Maestro: The Orchestration Language Powering Shopify Flow
Adagio misterioso
Shopify recently unveiled a new version of Shopify Flow. Merchants extensively use Flow’s workflow language and associated execution engine to customize Shopify, automate tedious, repetitive tasks, and focus on what matters. Flow comes with a comprehensive library of templates for common use cases, and detailed documentation to guide merchants in customizing their workflows.
For the past couple of years my team has been working on transitioning Flow from a successful Shopify Plus App into a platform designed to power the increasing automation and customization needs across Shopify. One of the main technical challenges we had to address was the excessive coupling between the Flow editor and engine. Since they shared the same data structures, the editor and engine couldn't evolve independently, and we had limited ability to tailor these data structures for their particular needs. This problem was significant because editor and engine have fundamentally very different requirements.
The Flow editor provides a merchant-facing visual workflow language. Its language must be declarative, capturing the merchant’s intent without dealing with how to execute that intent. The editor concerns itself mainly with usability, understandability, and interactive editing of workflows. The Flow engine, in turn, needs to efficiently execute workflows at scale in a fault-tolerant manner. Its language can be more imperative, but it must have good support for optimizations and have at-least-once execution semantics that ensures workflow executions recover from crashes. However, editor and engine also need to play together nicely. For example, they need to agree on the type system, which is used to find user errors and to support IDE-like features, such as code completion and inline error reporting within the visual experience.
We realized it was important to tackle this problem right away, and it was crucial to get it right while minimizing disruptions to merchants. We proceeded incrementally.
First, we designed and implemented a new domain-specific orchestration language that addressed the requirements of the Flow engine. We call this language Maestro. We then implemented a new, horizontally scalable engine to execute Maestro orchestrations. Next, we created a translation layer from original Flow workflow data structures into Maestro orchestrations. This allowed us to execute existing Flow workflows with the new engine. At last, we slowly migrated all Flow workflows to use the new engine, and by BFCM 2020 essentially all workflows were executing in the new engine.
We were then finally in a position to deal with the visual language. So we implemented a brand new visual experience, including a new language for the Flow editor. This language is more flexible and expressive than the original, so any of the existing workflows could be easily migrated. The language also can be translated into Maestro orchestrations, so it could be directly executed by the new engine. Finally, once we were satisfied with the new experience, we started migrating existing Flow workflows, and by early 2022, all Flow workflows had been migrated to use the new editor and new engine.
In the remainder of this post I want to focus on the new orchestration language, Maestro. I’ll give you an overview of its design and implementation, and then focus on how it neatly integrates with and addresses the requirements of the new version of Shopify Flow.
A Sample of Maestro
Allegro grazioso
Let’s take a quick tour to get a taste of what Maestro looks like and what exactly it does. Maestro isn’t a general purpose programming language, but rather an orchestration language focused solely on coordinating the sequence in which calls to functions on some host language are made, while capturing which data is passed between those function calls. For example, suppose you want to implement code that calls a remote service to fetch some relevant customers and then deletes those customers from the database. The Maestro language can’t implement the remote service call nor the database call themselves, but it can orchestrate those calls in a fault-tolerant fashion. The main benefit of using Maestro is that the state of the execution is precisely captured and can be made durable, so you can observe the progression and restart where you left in the presence of crashes.
The following Maestro code, slightly simplified for presentation, implements an orchestration similar to the example above. It first defines the shape of the data involved in the orchestration: an object type called Customer with a few attributes. It then defines three functions. Function fetch_customers takes no parameters and returns an array of Customers. Its implementation simply performs a GET HTTP request to the appropriate service. The delete_customer function, in this example, simulates the database deletion by calling the print function from the standard library. The orchestration function represents the main entry point. It uses the sequence expression to coordinate the function calls: first call fetch_customers, binding the result to the customers variable, then map over the customers calling delete_customer on each.
Maestro functions declare interfaces to encapsulate expressions: the bodies of fetch_customers and delete_customer are call expressions, and the body of orchestration is a sequence expression that composes other expressions. But at some point we must yield to the host language to implement the actual service request, database call, print, and so on. This is accomplished by a function whose body is a primitive expression, meaning it binds to the host language code registered under the declared key. For example, these are the declarations of the get and print functions from the standard library of our Ruby implementation:
We now can use the Maestro interpreter to execute the orchestration function. This is one possible simplified output from the command line:
The output contains the result of calling print twice, once for each of the customers returned by the fetch service. The interesting aspect here is that the -c flag instructed the interpreter to also dump checkpoints to the standard output.
