Improving Efficiency Of Goku Time Series Database at Pinterest (Part — 1)
Monil Mukesh Sanghavi, Kapil Bajaj, Ming-May Hu, Xiao Li and Zhenxiao Luo
Introduction
At Pinterest, one of the pillars of the observability stack provides internal engineering teams (our users) the opportunity to monitor their services using metrics data and set up alerting on it. Goku is our in-house time series database providing cost efficient and low latency storage for metrics data. Underneath, Goku is not a single cluster but a collection of sub-service components including:
- Goku Short Term (in-memory storage for the last 24 hours of data and referred to as GokuS)
- Goku Long Term (ssd and hdd based storage for older data and referred to as GokuL)
- Goku Compactor (time series data aggregation and conversion engine)
- Goku Root (smart query routing)
You can read more about these components in the blog posts on GokuS Storage, GokuL (long term) storage, and Cost Savings on Goku, but a lot has changed in Goku since those were written. We have implemented multiple features that increased the efficiency of Goku and improved the user experience. In this 3 part blog post series, we will cover the efficiency improvements in 3 major aspects:
- Improving recovery time of both GokuS and GokuL (this is the total time a single host or cluster in Goku takes to come up and start serving time series queries)
- Improving query experience in Goku by lowering latencies of expensive and high cardinality queries
- Reducing the overall cost of Goku in Pinterest
We’ll also share some learnings and takeaways from using Goku for storing metrics at Pinterest.
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components.
Initial Architecture For Goku Short Term Ingestion

Figure 1: Old push based ingestion pipeline into GokuS
At Pinterest, we have a sidecar metrics agent running on every host that logs the application system metrics time series data points (metric name, tag value pairs, timestamp and value) into dedicated kafka topics. To learn more about data points, you can look at the Time Series Data Model in this post.
From these kafka topics, an ingestion service would consume the data points and push them into the GokuS cluster(s) with a retry mechanism (via a separate kafka + small ingestion service) to handle failure.

Figure 2: Initial write path in GokuS with EFS as deep persistent store.
GokuS (storage architecture found in this link), which serves the last 1 day of metrics, stores the data in memory. Once the data becomes immutable (i.e. data before the last 2 hours, since GokuS allows only 2 hours of backfill old data in most cases), it stores a copy of the finalized data on AWS EFS (deep persistent storage). It also asynchronously logs the latest data points onto AWS EFS.
During recovery, it reads the finalized data from EFS into memory, then replays the logs from EFS and relies on the retry ingestion service to bring it up to speed with the latest data.
Scaling Issues
This architecture worked for us, but over time as our scale increased, we started seeing a few problems, especially during host replacements or deployments.
Longer Recovery Time

Figure 3: Initial recovery path with EFS
During recovery, a GokuS host reading hits the throughput limits of EFS very easily. We observed a throughput limit of 1024 Megabytes per second (network I/O combined) for the whole cluster/ replica.
To give context, we have around 150–200 hosts on each cluster with close to 80 GB of time series data stored in memory. With a throughput of 1024 Megabytes per second, a read only workload is able to read 60 GB per minute.If multiple hosts were recovering at the same time, we observed that the phase of recovering the finalized data and logs from EFS would sometimes take almost 90 minutes to complete. This would then be followed by the ingestor service pushing the recent data points to the host.The total bootstrap / recovery time for the whole cluster would cross 2 hours. To add to the latency, the retry ingestor service reads the data points from retry kafka, calculates the target shard again, and tries to push data points.

Figure 4: GokuS clusters health determination and query routing the old way
Single Point Of Failure Due To Health Inference at Cluster Level
At Pinterest, we use an internal tool called Statsboard to visualize metrics stored on Goku. Statsboard continuously pushes synthetic metrics to Goku and then reads them to determine its liveness.The synthetic metrics follow the same write/ ingestion path mentioned above and are queried from GokuS clusters. They are used to determine the health of the cluster and for query routing. If the statsboard client is able to read its own generated latest synthetic data point from GokuS cluster, that means the cluster or replica is up to date with the latest data points and is fit for serving queries.
In case of a host replacement or a host running the recovery routine, the statsboard client is not able to read the latest synthetic metrics that were stored on the host. This is because the synthetic data points would be present in the retry kafka waiting to be pushed into the recovering host by the retry ingestor. Thus, the whole cluster would be inferred as unfit for reading until the host completes its recovery, because statsboard does not know which host/ shard is recovering. For a cluster to be fit for querying, it needs to successfully read all the synthetic metrics. This would make the other replica cluster as a single point of failure in such situations.
Ingestion Model Change to Pull Based Shard Aware Ingestion

