T-LEAF: Taxonomy Learning and EvaluAtion Framework
How we applied qualitative learning, human labeling and machine learning to iteratively develop Airbnb’s Community Support Taxonomy.
By: Mia Zhao, Peggy Shao, Maggie Hanson, Peng Wang, Bo Zeng

Background
Taxonomies are knowledge organization systems used to classify and organize information. Taxonomies use words to describe things — as opposed to numbers or symbols — and hierarchies to group things into categories. The structure of a taxonomy expresses how those things relate to each other. For instance, a Superhost is a type of Host and a Host is a type of Airbnb User. Taxonomies provide vital terminology control and enable downstream systems to navigate information and analyze consistent, structured data.
Airbnb uses taxonomies in front-end products to help guests and hosts discover exciting stays or experiences, as well as inspirational content and customer support offerings. Airbnb also uses taxonomies in backstage tooling to structure data, organize internal information, and support machine learning applications.
Classifying the types of issues Airbnb community members face is vital for several reasons:
- Hosts and guests need to be able to describe issues to Airbnb in order to receive relevant help suggestions or get connected with the best support.
- Support Ambassadors (Airbnb’s Community Support specialists) need quick and easy access to workflows that help them resolve issues for guests and Hosts.
- Airbnb business units need to understand where and why guests and Hosts encounter problems so that we can improve our product and make the Airbnb experience better.
The Contact Reasons taxonomy is a new, consolidated issue taxonomy that supports all of these use cases. Before Contact Reasons, Community Support had siloed taxonomies for guests and Hosts, Support Ambassadors, and machine learning models that each used different words and structures to classify the same issues and relied on manual mapping efforts to keep in sync.
The consolidation of disjointed issue taxonomies into Contact Reasons was the first project of its kind at Airbnb. The development of such a new taxonomy requires iterative learning: create/revise the taxonomy by taxonomists; roll out to train ML model, product and services; evaluate the quality of the taxonomy and identify areas for improvement. Before this work, there was no systematic process in place to evaluate taxonomy development or performance and the iteration was mostly subjective and qualitative. To accelerate the iterative development with more quantitative and objective evaluation of the quality of the taxonomy, we created T-LEAF, a Taxonomy Learning and EvaluAtion Framework, to quantitatively evaluate taxonomy from three perspectives: coverage, usefulness, and agreement.
Challenges in Evaluating the New Taxonomy
In the Airbnb Community Support domain, new taxonomies or taxonomy nodes often need to be created before we have either real-world data or clear downstream workflow applications. Without a consistent quantitative evaluation framework to generate input metrics, it’s difficult to gauge the quality of a new taxonomy (or a taxonomy version) when directly applying it to downstream applications.
Lack of quantitative evaluation framework
Taxonomies are typically developed by qualitative-centric approaches¹. When we started prototyping the new taxonomy, we evaluated feedback from existing users, and recruited guests and Hosts for several rounds of user research to generate insights. While qualitative evaluation like domain expert review is helpful in identifying high-level challenges and opportunities, it is insufficient for providing evaluation at scale, due to small sample sizes and potential sample bias from users participating in the research.
Lengthy and iterative product cycle for taxonomy launches
Developing and launching a taxonomy can be a lengthy and iterative process that requires several quarters of use to get substantive and reliable quantitative feedback. A typical process includes:
- Taxonomy discovery and development based on product requirement or data-driven analysis
- Production changes to integrate backend environments and frontend surfaces, including necessary design and content updates
- ML model (re)label training data, retraining, and deployment
- Logging and data analysis on user feedback

Figure 1. Typical taxonomy development iteration cycle.
Before T-LEAF, the taxonomy development process relied solely on output metrics to measure the effectiveness of a new taxonomy, which means that: 1) major changes take a long time to experiment and test; and 2) minor changes like adding or updating new nodes aren’t tested. These two pain points can be addressed with the T-LEAF framework by consistent and periodic scoring.
T-LEAF has been developed to include more quantitative evaluation in the taxonomy development and address the above mentioned two pain points to accelerate the taxonomy development iteration.
Taxonomy Learning and EvaluAtion Framework (T-LEAF)
Quality of a Taxonomy
T-LEAF framework measures the quality of a taxonomy in three aspects: 1) coverage, 2) usefulness and 3) agreement.

