Eval-driven development: Build better AI faster
A look at Vercel's philosophy and techniques in AI-native development.
AI changes how we build software. In combination with developers, it creates a positive feedback loop where we can achieve better results faster.
However, traditional testing methods don't work well with AI's unpredictable nature. As we've been building AI products at Vercel, including v0, we've needed a new approach: eval-driven development.
This article explores the ins and outs of evals and their positive impact on AI-native development.
Evals: The new testing paradigm
Evaluations (evals) are like end-to-end tests for AI and other probabilistic systems. They assess output quality against defined criteria using automated checks, human judgment, and AI-assisted grading. This approach recognizes inherent variability and measures overall performance—not individual code paths.

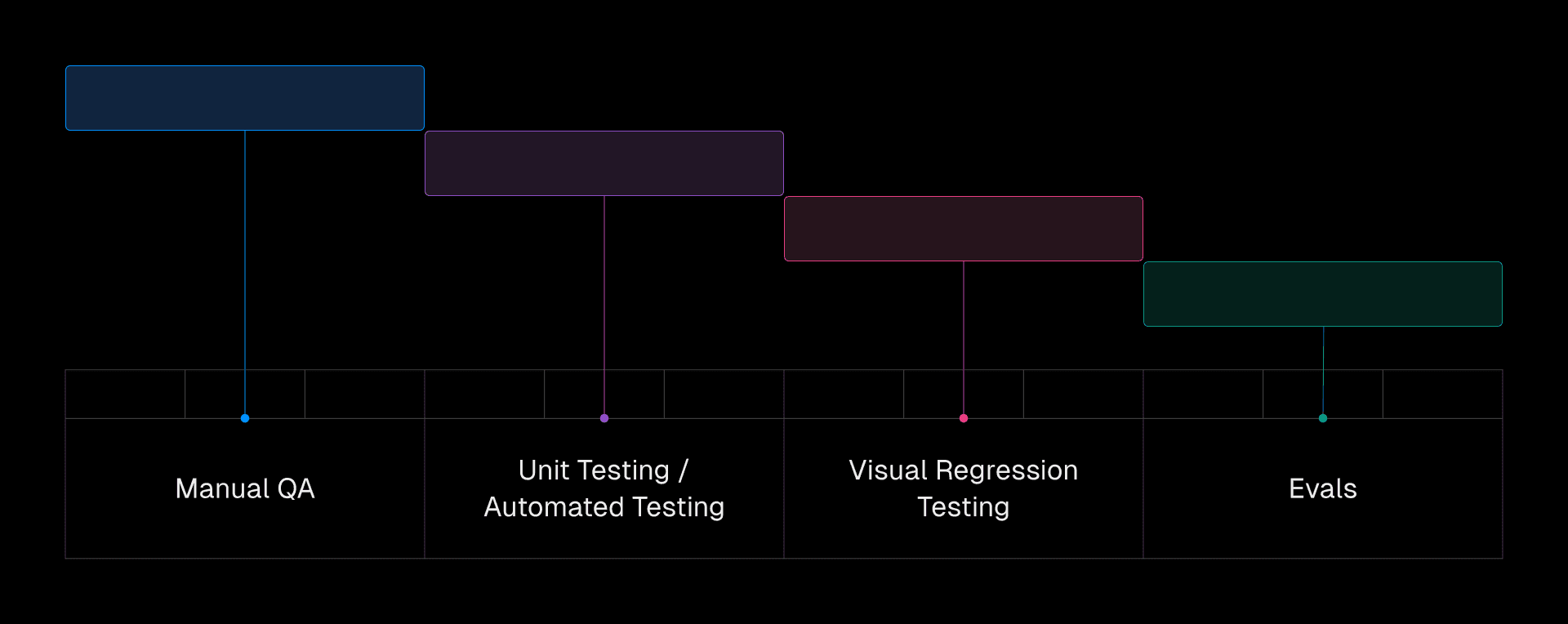
Evals complement your existing test suite.