Checkpoints are what Maestro uses to store execution state. They contain enough information to understand what has already happened in the orchestration and what wasn’t completed yet. For example, the first checkpoint contains the result of the service request that includes a JSON object with the information about customers to delete. In practice, checkpoints are sent to durable storage, such as Kafka, Redis, or MySQL. Then, if the interpreter stops for some reason, we can restart and point it to the existing checkpoints. The interpreter can recover by skipping expressions for which a checkpoint already exists. If we crash while deleting customers from the database, for example, we wouldn’t re-execute the fetch request because we already have its result.
The checkpoints mechanism allows Maestro to provide at-least-once semantics for primitive calls, exactly what’s expected of Shopify Flow workflows. In fact, the new Flow engine, at a high level, is essentially a horizontally scalable, distributed pool of workers that execute the Maestro interpreter on incoming events for orchestrations generated by Flow. Checkpoints are used for fault tolerance as well as to give merchants feedback on each execution step, current status, and so on.
Flow and Maestro Ensemble
Presto festoso
Now that we know what Maestro is capable of, let’s see how it plays together with Flow. The following workflow, for example, shows a typical Flow automation use case. It triggers when orders in a store are created and checks for certain conditions in that order, based on the presence of discount codes or the customer’s email. If the condition predicate matches successfully, it adds a tag to the order and subsequently sends an email to the store owner to alert of the discount.

A typical Flow automation use case
Consider a merchant using the Flow App to create and execute this workflow. There are four main activities involved
- navigating the possible tasks and types to use in the workflow
- validating that the workflow is correct
- activating the workflow so it starts executing on events
- monitoring executions.
Catalog of Tasks and Types
The Flow Editor displays a catalog of tasks for merchants to pick from. Those are triggers, conditions, and actions provided both by Shopify and Shopify Apps via Shopify Flow Connectors. Furthermore, Flow allows merchants to navigate Shopify’s GraphQL Admin API objects in order to select relevant data for the workflow. For example, the Order created trigger in this workflow conceptually brings an Order resource that represents the order that was just created. So, when the merchant is defining a condition or passing arguments to actions, Flow assists in navigating the attributes reachable from that Order object. To do so, Flow must have a model of the GraphQL API types and understand the interface expected and provided by tasks. Flow achieves this by building on top of Maestro types and functions, respectively.
Flow models types as decorated Maestro types: the structure is defined by Maestro types, but Flow adds information, such as field and type descriptions. Most types involved in workflows come from APIs, such as the Shopify GraphQL Admin API. Hence, Flow has an automated process to consume APIs and generate the corresponding Maestro types. Additional types can be defined, for example, to model data included in the events that correspond to triggers, and model the expected interface of actions. For instance, the following types are simplified versions of the event data and Shopify objects involved in the example:
Flow then uses Maestro functions and calls to model the behavior of triggers, conditions, and actions. The following Maestro code shows function definitions for the trigger and actions involved in the workflow above.
Actions are mapped directly to Maestro functions that define the expected parameters and return types. An action used in a workflow is a call to the corresponding function. A trigger, however, is mapped to a data hydration function that takes event data, which often includes only references by IDs, and loads additional data required by the workflow. For example, the order_created function takes an OrderCreatedTrigger, which contains the order ID as an Integer, and performs API requests to load an Order object, which contains additional fields like name and discountCode. Finally, conditions are currently a special case in that they’re translated to a sequence of function calls based on the predicate defined for the condition (more on that in the next section).
Workflow Validation
Once a workflow is created, it needs validation. For that, Flow composes a Maestro function representing the whole workflow. The parameter of the workflow function is the trigger data since it’s the input for its execution. The body of the function corresponds to the transitions and configurations of tasks in the workflow. For example, the following function corresponds to the example:
The first call in the sequence corresponds to the trigger function that’s used to hydrate objects from the event data. The next three steps correspond to the logical expression configured for the condition. Each disjunction branch becomes a function call (to eq and ends_with, respectively), and the result is computed with or. A Maestro match expression is used to pattern match on the result. If it’s true, the control flow goes to the sequence expression that calls the functions corresponding to the workflow actions.
Flow now can rely on Maestro static analysis to validate the workflow function. Maestro will type check, verify that every referred variable is in scope, verify that object navigation is correct (for example, that order.customer.email is valid), and so on. Then, any error found through static analysis is mapped back to the corresponding workflow node and presented in context in the Editor. In addition to returning errors, static analysis results contain symbol tables for each expression indicating which variables are in scope and what their types are. This supports the Editor in providing code completion and other suggestions that are specific for each workflow step. The following screenshot, for example, shows how the Editor can guide users in navigating the fields present in objects available when selecting the Add order tags action.
Note that transformation and validation run while a Flow workflow is being edited, either in the Flow Editor or via APIs. This operation is synchronous and, thus, must be very fast since merchants are waiting for the results. This architecture is similar to how modern IDEs send source code to a language service that parses the code into a lower level representation and returns potential errors and additional static analysis results.