Figure 5: New pull based ingestion pipeline.
Before we go into the solution, let’s understand what a shard is in GokuS terms. As defined generally, a shard is a logical subset of data used for distributing data across distributed systems. In GokuS terms, a shard is a subset of time series data. How to know which shard a data point belongs to is explained in detail in here the “Sharding and Routing” section. To summarize, there are 2 levels of sharding in GokuS. We 1) hash the metric name (not the tag value pairs) to determine the shard group id, and 2) hash the metric name + tag value pairs to determine the shard id within the group.
A shard group is a logical collection of shards. The concept of shard groups was introduced to confine the queries for a particular metric name to a select set of hosts rather than all hosts in the cluster. For example: if we did not have the concept of a shard group, the query for a metric name (assuming no filters are provided and we have to scan all time series for the metric name) would have to look at all shards in the cluster, and the fan out would be very high. So, we changed the push model of ingestor service pushing the data points into GokuS service to a shard aware pull modeland introduced another kafka topic between the ingestor service and the GokuS storage (calling it Goku side Kafka). The ingestor determines the kafka partition of the datapoint after appropriate hashing and produces to the partition. A very important thing to note here is that partition id in kafka is the same as shard group id * number of shards per shard group + shard id. Hence, for GokuS, a host which hosts a shard x will consume from partition x.

Figure 6: New logging mechanism for fast recovery
We replaced EFS with a local disk (local instance storage) for persistent data and S3 as backup. Since finalized data is written every 2 hours, it was easy to add an additional call to upload to s3 after writing to local instance storage. However, since logs are frequently written, we cannot do the same (append to log file in EFS) for it (i.e. write to s3 on every append). Hence, we decided to async log into local storage and then move the log file into s3 every 20 minutes so that, at most, 20 minutes of logging would be lost per shard if the host was terminated/ replaced.
In GokuS, we also recorded the kafka offset of the logged data points in the log and would commit the offset to Goku side kafka every 20 minutes after the log file was backed up in s3.

Figure 7: Recovery using local disk instance store and S3
During recovery, the host checks the local storage if it has finalized files and the log files for the shard(s). If not, it downloads the files from s3 then recreates the finalized data in memory and replays the logs in memory.
Gains
The recovery time of a single GokuS cluster (replica) was reduced from 90–120 minutes to under 40 minutes with these changes. This can be owed to the recovery from local disk instead of EFS in non host replacement scenarios. Another source of this reduction was no additional computation on the data points to calculate the shard id by the retry ingestor. With additional Goku side kafka and GokuS host directly pulling from respective kafka partitions, this repeated logic was not needed anymore.

Figure 8: New shard health aware query routing
The above changes also provided an added benefit of being able to determine the data lag (kafka consumer lag) at a shard/partition level. We exported this data lag per partition per cluster into shared files and the routing service (Goku Root — more information here) and made use of this information to efficiently route the queries. Previously, statsboard query clients would route the queries based on the generated synthetic metrics, which did not have per shard information. Hence, the cluster would only receive queries once all shards have recovered.But now, the Goku root detects if a shard is ready for queries by simply looking at its lag (shard health based query routing). Thus, the dependency on the statsboard generated synthetic metrics for query routing is removed. Queries start hitting a host as soon as a shard has less than some threshold of kafka lag. This is even if the host was actively recovering data for other shards. This reduced query load on the other replicas as well during deployment.
Goku Long Term Storage Architecture Summary and Challenges