There are three primary types of evals:
-
Code-based grading: Automated checks that use code are ideal for objective criteria and fast feedback. For example, you can check if AI output contains a specific keyword or matches a regular expression. Unfortunately, you can’t code every type of eval
-
Human grading: Leveraging human judgment for subjective evaluations is essential for nuanced assessments of quality and creativity. This is particularly useful for evaluating the clarity, coherence, and overall effectiveness of generated text
-
LLM-based grading: Using other AI models to assess the output offers scalability for complex judgments. While potentially less reliable than human grading, this approach is more cost-effective and efficient for large-scale evaluations. Note that LLM evals still cost 1.5x to 2x more than code-based grading
From deterministic to probabilistic
So, why do we need evals?
With defined inputs, code produces predictable outputs: two plus two always equals four. Developers can use unit and automated testing to ensure quality.
LLMs, however, introduce probabilistic behavior. They operate as black boxes, making their responses difficult to predict. It's less like "two plus two" and more like predicting tomorrow's weather.
That's where evals come in. By adopting a framework that emphasizes continuous evaluation and refinement of non-deterministic outputs, developers can effectively use variable AI systems without compromising quality, reliability, and observability.
Lessons from search engines
This shift—from tests to evals—echoes challenges faced by web search engineers over the past two decades. Dealing with the web's vastness and unpredictable user queries, they recognized early on that exhaustive, hard-coded testing wasn't feasible.
Search quality teams adapted by using eval-centric processes, acknowledging that any change could bring improvements and regressions. While slower and more subjective than traditional testing, this eval-driven approach was most effective for improving search quality in a complex, non-deterministic environment.
Eval example: Generating a React component
Let's look at an example: Imagine building an AI assistant that helps developers write React components based on user descriptions. How would you evaluate the output?
System prompt: Generate a React functional component (arrow function) that displays a list of items. The component should accept an array of strings as props and render each string as a list item. Style the list using Tailwind CSS.
User: Create a component called ItemList that takes an array of item names and displays them in an unordered list. Each item should be displayed in bold font.
Expected:
import React from "react";const ItemList = ({ items }) => ( <ul className="list-none p-0"> {items.map((item, index) => ( <li key={index} className="font-bold">
Actual:
import React from "react";function ItemList(props) { {props.items.map((item) => ( <li style={{ fontWeight: "bold" }}>{item}</li>
In this example, the AI-generated code is functional but deviates from the expected, opinionated output.
-
Styling: The expected output uses Tailwind CSS classes (
list-none p-0,font-bold), but the actual output uses inline styles -
Key prop: The expected output correctly includes the
keyprop for list items, but the actual output omits this -
Component definition: The expected output uses an arrow function component, but the actual output uses a traditional function component
Evals assess not only basic functionality but also code quality, style, and adherence to arbitrary best practices. These differences can be subtle, but evals provide a mechanism for quantifying and addressing them.
For example, we could detect these nuances with:
-
Code-based grading: Regex for inline styles vs. Tailwind classes, or checking for the presence of
keyprops -
Human grading: A domain expert or end user looks at the generated code and presses a thumb up or down, optionally providing comments
-
LLM-based grading: Training a small model to compare the generated code against the expected output
Most importantly, any of these methods should provide a clear score across the domains you wish to evaluate. This makes it easy to tell whether the AI is improving or regressing on these criteria.
This analysis can then inform further fine-tuning and refinement of the model, leading to more reliable AI generation. And this is where evals become much more powerful.
The AI-native flywheel
Evals aren't just a replacement for traditional tests. In combination with high-quality data, great models and strategies, and user feedback, they become the engine of a new development cycle that we like to call the AI-native flywheel.

