Too big to query: how to query HBase with minimal pain
In today’s world of media consumption and engagement, we on the Vimeo Analytics team had to find ways to scale and handle the massive amounts of analytical data growth that we experienced during the COVID era.
Video analytics at Vimeo has been supported for the most part by an HBase cluster, consisting of more than 100 machines atop Apache Phoenix. However, as our daily data growth exponentially exploded during the start of the pandemic, our cluster suffered from growing pains, where linear horizontal or vertical scaling wasn’t enough to support additional use cases and the increasing demand. Therefore, we developed a way to query Phoenix/HBase using Apache Spark from HBase snapshots with minimal impact on the cluster.

From United Nations Covid-19 Response — by Sanket Deshmukh
What problem are we trying to solve
As you might imagine, collecting, storing, processing, and providing video user analytics such as views, plays, watch time, engagement performance, social analytics, and other, much more complex metrics, all at scale, isn’t easy.
Our legacy HBase cluster atop Apache Phoenix stores hundreds of terabytes of video metrics and statistics, over 10 billion writes and 100 billion queries/requests a day. And this keeps going up on a daily basis.
As a result, our problem consists of the following attributes:
- Scale. There is a point where scaling up horizontally or vertically hits saturation, where adding more resources just doesn’t make sense economically or pragmatically anymore.
- Performance. Medium-sized Phoenix queries can substantially impact the cluster (frequent garbage collections, high CPU usage, and so on) and take resources from existing users and APIs.
- Stability. We must support new use cases and large analytical queries without impacting the existing requests and queries against the HBase cluster.
Here’s how we went about solving it. But first…
A quick note about Apache HBase and Phoenix
Before we jump into the solution, it’s important to understand HBase, HBase snapshots, and Phoenix. I’ll be brief.
About HBase
HBase is a distributed, scalable, consistent, low-latency, and random access key/value database. It provides a way to scan a range of rows defined by start and end keys (or row keys) quickly. The data itself is distributed to region servers (or machines) and regions and eventually ends up in HDFS as HFiles; see the diagram in Figure 1 below.
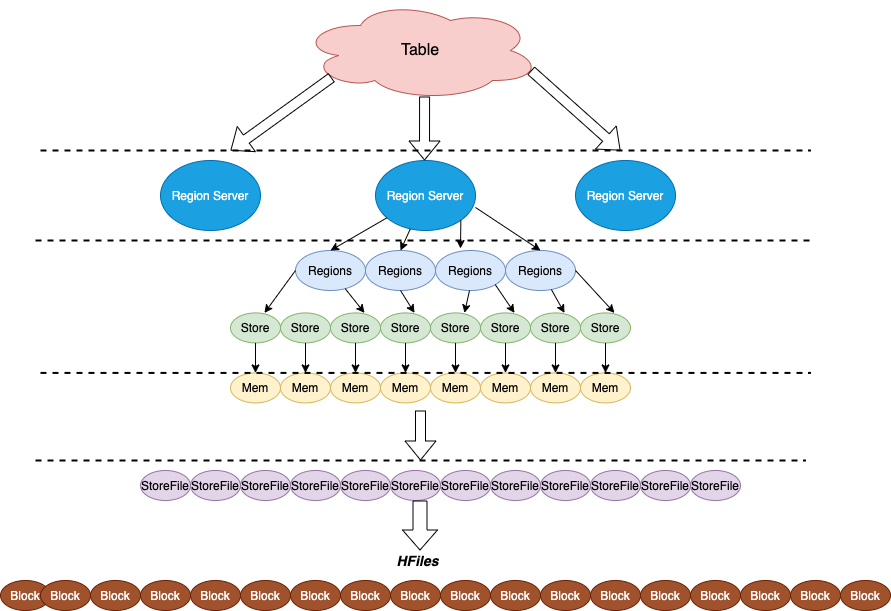
Figure 1. HBase data architecture
Correspondingly, a snapshot is a set of metadata information, not a copy of the table; it’s a set of operations to keep track of metadata (such as table info and regions) and data (including HFiles, MemStore, and Write Ahead Logs, as well as where everything resides).
About Phoenix
Phoenix provides a query abstraction layer over HBase. It has the following important functionalities:
- It breaks up SQL queries into multiple HBase scans and runs them in parallel.