Figure 2. T-LEAF Structure
Coverage
Coverage indicates how well a taxonomy can classify the scope of real-world objects. In Contact Reasons, coverage score evaluates how well the taxonomy captures the reasons guests and Hosts contact Airbnb’s Community Support team. When ‘coverage’ is low, a lot of user issues (data objects) will not be covered by the taxonomy and become ‘Other’ or ‘Unknown’.
Coverage Score = 1 - percentage of data classified as “other” or “undefined.”
Usefulness
Usefulness shows how evenly objects distribute across the structure of the taxonomy into meaningful categories. If a taxonomy is too coarse, i.e., has too few nodes or categories, the limited number of options may not adequately distinguish between the objects that are being described. On the other hand, if a taxonomy is too granular, it may fail to explain similarities between objects.
In T-LEAF, for a benchmark dataset with n examples (e.g., distinct user issues), we hypothesize that a taxonomy with sqrt(n) number of nodes² gives a good balance between ‘too coarse’ and ‘too granular’. For any input x, we compute a split score from (0,1] to evaluate the ‘usefulness’:

We want to evaluate the data deviation by assuming the normal distribution. For example, with 100 distinct user issues, if we split into 1 (‘too coarse’) or 100 categories (‘too granular’), the usefulness score would be close to 0; if we split into 10 categories, the usefulness score would be 1.
Agreement
Agreement captures the inter-rater reliability given the taxonomy. We propose two ways to evaluate agreement.
Human Label Inter-rater Agreement
Multiple human annotators annotate the same data according to the taxonomy definition and we calculate the inter-rater reliabilities using Cohen’s Keppa in the range of [-1, 1]:

ML Model Training Accuracy
Having multiple human raters annotate one data set can be expensive. In reality, most data is annotated by just one human. In Airbnb’s Community Support, each customer issue/ticket is processed by one agent and agents label the ticket’s issue type based on the taxonomy. We train a ML model based on this single-rater labeled training data and then apply the model over the training data to measure the training accuracy. If the taxonomy is well defined (i.e., with high ‘agreement’), then similar issues (data points) should have similar labels even though these labels come from different agents. ML models trained over highly agreed(consistent) training dataset should have high training accuracy.
We have done experiments comparing the multi-label inter-rater agreement approach and ML training accuracy over single-rated training data.
Results are shown in Table 1. We observed that for both methods: 1) accuracies were similar for the top two levels of the taxonomy (L1 and L2 issues are defined in the next section) and; 2) there were similar areas of confusion in both approaches. If taxonomy nodes are clear enough for humans to perform tagging, the consistency rate increases and the model can better capture human intent. The opposite is also true; model training accuracy is negatively impacted if end users are confused by options or unable to choose proper categories.
It took 1 analyst and 9 annotators about a month to create the multi-rater dataset. In contrast, it took one ML engineer a day to train a ML model over the single-rated data and calculate the training accuracy. As shown in Table 1, ML Training accuracy provides a similar evaluation of taxonomy’s ‘agreement’ quality.