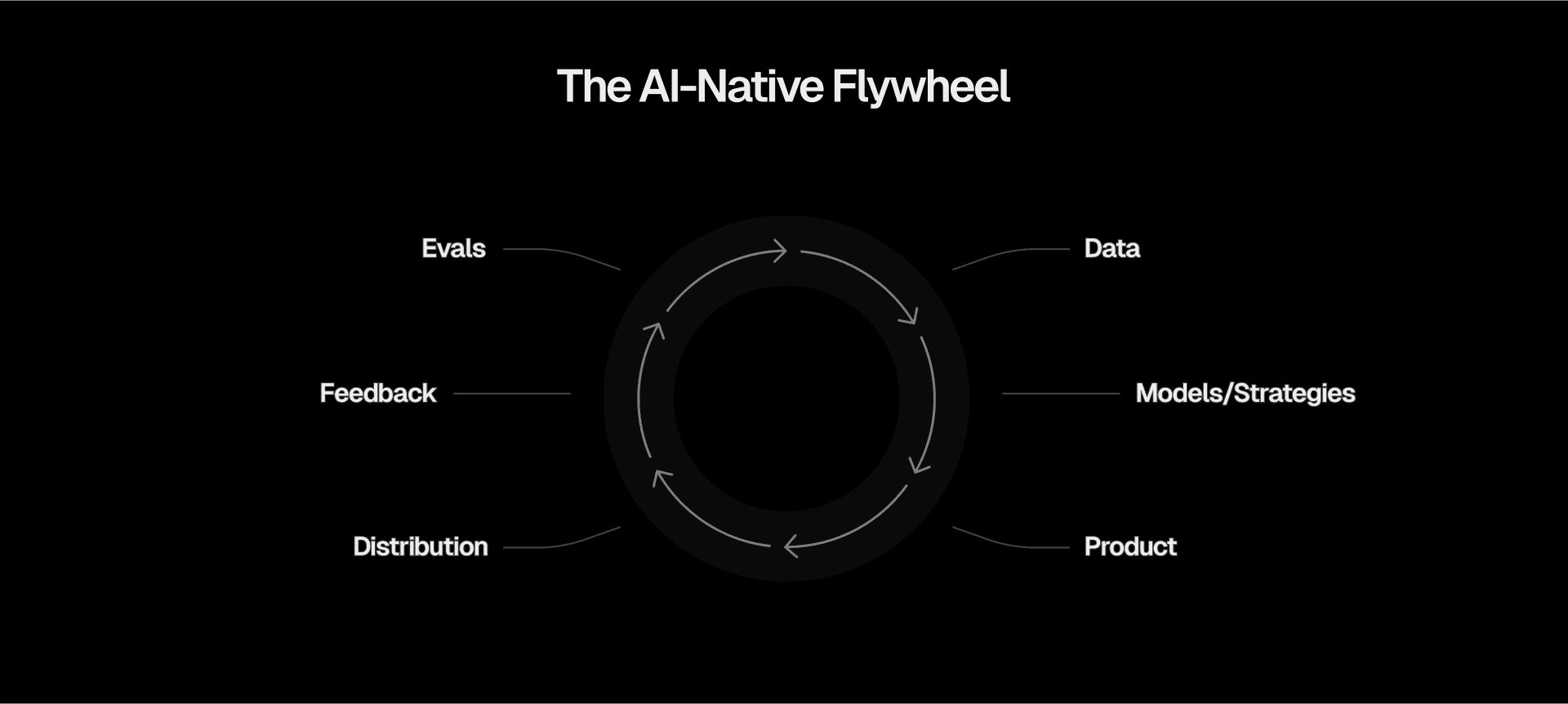
This positive feedback loop accelerates development and ensures your AI systems consistently improve. With it, you can use AI in more and more places to further improve processes.
Evals
Evals are the foundation of AI development. They give you critical feedback about the strengths and weaknesses of your AI, replacing gut feelings with data-driven decisions and guiding your development process.
Effectively using and keeping track of your evals, however, is a whole other challenge. Methods can often be ad-hoc, relying on manual review or generic benchmarks. This doesn't scale well and lacks the specificity needed for targeted improvements.
