Establishing a Large Scale Learned Retrieval System at Pinterest
Bowen Deng | Machine Learning Engineer, Homefeed Candidate Generation; Zhibo Fan | Machine Learning Engineer, Homefeed Candidate Generation; Dafang He | Machine Learning Engineer, Homefeed Relevance; Ying Huang | Machine Learning Engineer, Curation; Raymond Hsu | Engineering Manager, Homefeed CG Product Enablement; James Li | Engineering Manager, Homefeed Candidate Generation; Dylan Wang | Director, Homefeed Relevance; Jay Adams | Principal Engineer, Pinner Curation & Growth
Introduction
At Pinterest, our mission is to bring everyone the inspiration to create a life they love. Finding the right content online and serving the right audience plays a key role in this mission. Modern large-scale recommendation systems usually include multiple stages where retrieval aims at retrieving candidates from billions of candidate pools, and ranking predicts which item a user tends to engage from the trimmed candidate set retrieved from early stages [2]. Fig 1 illustrates a general multi-stage recommendation funnel design in Pinterest.

Fig 1. General multi-stage recommendation system design in Pinterest. We retrieve candidates from billions of Pin content corpus and narrow it down to thousands of candidates for the ranking model to score and finally generate the feeds for Pinners. “CG” is short for candidate generation and “LWS” is short for Light-weight Scoring, which is our pre-ranking model.
The Pinterest ranking model is a powerful transformer based model learned from a raw user engagement sequence with a mixed device serving [3]. It is powerful at capturing users’ long and short term engagement and gives instant predictions. However, Pinterest’s retrieval system in the past differs, as many of them are based on heuristic approaches such as those based on Pin-Board graphs or user-followed interests. This work illustrates our effort in successfully building Pinterest an internal embedding-based retrieval system for organic content learned purely from logged user engagement events and serves in production. We have deployed our system for homefeed as well as notification.
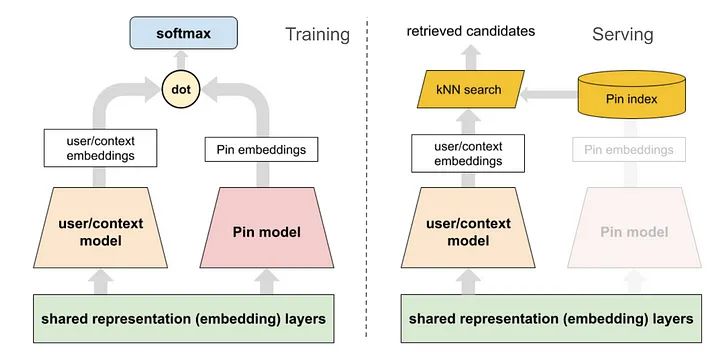
Fig. 2. Two Tower Models for Training and Serving.
Methods
A two tower-based approach has been widely adopted in industry [6], where one tower learns the query embedding and one tower learns the item embedding. The online serving will be cheap with nearest neighbor search with query embedding and item embeddings. This section illustrates the current machine learning design of the two-tower machine learning model for learned retrieval at Pinterest.
The general two-tower model architecture with training objective and serving illustration is in diagram Fig 2.
For training an efficient retrieval model, many works model it as an extreme multi-class classification problem. While in practice we can not do softmax over all item corpus, we can easily leverage in batch negative, which provides a memory efficient way of sampling negative. To put it more formally, a retrieval model should optimize where C is the entire corpus and T is all true labels.


However, in practice we can only sample softmax over a set of negative items S.
![]()
Where given a sampled set D, and the sampled softmax could be formulated as:

As we sample items from our training set that might have popularity bias, it is important for us to correct the sample probability [1]. We use simple logic tuning based on the estimated probability for each item.
𝐿⟮user, item⟯ = 𝒆user · 𝒆item - log P⟮item is in the batch⟯
Where 𝒆user , 𝒆item are the user embedding and item embedding correspondingly.
In our model design, we encode user long-term engagement [11] , user profile, and context as input [2] in the user tower (as shown later in Fig 4).

