaving frames unchanged (a realistic tracking failure simulation).
The labels that are created per frame are based on these perturbations:
- Label = 0 for the original unmodified tracking sequences.
- Label = 1 for anomaly samples. Clean sequences with perturbations applied at specific temporal positions.
Features
Our model learns to detect tracking errors by analyzing multiple complementary signals from the video data. We categorize our features into three main groups: visual features, motion features, and coordinate features.
Visual features capture what’s inside the bounding box and whether the visual content changes unexpectedly. For template matching, we compare the image content within the bounding box against the previous frame. A high similarity score indicates the tracker is following the same object. A sudden drop suggests the tracker may have jumped to something else entirely.
Motion features analyze how the bounding box moves over time, capturing the dynamics of object motion, including:
- Velocity and acceleration: How fast is the object moving, and is the motion smooth or erratic?
- Direction consistency: Is the object maintaining a consistent trajectory, or did it suddenly change course?
- Aspect ratio changes: Is the bounding box shape staying consistent, or is it distorting unnaturally?
- Edge proximity: How close is the object to the frame boundaries? This helps distinguish legitimate exits from tracking failures.
Coordinate features measure raw changes in bounding box position and size. Frame-to-frame differencing captures the magnitude of coordinate changes between consecutive frames. Large, sudden jumps often indicate tracking errors.
The complete feature set includes additional proprietary signals. These details are omitted for confidentiality.
Temporal Context
Rather than analyzing frames in isolation, we examine an 11-frame sliding window centered on each frame. This allows the model to understand:
- Whether current motion is consistent with recent history
- Statistical patterns like variance and trends
- The context needed to distinguish real motion from tracking artifacts
Model
We frame the problem as a classification task and use the XGBoost (Extreme Gradient Boosting) model. We made this choice for several reasons. First, it handles heterogeneous features well. Our feature set combines visual similarity scores, motion vectors, and statistical aggregations—XGBoost excels at learning from such mixed inputs. Second, it offers fast inference. Production latency matters. XGBoost provides rapid predictions suitable for real-time validation workflows. Finally, XGBoost consistently performs well on tabular/structured data problems.