You can use tools like Braintrust to enable automated evaluations based on LLM evaluators, heuristics, and comparative analysis. It can help you integrate real-world feedback loops, incorporating production logs and user interactions into the evaluation data.
Data
Robust evals are also key to pinpointing data gaps and target your data collection efforts. High-quality data fuels effective AI; garbage in, garbage out still applies. With golden data, you gain leverage for better fine-tuning and post-training techniques, improving overall system performance.
Every new data source requires appropriate evals to ensure the AI effectively uses it without hallucinations or other issues.
Models and strategies
The AI landscape changes daily with new models and research. Evals can help you navigate this by enabling rapid testing of different models and strategies against your defined criteria.
This allows you to identify the optimal combination of model, data augmentation, and prompting techniques for the best accuracy, performance, and cost-effectiveness.
Note that the AI SDK (npm i ai), with its unified, type-safe abstraction layer, can simplify this process by allowing you to quickly switch between different providers and models with minimal code changes.
Feedback
Diverse feedback is crucial for continuous optimization. Direct, in-product feedback from real users gives you a clear look at how your AI performs in real-world scenarios. Consider these approaches:
-
Explicit feedback: Let users directly rate or review your AI's output. This could be a simple thumbs-up/thumbs-down, a star rating, or a detailed feedback form
-
Implicit feedback: Track user behavior with your AI-powered features. For example, if users consistently rephrase or abandon queries, it might indicate issues with the AI's understanding
-
Error reporting: Implement robust error reporting to capture and analyze unexpected behavior. This helps identify and address bugs or limitations in your AI
Combining these feedback types gives you a comprehensive understanding of your AI's strengths and weaknesses from a user's perspective. This feedback, fed directly into your evals, creates a continuous improvement cycle, driving the flywheel and ensuring your AI product constantly evolves.
Vercel's v0: Eval-driven development in practice
Our flagship AI product, v0, is built on eval-driven development. Our multi-faceted evaluation strategy includes fast, reliable code checks, end user and internal human feedback, and LLM-based grading for complex judgments at scale. All this feedback pours back into evals.
This catches errors early, speeds up iteration, and drives continuous improvement based on real-world feedback. We iterate on prompts almost daily. Evals prevent regressions and ensure accurate source matching when updating RAG content.
v0 allows you to generate user interfaces from text. Evals help us constantly improve the functionality, aesthetic, and efficiency of the code. (Generation sped up for demonstration.)
v0 allows you to generate user interfaces from text. Evals help us constantly improve the functionality, aesthetic, and efficiency of the code. (Generation sped up for demonstration.)
We prioritize refusal and safety evals, maintaining a 100% pass rate. While not all evals currently pass, we add new, failing prompts to the eval set for continuous improvement. When we add features like Vue or Python support, accompanying evals guarantee quality. Internal dogfooding provides invaluable feedback, helping us identify areas for improvement.
Code-based grading is particularly effective. Some of our checks for code quality include:
-
Validating code blocks
-
Ensuring correct imports
-
Confirming multi-file usage
-
Verifying the balance of code comments versus actual code (correcting LLM laziness)
An automated script runs the entire eval test suite and reports pass/fail rates, regressions, and improvements. Braintrust logs everything for manual review. Every GitHub pull request that impacts the output pipeline includes eval results.
Maintaining these evals presents an ongoing challenge and requires updates as the AI system evolves. We continue to look for ways to make managing the eval suite less time-consuming and more scalable, without totally giving up the human-in-the-loop.
The future of AI-native development
Eval-driven development is the foundation for building robust and innovative AI software. It empowers you to harness AI's potential without compromising quality, control, or user-centric design.
The AI-native flywheel, with its continuous feedback loop, helps you navigate AI's complexities, iterate rapidly, and continuously improve. This process, combined with robust evaluation and a focus on UX, is key to creating intelligent and valuable applications.
[
Bring any questions.
Our engineers can recommend ways to build out scalable AI infrastructure from your existing codebase.