- It takes care of salting, or randomizing the row key with a salting byte for a particular table, which enables you to migrate the issue of hotspotting (that is, having data in few RegionsServers) and help uniformly distribute write and read workload across all RegionsServers.
- It offers pre-splits, encoding, optimized filters, and much more.
Understanding the solution
Although Apache Phoenix and HBase are powerful tools to access, manage, and process big data sets, it’s not without a cost, as the processing of both Phoenix and HBase is coupled with the underlying data storage.
Therefore, by decoupling the query processing from the data to a different cluster outside of HBase, we essentially move the resource-intensive query computations away from HBase to a cluster dedicated to do those intensive high CPU/resource operations.
Accessing Phoenix data using Spark and HBase snapshots
It goes without saying that for this solution we need to use some type of a distributed processing engine to support large data retrievals. In our case, we’ll use Apache Spark.
The real question, then, is how can we access Phoenix-based data without going through the HBase/Phoenix client and taking resources from others.
As mentioned earlier, an HBase table snapshot contains metadata about the table, such as where the data and HFiles are stored, which regions, and, as a result, the corresponding scan ranges — the start of the region and end of the region.
By using the snapshot metadata, we can reconstruct the same logic Phoenix/HBase is using to get and retrieve the data by accessing the HFiles directly from Spark, which means we moved the processing from the HBase cluster to the Spark cluster.
There’s also one last problem. The data is salted, encoded, and stored by Phoenix, which means what you see in HBase is mostly unreadable Phoenix-encoded byte values. Hence, in addition to getting the data directly from HFiles, we also need to decode the values from byte values to readable formats such as strings and integers.
How do you do it?
The following is a rough guide for how to do it.

from Wikipedia — By Gerry and the Pacemakers
First and foremost, snapshots
This won’t be possible without a snapshot of the HBase table. To take a snapshot of the table, do the following in the HBase shell:
Second, create an HBase scan
Given a table defined by an HBase row keys (that is, a sorting key like UserID|VideoId|Timestamp), do the following:
Step 1. Translate the row key columns to bytes
Convert each column/part in the row key into a byte array:
Step 2. Concatenate and salting
Concatenate the converted byte array columns in the row key:
If salting was enabled on the table, call generateRowKey with the bucket value.
Step 3. Create the scan
Given a sequence of row key columns for start and end scan, use the previous steps to do the following:
If salting was enabled, re-do the scans for all the salt buckets. For instance, if your table has three salts, then you need to build scan ranges for row keys that start and end with bucket 0, then bucket 1, and so on.
Third, get the data
This is the most important and tricky part, getting the data from HDFS without going through the HBase/Phoenix client. Luckily in Spark we can utilize an existing functionality to read data stored in Hadoop (for example, files in HDFS, sources in HBase, or S3) and get an RDD for the given Hadoop files, namely newAPIHadoopRDD.
The following are the steps to configure and execute the HBase scans using newAPIHadoopRDD:
Step 1. Configure Hadoop properties
First create the scan above, and set the appropriate Hadoop properties:
Step 2. Configure and execute newAPIHadoopRDD
Given the snapshot name and temporary HDFS directory to dump the metadata from the table snapshot, execute the scan using newAPIHadoopRDD as follows:
You get Resilient Distributed Datasets, or RDD, of the KeyValue HBase results from the scans.
Fourth, translate the RDD byte results
Since the data is encoded to bytes by Phoenix, we need to translate the scan results based on the table schema, both for the row keys and cells. Here’s how.
Step 1. Get the row key from the row scan result
To get and translate the row key from the byte array to the row key columns, create a row key schema:
Next, get the row key columns based on the schema:
Putting it together, given the HBase results for each row from the scans in the previous section, do the following to retrieve the row key:
Step 2. Translate the cell values
Given an HBase cell, from the HBase result row, get the column name:
To get and translate the cell value, do the following for each:
Putting the “do it” together
Finally, after all the scanning, decoding/encoding, and various transformations, combine the last two sections as follows:
You have a DataFrame with two columns: one sequential with the row key columns, and the other a map of the cell KeyValue pairs.
To review the complete code, go to GitHub.
Last but not least: references and resources
Decoupling the data from the query engine isn’t a unique idea. The following are some good resources for understanding the solution better:
Join our team
Like our data, our team is growing! Check the open positions.