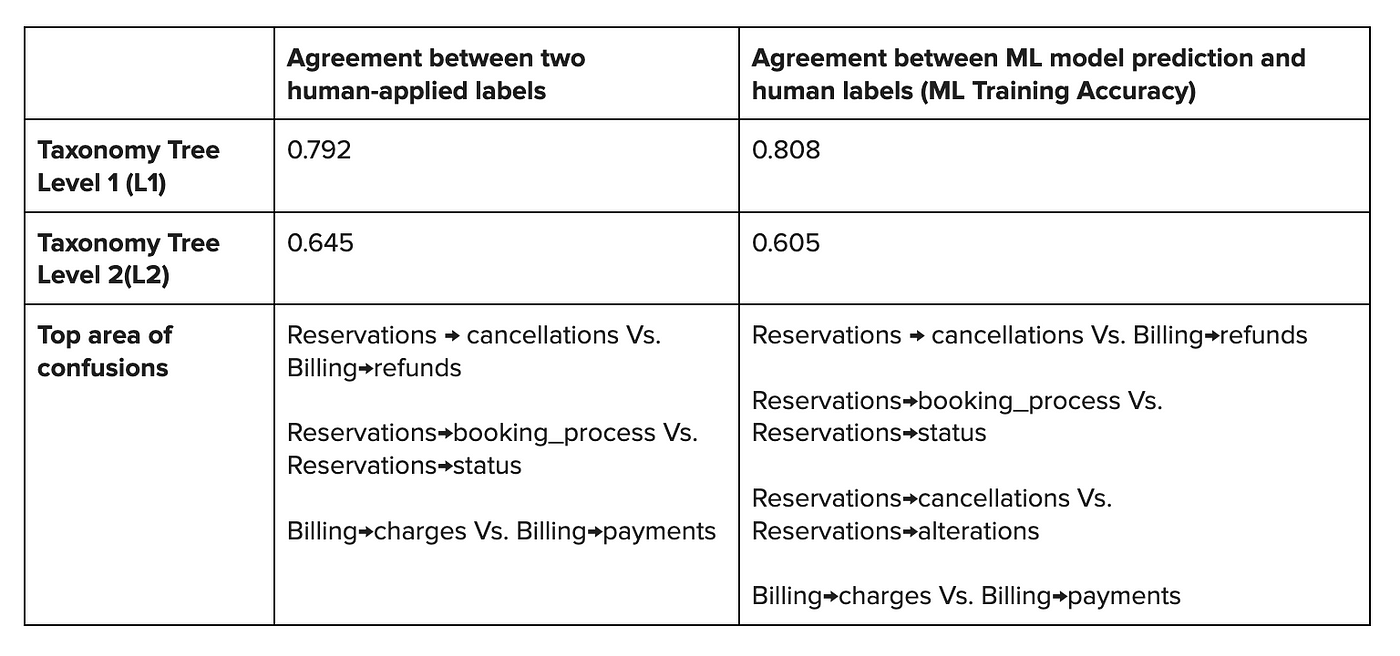
Table 1. Comparison between multi-rater labeling approach and ML-model over single-rater training data.
Developing the Contact Reason Taxonomy using T-LEAF
The Contact Reasons taxonomy consists of nearly 200 nodes, spread across a hierarchy that goes from broad categories in Level 1 (L1) to narrower categories in Level 2 (L2) to specific issues in Level 3 (L3). For example:
- Problems with your reservation (L1)
- Cleanliness and health concerns (L2)
- Smoke or other odors in listing (L3)
While the old taxonomy had unpredictable levels of granularity, depending on the section, Contact Reasons has a consistent, three-level structure that better supports our continuous evaluation framework. We utilized T-LEAF in the transition from the old taxonomy to the new taxonomy (Contact Reasons) to enable a faster feedback loop and provide a quantified quality control before launching the new taxonomy into production environments (Figure 3).
Figure 3. Iterative process of taxonomy development, evaluation, and deployment with T-LEAF.
First, we sent a real-world dataset to Airbnb Community Support Labs (CS Labs) — a group of skilled and tenured Support Ambassadors — for human annotation. Then, we used T-LEAF scores as an input to the taxonomy development process. Using that input,the Core Machine Learning (CoreML) Engineering team and the Taxonomy team collaborated to significantly improve T-LEAF scores before running experiments in production.
To evaluate the Contact Reasons taxonomy in one of these production environments, we reviewed its performance in Airbnb bot³. Airbnb bot is one of Community Support’s core products that helps guests and Hosts self-solve issues and connect to Support Ambassadors when necessary. We found that the improvements to the Contact Reason taxonomy as measured by T-LEAF’s metrics of coverage, usefulness, and agreement also translated to actual improvements in issue coverage, self-solve effectiveness, and issue prediction accuracy.