Figure 9: Flow of data from GokuS to GokuL.
GokuL leverages RocksDB for time series data storage, and the data is tiered into buckets based on its age.In short, RocksDB is a key value store that uses a log structure DB engine for storage and retrieval. It writes the key-value pairs in memory and async logs them. Periodically, it flushes the in memory data onto persistent storage, i.e. sorts the key value pairs based on key and stores them into a Static Sorted Table (SST) file. The sorting is for efficient retrieval. It has tiered storage, i.e. keeps compacting smaller recent SST files in lower tiers into larger and older SST files in higher tiers. More information about the architecture can be found in the GokuL blog and the cost reduction blog.
In summary, Goku compactor service prepares SST files (can be multiple ssSSTt files per bucket) for ingestion in GokuL RocksDB instances. It reads GokuS finalized data from S3, processes it (doing roll ups etc), reshards it as per GokuL sharding policy, and writes it to S3. More information about how SST files can be created and ingested can be found here.
GokuL Cluster stores and serves the metrics data that is older than a day. The metrics stored on this cluster have a TTL of 1 year. The below table shows the data tiering strategy and storage clusters. Note that each tier holds a finite number of fixed sized buckets. The bucket in itself is actually nothing but a collection of SST files holding all the time series data and metadata for the corresponding bucket size. The bucket id is unix time divided by bucket size.

When a new host is added to the existing GokuL cluster, it downloads all the relevant SST files from S3 (for all the buckets in different tiers) and ingests it in the RocksDB instance, which we create per shard in GokuL. The ingestion is tier by tier and bucket by bucket. In the GokuL SSD storage cluster, which stores tier 1 to 4 ( every tier has 5–6 buckets) metrics data i.e. data up to 80 days old, any new host would take around 6 to 12 hours to fully bootstrap and be ready for queries. This is due to the fact that each host would hold approximately 100–120 shards. Hence, the total number of buckets ingested would be 100 shards * 4 tiers * 6 buckets, that is 2400 buckets.
Also, each bucket would store different lengths of data. For example a bucket in tier 1 would be 6 hours of data, and a bucket in tier 4 would have 16 days of data. More on the tiering strategy can be found here. Also, the bigger the bucket size, the more tSST files it has.In general, each host would ingest around a couple of 1000s of GB worth of data when it bootstrapped.
Another cause for the slow bootstrap time is that the ingestion competes for CPU resources with rocksdb SST compaction. Compaction is a process that consolidates 2 higher level files into a larger lower level file and also deletes any unwanted keys during this process. Generally, when SSTs are ingested (size-based SST generation), rocksdb decides the best level for storing the SST files. However, we observed compaction starting as soon as SSTs were getting ingested. See the graph below, which shows the compaction read and write bytes on a cluster when it is bootstrapping for the first time.
Figure 10: compaction read and write bytes showing non zero values as soon as host starts up.
This slow bootstrap time was a definite hindrance on our move to less compute heavy instances for cost savings. In fact, the bootstrap time degraded further (to 12 hours), as we noticed in our tests.
RocksDB Bulk Ingestion
We tried the rocksdb bulk ingestion api to ingest all tiers and all buckets at once for any shard and it failed with an overlapping ranges error. We tried ingesting all buckets for the same tier and that failed with the same error again. It could be easily inferred that the SST files could not be sorted in any way during bulk ingestion due to them having overlapping keys (i.e. in (s1, l1) and (s2,l2) where s is start key and l is end key for files 1 and 2, we have s2 < l1 and l2 > l1). The overlapping keys were also the reason for compaction happening as soon as ingestion started because rocksdb would not keep SST files with overlapping keys separate in the same level. However, looking at the GokuL data, there was a logical assumption of keys being sorted (e.g, a bucket).
Goku Long Term Data Format
The GokuL blog post explains in detail the rocksdb key format followed in GokuL.In summary, because our data are tiered and bucketed, when generating these keys, we prepend [magic(1 byte)][tier(1 byte)][bucket(4 bytes)] to every RocksDB key. Magic number is a byte to identify different types of keys like data key, index key, dictionary key, reverse dictionary key, tier marker key, and so on. More details about these key types and what they represent can be found in the blog post link above.
Now assume for simplicity sake that magic characters are ‘A’,’B’,’C’,’D’,’E’ and ‘F’. An SST file in a single bucket in a single tier can contain multiple key types. We also limit the size of each SST file created. We could thus have multiple SST files per bucket. So we would have SST files for a single bucket like the following:
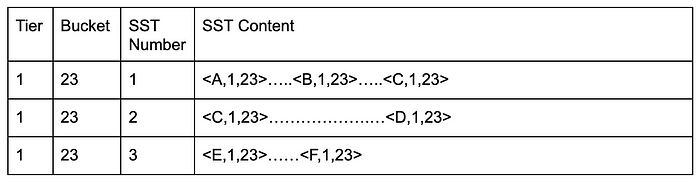
And the second bucket may look like:

If you try to bulk ingest them all together, RocksDB will try to sort the SST files based on the last and first key in each file. However, in the above case, it may never be able to do so because of the magic character and varied nature of the number of keys which could be stored in a single SST file. For example, when it tries to sort all the SSTs lexicographically into a list, SST 1 of bucket 24 would not be able to find the right position in the sorted list of SSTs of both bucket 23 and 24. <A,1,24> needs to be after <A,1,23> but it cannot be inserted in the middle of SST 1 of bucket 23. Similarly, <C,1,24> cannot be inserted after <D,1,23>. Ideally, the sorted pairs should look like this: <A,1,23>…<A,1,24> <B,1,23>….<B,1,24><C,1,23>…<C,1,24> and so on. Thus, bulk ingestion would error out with overlapping ranges errors and compaction would trigger when data is ingested bucket by bucket.
Change in Data Format and Improvement in Bootstrap Times
There were 2 solutions to tackle this:
- Have a separate SST file for each key type
- Store tier and bucket information before the key type
In both cases, we would have to store version information in the name of the SST file, which would be useful while bootstrapping and reading the files. We decided to do the former because the code change was very minimal and the path to production would be fast. The below tables show the SST format changes. V0 is version 0, which is the old SST format, while V1 is version 1 (separate SST for each key type). Note how the SSTs with version v1 in both buckets can easily be sorted and ingested together.

The above changes to the following:
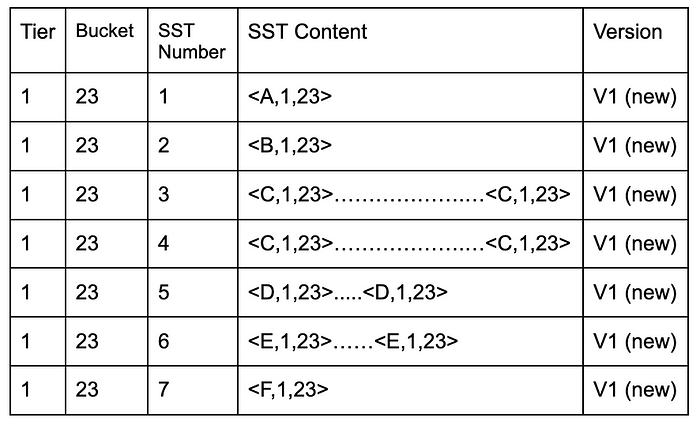
Similarly, this:

Changes to this:

The bootstrap time was reduced to 2 hours (from 6–12 hours) after the change was made to ingest from newly created SST files for each key type. We also observed no compaction during ingestion. For example, the graph below which shows the compaction read-write bytes for a prod cluster vs dev cluster, which has the SST based optimizations running.
Figure 11: compaction read and write bytes showing zero values as soon as dev host starts up in with version 1 SST files.
Future Work
- For GokuS, we want to explore snapshotting the data every hour into the disk to reduce the replaying of the logs and make the bootstrap even faster (maybe reduce from 40 minutes to 10–15 minutes).
- For GokuL, we want to explore using tier and bucket as the prefix for the keys rather than the key type and using DeleteRange for deleting the keys for the whole bucket at once rather than manual compaction for deletion. This would keep the bootstrap time intact with additional benefit of data for the same bucket being close together on ssd.
In part 2, we will discuss how we improved the query experience in Goku using different techniques.
To learn more about engineering at Pinterest, check out the rest of our Engineering Blog and visit our Pinterest Labs site. To explore and apply to open roles, visit our Careers page.