Building Data Quality into the Enterprise Data Lake

Photo by metamorworks on Shutterstock
This article describes how an Enterprise Data Lake team (EDL) at PayPal built the Rule Execution Framework (REF) to address an enterprise-level opportunity: creating a centralized, enterprise-level generic rule configuration system for defining, managing, controlling, and deploying the data quality framework’s rules and rulesets.
Why We Needed a Rule Execution Framework Team
Teams that are engaged in data transformation at PayPal must meet specific criteria regarding data quality:
- Guarantee that 100% of data that is passed to dependent systems downstream is certified, while providing complete transparency to any exceptions
- Ensure zero data loss
- Proactively identify quality issues and remediate quickly to reduce risk and costs, including reducing the number of critical alerts
- Improve the quality and accuracy of data
- Keep data secure
A key element of meeting these requirements is the ability to define and execute data quality rules. A rule contains a formula or expression to perform an operation, such as a validation or a transformation. For data quality rules, data is validated against the rule. If it fails, the failure details are persisted in exception tables.
The REF team was formed to build this rule execution framework.
The original requirement for REF was to provide capabilities for managing and executing different types of rules for teams addressing data going into the Enterprise Data Lake (EDL). We’ve expanded the capabilities to support any enterprise teams that need to manage, control, and deploy the data quality framework’s rules.
Challenges

Photo by Alex Brisbey on Unsplash
The REF team faced some specific challenges in the existing data landscape:
- Validation logic was embedded in the ETL (extract, transform, load) application code
- Authentication and connectivity for different types of data sources needed to adhere to our security standards
- Available tools had a steep learning curve
- Few tools addressed the requirement of fully embedded rule execution within the client application process
- We needed the ability to retry the failed rules
- The process to verify data that moves between data stores was manual and often after-the-fact
Validation logic
Before the development of REF, teams embedded validation logic in their ETL code and tools. For example, if they used an ETL tool, the validation logic was embedded in it. If they used a Java application, it was embedded in their Java application. One issue here is that adopting a new tech stack requires an expert who can rewrite the validation code and export it to a new tool. Updating the validation code for the same tool requires expert knowledge because the validation code and transformation code are intertwined within the ETL application.
The solution from REF was to separate the validation logic from any specific tool or process. REF extracts and captures metadata (tables, files, received messages, streaming data, etc.) from the data sources. Abstraction at the metadata level allows the framework to support multiple data sources (databases, files etc.) while using the same code for rule execution. The framework provides a reader for each type of data. Once the framework identifies an entity, it reads the data and converts it as a Spark DataFrame that can be processed by the rules engine.