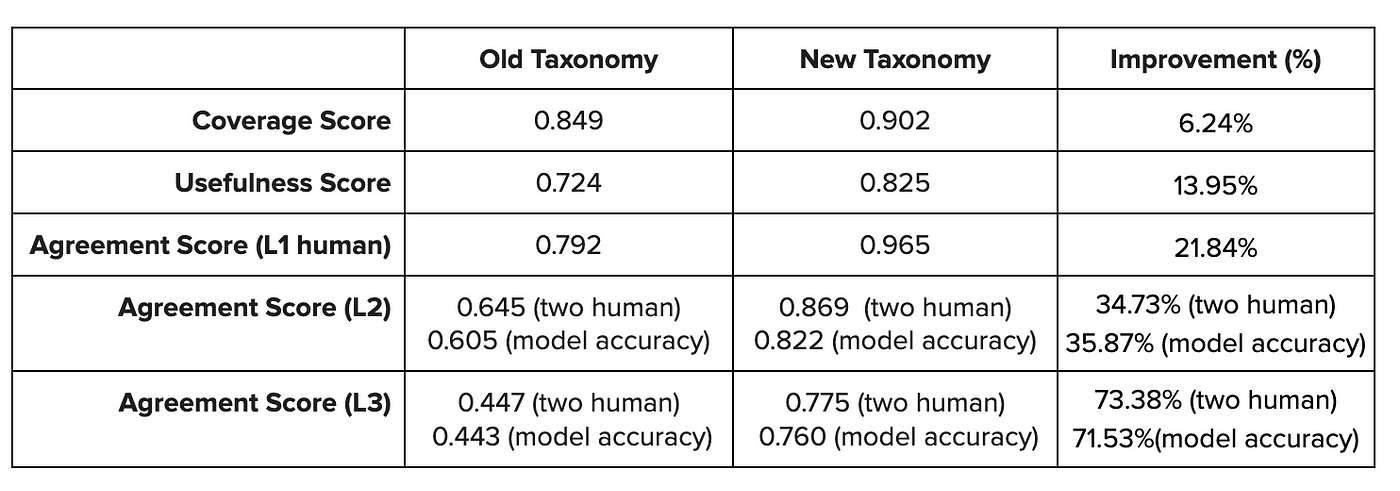
Table 2. T-LEAF scores between old and new taxonomies
A higher T-LEAF coverage score leads to greater issue coverage in production
After launching the Contact Reasons taxonomy, we examined 4-months of production data and found that 1.45% of issues were labeled “It’s something else,” which is 5.8% less than the old taxonomy. This is consistent with T-LEAF coverage score improvement (5.3% more coverage than the previous version).
A higher usefulness score leads to more issues being resolved through self-service
For example, in the new taxonomy, there are two new nodes called “Cancellations and refunds > Canceling a reservation you booked > Helping a Host with a cancellation” and “Cancellations and refunds > Canceling a reservation you’re hosting > Helping a guest with a cancellation.” The old taxonomy only have nodes for “Reservations > Cancellations > Host-initiated” and “Reservations > Cancellations >Guest-initiated”, which did not have granularity to determine when the guest or Host seeking support is not the one requesting the cancellation.
With the new nodes, we developed a machine learning model that drives traffic to tailored cancellation workflows⁴. This ensures that guests receive the appropriate refund and Host cancellation penalties are applied only when relevant, all without needing to contact Airbnb Support Ambassadors.
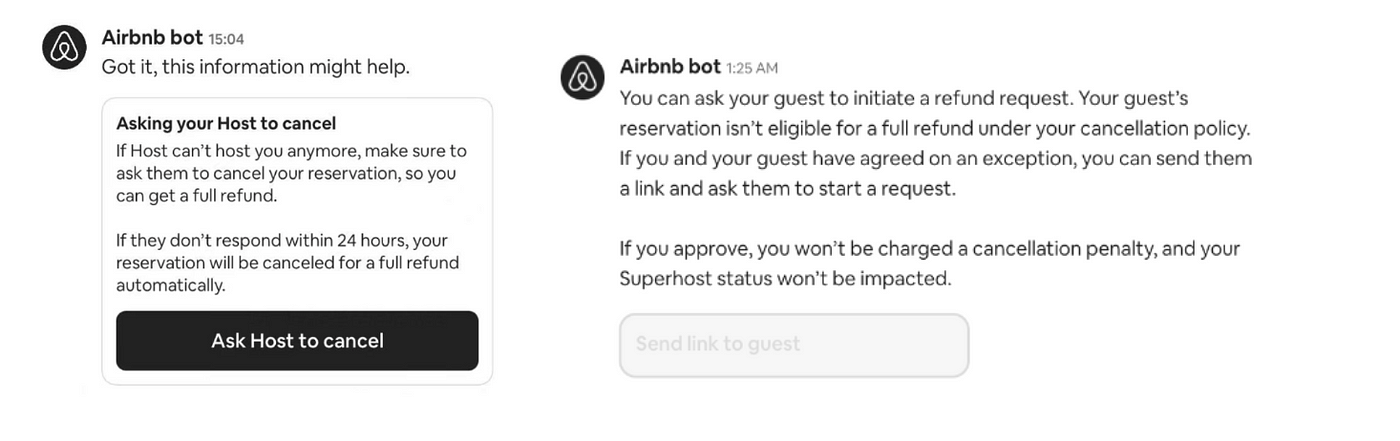
Figure 4. Airbnb Chatbot self-solve solutions
A higher T-LEAF agreement score results in more accurate issue prediction
Compared to issue prediction models built on the old taxonomy, the model built on the new taxonomy has improved accuracy by 9%. This means that the category the ML model predicts for an issue is more likely to match the category selected by the Support Ambassador.