Workflow Activation
Once a workflow is ready, it needs to be activated to start executing. The process is initially similar to validation in that Flow generates the corresponding Maestro function. However, there are a few additional steps. First, Maestro performs a static usage analysis: for each call to a primitive function it computes which attributes of the returned type are used by subsequent steps. For example, the call to shopify::admin::order_created returns a tuple (Shop, Order) but not all attributes of those types are used. In particular, order.customer.name isn’t used by this workflow. It wouldn’t only be inefficient to hydrate that value, in the presence of recursive definitions (such as Order has a Customer who has Orders), it would be impossible to determine where to stop digging into the type graph. The result of usage analysis is then passed at runtime to the host function implementation. The runtime can use it to tailor how it computes the values it returns, for instance, by optimizing the queries to the Admin GraphQL API.
Second, Maestro performs a compilation step. The idea is to apply optimizations, removing anything unnecessary for the runtime execution of the function, such as type definitions and auxiliary functions that aren’t invoked by the workflow function. The result is a simplified, small, and efficient Maestro function. The compiled function is then packaged together with the result of usage analysis and becomes an orchestration. Finally, the orchestration is serialized and deployed to the Flow Engine that observes events and runs the Maestro interpreter on the orchestration.
Monitoring Executions
As the Flow Engine executes orchestrations, the Maestro interpreter emits checkpoints. As we discussed before, checkpoints are used by the engine when restarting the interpreter to ensure at-least-once semantics for actions. Additionally, checkpoints are sent back to Flow to feed the Activity page, which lists workflow executions. Since checkpoints have detailed information about the output of every primitive function call, they can be used to map back to the originating workflow step and offer insight into the behavior of executions.
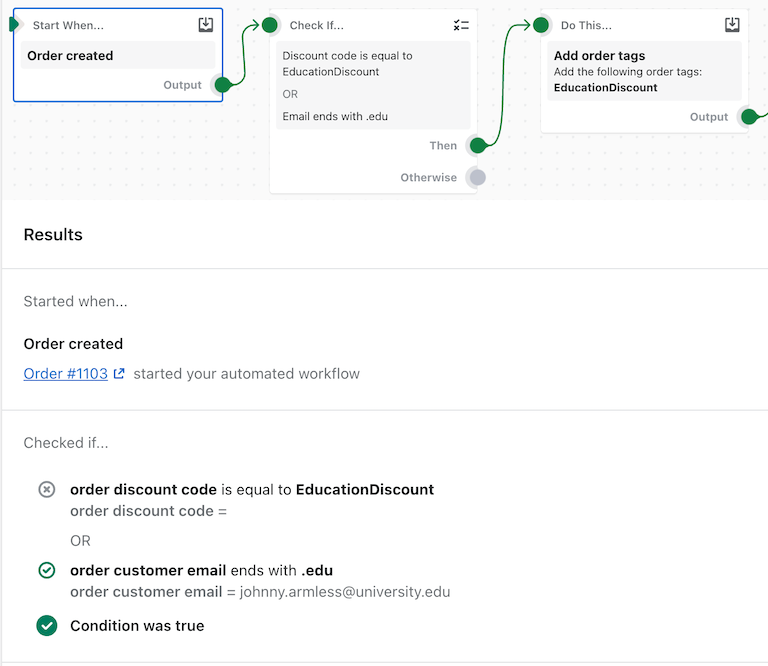
Shopify Flow Run Log from the Activity page
For instance, the image above shows a Run Log for a specific execution of the example, which can be accessed from the Activity page. Note that Flow highlights the branch of the workflow that executed and which branch of the condition disjunction actually evaluated to true at runtime. All this information comes directly from interpreting checkpoints and mapping back to the workflow.
Outro: Future Work
Largo maestoso
In this post I introduced Maestro, a domain-specific orchestration language we developed to power Shopify Flow. I gave a sample of what Maestro looks like and how it neatly integrates with Flow, supporting features of both the Flow Editor as well as the Flow Engine. Maestro has been powering Flow for a while, but we are planning more, such as:
- Improving the expressiveness of the Flow workflow language, making better use of all the capabilities Maestro offers. For example, allowing the definition of variables to bind the result of actions for subsequent use, support for iteration, pattern matching, and so on.
- Implementing additional optimizations on deployment, such as merging Flow workflows as a single orchestration to avoid redundant hydration calls for the same event.
- Using the Maestro interpreter to support previewing and testing of Flow workflows, employing checkpoints to show results and verify assertions.
If you are interested in working with Flow and Maestro or building systems from the ground up to solve real-world problems. Visit our Engineering career page to find out about our open positions. Join our remote team and work (almost) anywhere. Learn about how we’re hiring to design the future together—a future that is digital by design.