The following figure shows high level overview of the metadata model:
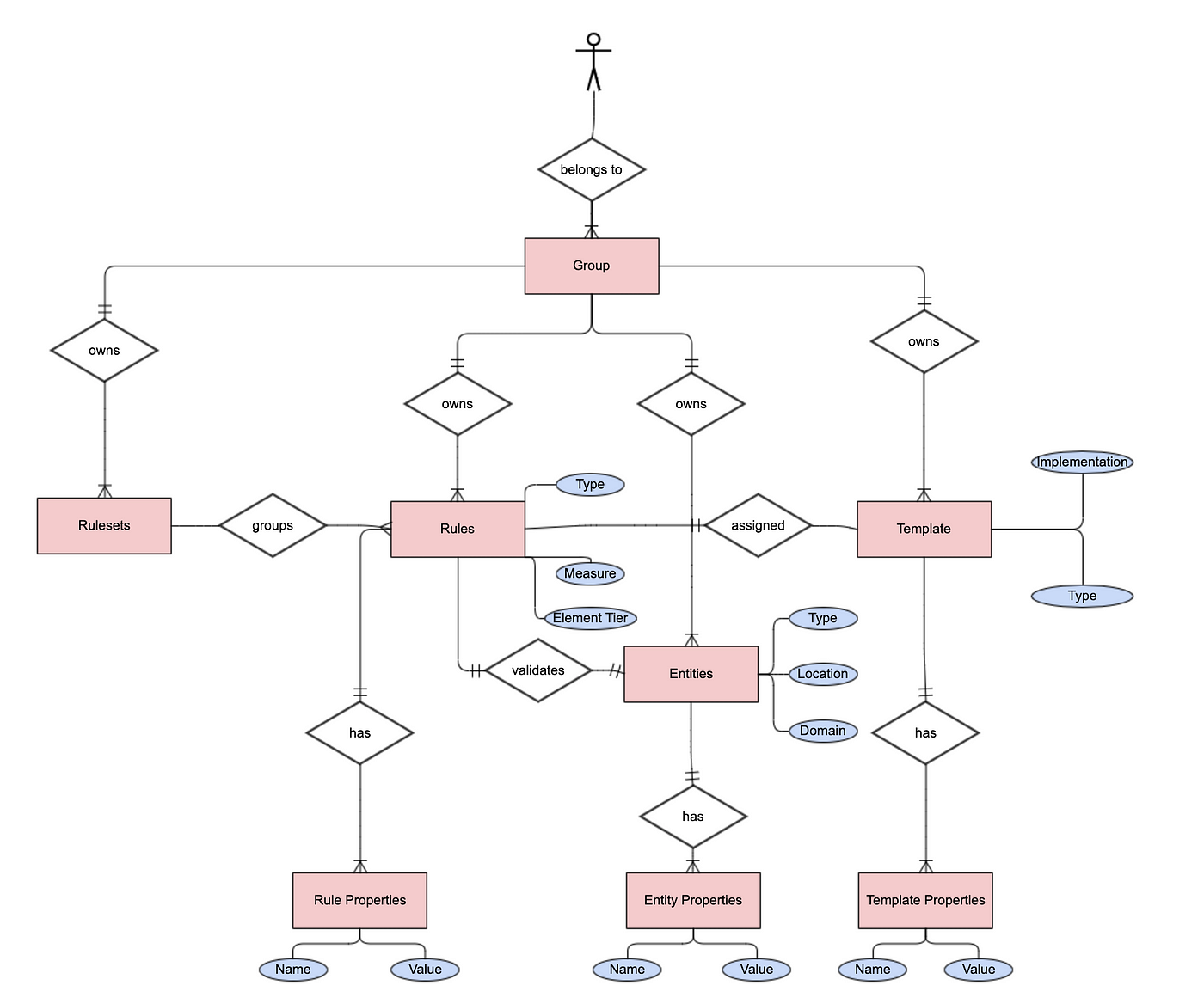
Metadata model
Learning curve

Photo by Colin Carter on Unsplash
The team looked at a lot of rules engines. Some of them were offering natural-language rules, whereas others were offering configuration-based execution. However, most of them have a steep learning curve, making them tough to manage complex rules. Therefore, we decided to use predefined rule templates with configurable attributes for simple rules. Mostly it’s a matter of configuring the table and column name with validation criteria for simple rules. For example, to perform a length check, the user needs to configure the table name, column name, and the expected length.
For writing complex rules, we decided to adopt SQL because pretty much everyone who works with data, from engineers, to business analysts, to data scientists knows SQL and can write SQL-based rules.
The REF team built an application that can execute the Data Quality (DQ) rules in batch mode against any data at rest, for example, in a table or a file. Users need to configure and publish the rules, and schedule the batch execution, but the application code is maintained by the REF team. Setting up batch execution is a one-time operation for each environment, for example, to run in a specific on-premises cluster or the cloud.
The REF application also provides execution support in the form of rulesets that allow a user to group and execute a set of related rules. For example, you could write rules for each column in a table and create a ruleset to execute all the rules for that table.
Running embedded code

Photo by Joshua Sortino on Unsplash
So far, we’ve talked about validation checks for data at rest. The REF team also had a requirement to validate streaming data within the ETL process. Not many tools can address this need, but the REF team decided to adopt the Drools Rule Language(DRL) to validate streaming data. REF offers a validation library that uses Drools under the hood. It can be invoked by making a function call, which allows clients to execute the rules within the application.
Certifying data
Another issue that the REF team addressed was certifying data that moves from one data store to another. We built a tool, Data Diff, to automate the process, and it is widely used for validating migrations between data warehouses. For example, it can compare the legacy on-premises data store with an equivalent one in the cloud.
The operation itself is resource intensive on both systems, so it’s only run to certify new builds. It compares data between the data stores and verifies that all records from the legacy system are in the new system. It also flags any differences between systems, such as duplicate records, mismatched columns, and so on. Data Diff does the comparison and publishes the result so that a user can compare differences between the data in the old store and in the new one.