Design
Once the operators finish their annotations in uLabel and hit the Submit button, we run these validations and flag any issues. The operators have the option to fix our suggestions and re-run the workflow or dismiss our suggestions in case the model is wrong.
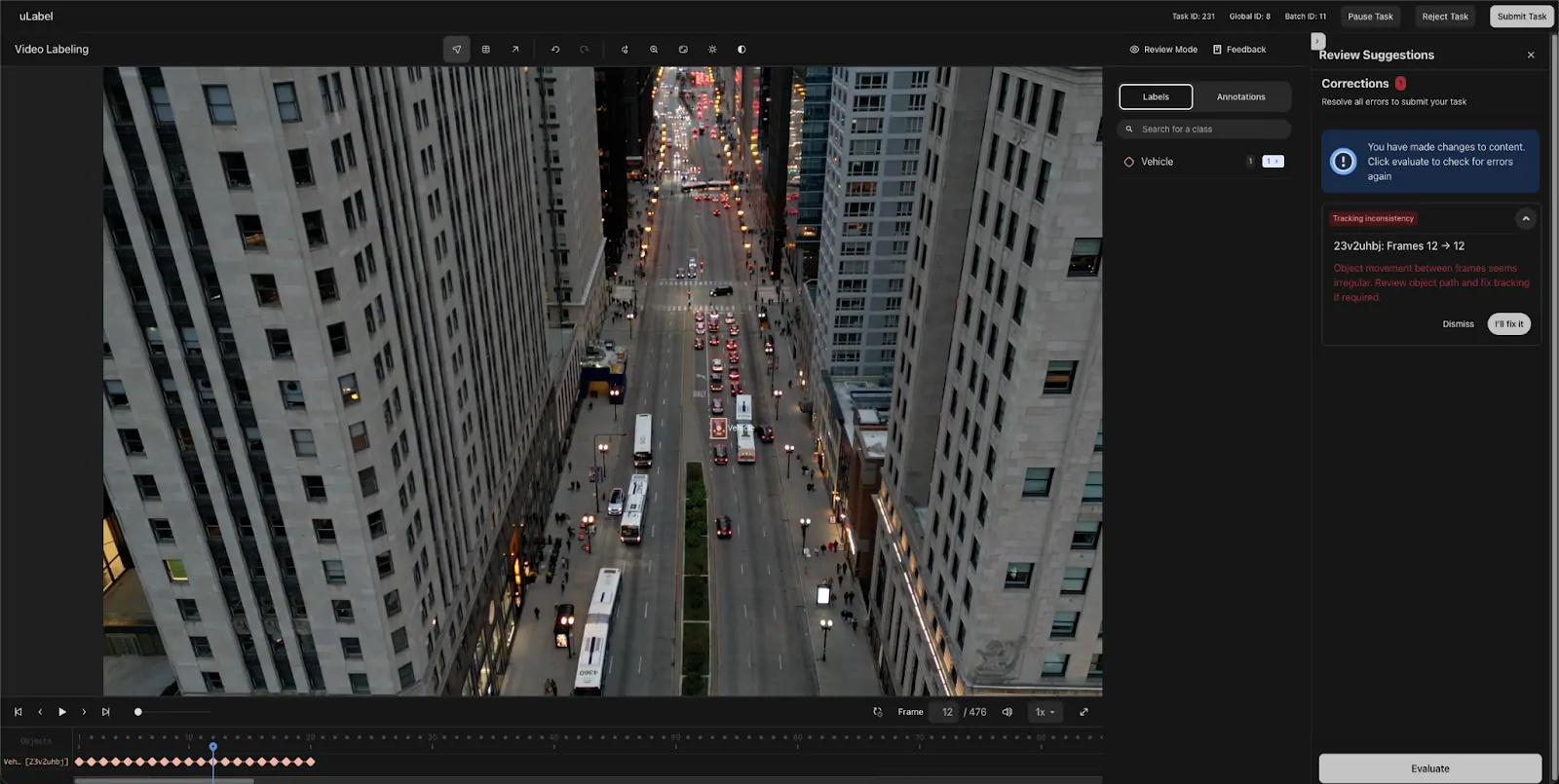
Figure 2: Example of a validation running in uLabel.
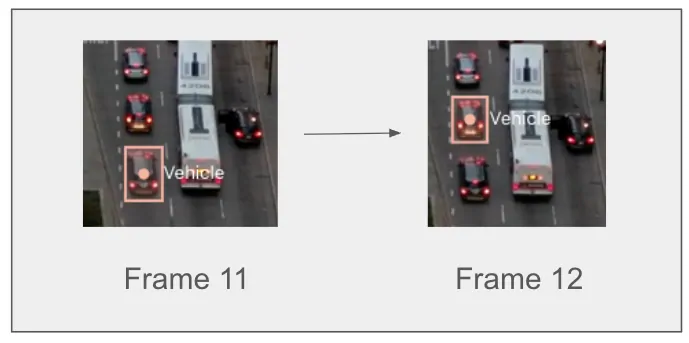
Figure 3: Visualization of the ID swap error above.
The solution is currently deployed and active across all our bounding box annotation projects, immediately improving data quality. We’re working on expanding this deployment to cover other frequent error types and on adding features to further enhance detection accuracy.
Conclusion
Our ML-based validation system for video bounding box annotations marks a significant step forward in ensuring high-quality training data for object tracking models. This automated approach enhances data quality, streamlines the traditionally labor-intensive edit-review workflow, and is already actively deployed across our bounding box projects, immediately contributing to more robust and accurate machine learning and robotics systems.
Data Privacy
We ensure that no data from the client is retained or used to train the models. All the interactions with the model are designed to be stateless and to process data in a privacy-preserving manner, without compromising the integrity or confidentiality of the information.
Acknowledgments
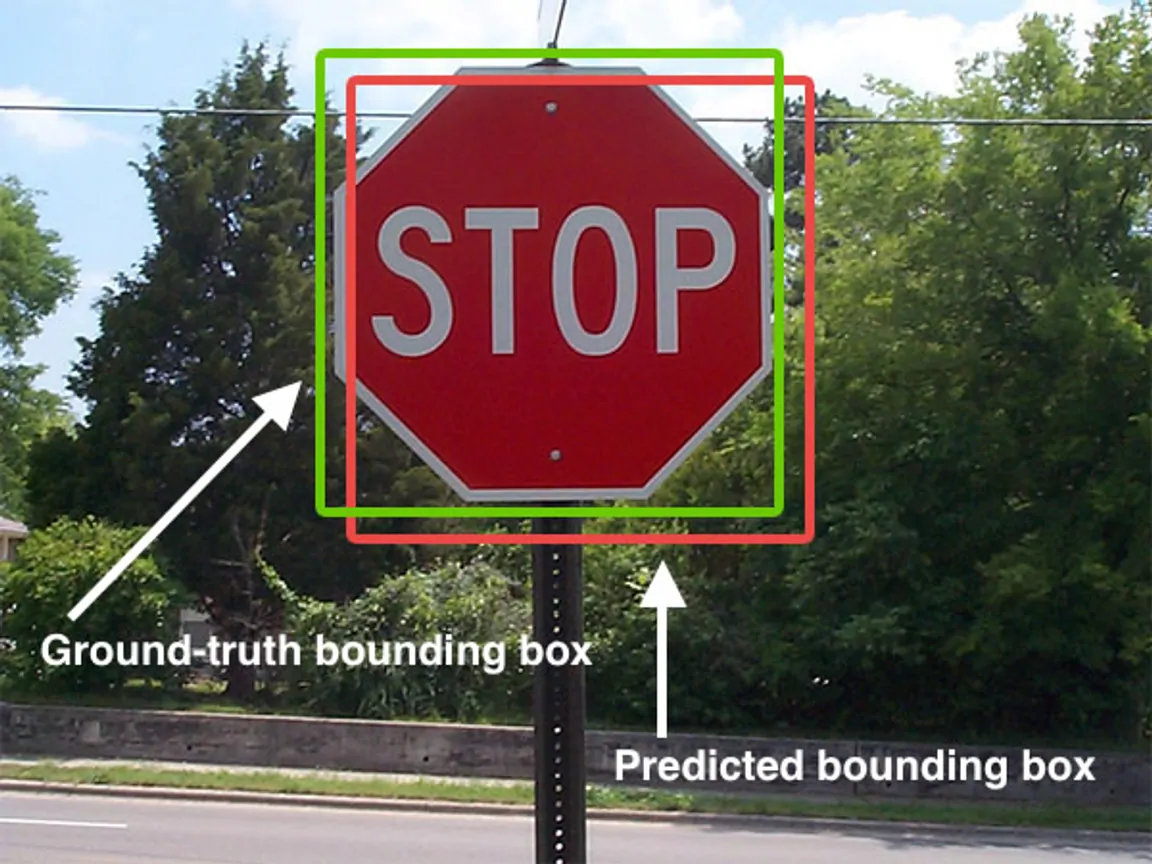
Cover photo attribution: “Intersection over Union - object detection bounding boxes” by Adrian Rosebrock is licensed under CC BY-SA 4.0 via Wikimedia Commons.
Stay up to date with the latest from Uber Engineering—follow us on LinkedIn for our newest blog posts and insights.
Written by
Ritabrata Chakraborty
Software Engineering Intern
Contributed to the development of validation systems for uLabel.
Harshith Batchu
Machine Learning Engineer II
He is building physical AI (vision) for Uber AI Solutions.
Ishan Nigam
Senior Machine Learning Engineer
At Uber AI Solutions, Ishan builds AI-in-the-loop systems to improve human decision-making.
Siddarth Reddy Malreddy
Siddarth is a Staff AI Engineer, TLM based out of Hyderabad. He leads the development of key AI and machine learning initiatives for Uber AI Solutions.