Fig 3. User sequence modeling in two-tower architecture. PinnerSage [11] encodes long-term user representations while user realtime user sequence modeled with sequence transformer make the model able to capture instant user intention.
System Designs
As Pinterest serves over 500 million MAUs, designing and implementing an ANN-based retrieval system is not trivial. At Pinterest, we have our in-house ANN serving system designed based on algorithms [5, 7]. In order to be able to serve the item embeddings online, we break it down into two pieces: online serving and offline indexing. In online serving, user embedding is computed during request time so it can leverage the most up-to-date features to do personalized retrieval. In offline indexing, millions of item embeddings are computed and pushed to our in-house Manas serving system for online serving. Fig. 4 illustrates the system architecture for embedding-based retrieval with auto retraining adopted.

Fig 4. Full Serving Pipeline of Learned Retrieval with Auto Retraining
Auto Retraining
In a real-world recommendation system, it’s a necessity to frequently retrain the models to refresh the learned knowledge of users and capture recent trends. We established an auto retraining workflow to retrain the models periodically and validate the model performance before deploying them to the model and indexing services.
However, different from ranking models, two-tower models are split into two model artifacts and deployed to separate services. When a new model is retrained, we need to ensure that the serving model version is synchronized between the two services. If we do not consider version synchronization, due to the difference in deployment speed (where usually the Pin indexing pipeline takes much longer time than the viewer model being ready), candidate quality will drastically drop if the embedding space is mismatched. From the infrastructure perspective, any rollback on either service will be detrimental. Moreover, when a new index is built and being rolled out to production, the hosts of ANN search service will not change altogether immediately; this ensures that during the rollout period, a certain percentage of the traffic won’t suffer from model version mismatch.
To tackle the problem, we attach a piece of model version metadata to each ANN search service host, which contains a mapping from model name to the latest model version. The metadata is generated together with the index. At serving time, homefeed backend will first get the version metadata from its assigned ANN service host and use the model of the corresponding version to get the user embeddings. This ensures “anytime” model version synchronization: even if some ANN hosts have model versions N and others have versions N+1 during the index rollout period, the model version is still synchronized. In addition, to ensure rollback capability, we keep the latest N versions of the viewer model so that we can still compute the user embeddings from the right model even if the ANN service is rolled back to its last build.
Experiment and Results
Homefeed in Pinterest is probably the most complicated system that needs to retrieve items for different cases: Pinner engagement, content exploration, interest diversification, etc. It has over 20 candidate generators served in production with different retrieval strategies. Currently the learned retrieval candidate generator aims for driving user engagement. It has the top user coverage and top three save rates. Since launched, it has helped deprecate two other candidate generators with huge overall site engagement wins.
Conclusion and Future Works
In this blog, we presented our work in building our learned retrieval system across different surfaces in Pinterest. The machine learning based approach enables us for fast feature iteration and further consolidates our system.
Acknowledgement
We would like to thank all of our collaborators across Pinterest. Zhaohui Wu, Yuxiang Wang, Tingting Zhu, Andrew Zhai, Chantat Eksombatchai, Haoyu Chen, Nikil Pancha, Xinyuan Gui, Hedi Xia, Jianjun Hu, Daniel Liu, Shenglan Huang, Dhruvil Badani, Liang Zhang, Weiran Li, Haibin Xie, Yaonan Huang, Keyi Chen, Tim Koh, Tang Li, Jian Wang, Zheng Liu, Chen Yang, Laksh Bhasin, Xiao Yang, Anna Kiyantseva, Jiacheng Hong.
References:
[1] On the Effectiveness of Sampled Softmax Loss for Item Recommendation
[2] Deep Neural Networks for YouTube Recommendations
[3] Transact: Transformer-based realtime user action model for recommendation at pinterest
[4] Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time
[5] Manas HNSW Streaming Filters
[6] Pinterest Home Feed Unified Lightweight Scoring: A Two-tower Approach
[8] Sample Selection Bias Correction Theory
[9] PinnerFormer: Sequence Modeling for User Representation at Pinterest