Figure 5. User/Agent and ML Model Agreement
Conclusion
A quantitative framework to evaluate taxonomy supports faster iterations and reduces the risk of launching major taxonomy transformations, which has positive impacts for all of our audiences: guests, Hosts, Support Ambassadors, and Airbnb businesses. The T-LEAF framework that scores the quality of taxonomy in the aspects of coverage, usefulness, agreement, has now been applied to a production taxonomy in Community Support and results show that using this methodology for quantitative taxonomy evaluation can lead to better model performance and larger issue coverage.
Developing, piloting, and establishing T-LEAF as part of our continuous improvement framework for taxonomy evolution has been a collaborative effort across teams. The CoreML team partnered closely with Taxonomy, Product, and CS Labs to create this new model for iterative development of issue categorization and prediction. Having piloted this new way of working on Contact Reasons, we’re confident we’ll see more positive results as we continue to apply the T-LEAF methodology to future taxonomy initiatives
[1]: Szopinski, D., Schoormann, T., & Kundisch, D. (2019). Because Your Taxonomy is Worth IT: towards a Framework for Taxonomy Evaluation. ECIS. https://aisel.aisnet.org/ecis2019_rp/104/
[2]: Carlis, J., & Bruso, K. (2012). RSQRT: AN HEURISTIC FOR ESTIMATING THE NUMBER OF CLUSTERS TO REPORT. Electronic commerce research and applications, 11(2), 152–158. https://doi.org/10.1016/j.elerap.2011.12.006
[3]: Intelligent Automation Platform: Empowering Conversational AI and Beyond at Airbnb. https://medium.com/airbnb-engineering/intelligent-automation-platform-empowering-conversational-ai-and-beyond-at-airbnb-869c44833ff2
[4]: Task-Oriented Conversational AI in Airbnb Customer Support. https://medium.com/airbnb-engineering/task-oriented-conversational-ai-in-airbnb-customer-support-5ebf49169eaa
Acknowledgments
Thanks to CS Labs for labeling support on existing and new taxonomies!
Thanks to Pratik Shah, Rachel Lang, Dexter Dilla, Shuo Zhang, Zhiheng Xu, Alex Zhou, Wayne Zhang, Zhenyu Zhao, Jerry Hong, Gavin Li, Kristen Jaber, Aliza Hochsztein, Naixin Zhang, Gina Groom, Robin Foyle, Parag Hardas, Zhiying Gu, Kevin Jungmeisteris, Jonathan Li-On Wing, Danielle Martin, Bill Selman, Hwanghah Jeong, Stanley Wong, Lindsey Oben, Chris Enzaldo, Jijo George, Ravish Gadhwal, and Ben Ma for supporting our successful CS taxonomy launch and workflow related applications!
Thank Joy Zhang, Andy Yasutake, Jerry Hong, Lianghao Li, Susan Stevens, Evelyn Shen, Axelle Vivien, Lauren Mackevich, Cynthia Garda, for reviewing, editing and making great suggestions to the blog post!
Last but not least, we appreciate Joy Zhang, Andy Yasutake, Raj Rajagopal, Tina Su and Cynthia Garda for leadership support!