Backend
Engineering
How Ansible® Automation Powers the Uber Corporate Network at a Global Scale
April 30, 2026

Promotions
「店頭価格オファーキャンペーン」対象店舗とキャンペーン詳細について
April 27, 2026

Transit
Next-gen transit: Votran’s innovative model for multimodal partnership
April 27, 2026

Transit
Introducing the $1M Uber Transit Innovation Fund
April 27, 2026

Backend
Engineering
Hybrid Core Allocation: From Overallocation to Reliable Sharing
April 21, 2026

Backend
Engineering
April 21, 2026

Data / ML
Engineering
Uber AI
Next-Gen Restaurant Recommendation with Generative Modeling and Real-Time Features
April 17, 2026

Higher Education
Introducing HoosierShare, Indiana University’s innovative program with Uber
April 15, 2026

Data / ML
Engineering
Uber AI
Evolution and Scale of Uber’s Delivery Search Platform
April 15, 2026

Engineering
Uber AI
Open Source and In-House: How Uber Optimizes LLM Training
April 15, 2026

Engineering
Uber AI
Innovative Recommendation Applications Using Two Tower Embeddings at Uber
April 15, 2026

Backend
Engineering
Accelerating Search and Ingestion with High-Performance gRPC™ in OpenSearch™
April 14, 2026
Prev
1
Select your preferred language
-
Products
-
Advertising
Learn more about advertising on Uber. Reach consumers as they go anywhere and get anything.
- Earn Resources for driving and delivering with Uber
- Ride Experiences and information for people on the move
- Eat Ordering meals for delivery is just the beginning with Uber Eats
- Merchants Putting stores within reach of a world of customers
- Business Transforming the way companies move and feed their people
- Health Moving care forward together with medical providers
- Higher Education Enhancing campus transportation
- Transit Expanding the reach of public transportation
-
Advertising
Learn more about advertising on Uber. Reach consumers as they go anywhere and get anything.
-
Company
- Help