Architecture
Our Rule Execution Framework (REF) provides the ability to configure rules and execute them. As a platform-level capability from EDL, REF offers a platform, framework, APIs, and UI. It is a multi-tenant and common service that can be consumed by any client or application. Currently, it supports data quality, data transformation, data profiling, anomaly detection and reconciliation rules, and is simple enough to be adopted by technical or non-technical users.
The following figure shows the REF architecture:
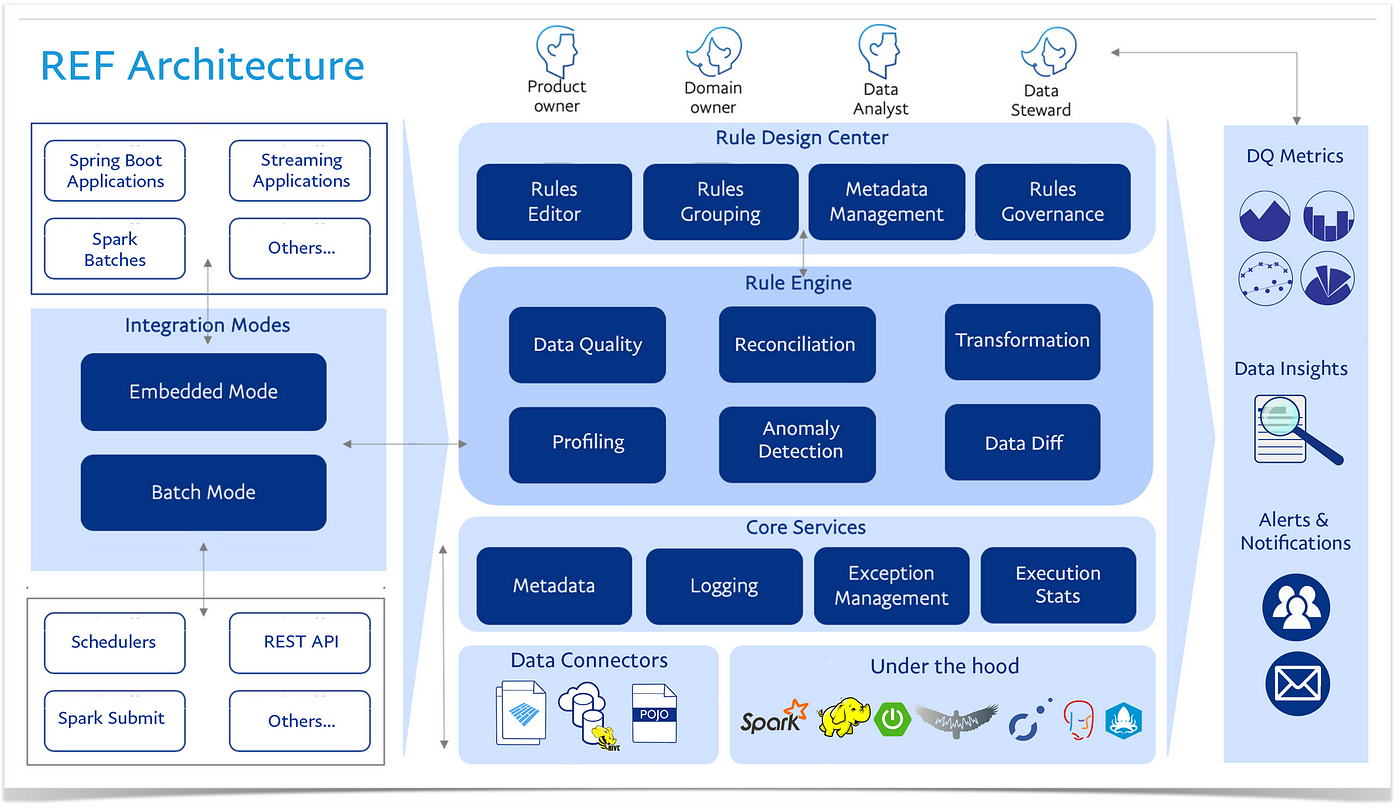
REF architecture diagram
Functionally, REF includes:
- An interactive application layer to add and manage rules
- A core rule engine built on top of open-source frameworks and libraries
- A reporting layer at the granularity of business uses cases, operational use cases, and technology use cases