How Pinterest powers a healthy comment ecosystem with machine learning
Yuanfang Song | Machine Learning Engineer, Trust and Safety; Qinglong Zeng | Engineering Manager, Content Quality Signals; and Vishwakarma Singh | Machine Learning Lead, Trust and Safety
As Pinterest continues to evolve from a place to just save ideas to a platform for discovering content that inspires action, there’s been an increase in native content from creators publishing directly to Pinterest. With the creator ecosystem on Pinterest growing, we’re committed to ensuring Pinterest remains a positive and inspiring environment through initiatives like the Creator Code, a content policy that enforces the acceptance of guidelines (such as “be kind” and “check facts”) before creators can publish Idea Pins. We also have guardrails in place on Idea Pin comments including positivity reminders, tools for comment removal and keyword filtering, and spam prevention signals. On the technical side, we use cutting edge techniques in machine learning to identify and enforce against community policy-violating comments in near real-time. We also use these techniques to surface the most inspiring and highest quality comments first in order to bring a more productive experience and drive engagement.
Since machine learning solutions were introduced in March to automatically detect potentially policy-violating comments before they’re reported and take appropriate action, we’ve seen a 53% decline in comment report rates (user comment reports per 1 million comment impressions).
Here, we share how we built a scalable near-real time machine learning solution to identify policy-violating comments and rank comments by quality.

Figure 1: Comment ecosystem on Pinterest
Facets of a comment
We broadly identified four facets of a comment: unsafe, or if the comment violates our Community guidelines; spam; sentiment; and quality. Sentiment of a comment can be positive, neutral, or negative. Quality of a comment can be high or low. We measure the quality of a comment by using intrinsic dimensions: readability, relevance to the Pin, and nuances. A comment is readable if it is error-free and understandable. A relevant comment is specific and related to the content of the Pin. Nuanced comments are questions, tips, suggestions, requests, or describe commenters’ personal experience or interaction with the Pin. A nuanced, readable, and relevant to the Pin comment is considered of high quality.
Machine learning solution
We leveraged machine learning techniques to identify policy-violating (unsafe and spam) comments as well as assessing sentiment and quality of comments. We modeled each of these tasks into classification tasks as described in Table 1. Our machine learning solution currently supports multiple languages (English, French, German, Portuguese, Spanish, Italian, and Japanese) and will be extended to other languages in the future.
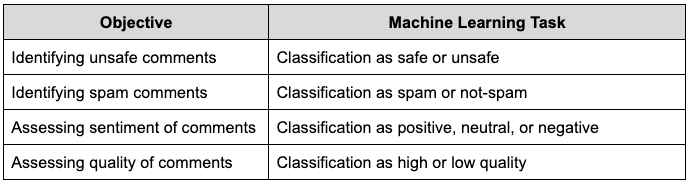
Table 1. Comment objectives transformed into classification tasks
Training data
We trained the model only using labeled comments for English. We adopted a mixed approach to limit the cost of collecting labeled data. Unsafe, spam, and not-spam labeled comments were obtained by human verification of community reported comments. Safe labeled comments were generated by random sampling of all the comments on Pinterest, as the number of unsafe comments is extremely low. Labeled data for positive and negative sentiment classes were obtained by human labeling of randomly sampled comments. Since the prevalence of negative comments is also extremely low, we used Vader sentiment analyzer to sample comments for negative sentiment labeling. For quality labeling, we collected reviewers’ responses for each of the quality defining factors for a comment. Finally, we collapsed those responses into three quality classes using the decision flowchart shown in Figure 2. Currently, we treat all medium quality comments as high quality comments and would explore a separate treatment in the future to bring finer control in comment quality ranking.
Figure 2: Labeling a comment for quality using intrinsic factors
Model
We designed a multi-task model, shown in Figure 3, which leverages transfer learning by fine-tuning a powerful state-of-the-art pre-trained transformer model (multilingual DistillBERT). This design choice yields the best value in terms of overall performance, lifecycle cost, and development velocity. Cost reduction comes from using a pre-trained model which needs a relatively small number of labeled data for further training and having to maintain a single model over life. Our evaluation showed that the performance of the multi-task model is comparable to standalone models for each classification task. We leveraged a multilingual pre-trained model as it helped us increase the coverage of the model, though with a curtailed performance, to many languages other than English without needing any specific training for those languages.
To bring context and improve the model’s performance, we also used Pin, Pinner, commenter, and additional comment features, which are components of Pinterest’s comment ecosystem (as shown in Figure 1). These features are concatenated with DistillBERT’s last hidden layer output and fed into a joint multi-layer perceptron (MLP), which also allows for cross-learning between features. Pin features include PinSage embedding and Pin language. Pinner and commenter features include taste similarities between them derived using PinnerSage embeddings and profile features like language. Additional comment features are comment length and language.
Figure 3: Multi-task comment model architecture
Each task head has its own output layer that produces score distribution over classes. Binary classification heads use sigmoid activation for output and binary cross-entropy for loss. Sentiment classification head uses softmax output layer and cross-entropy loss. For each training data instance, only those task heads contribute to the overall loss function for which the data point has labels. The model is implemented using Tensorflow and Keras and trained using data parallelism on multiple GPUs. We optimized for recall and false positive rate. We learned a score cut-off value to identify unsafe, spam, and negative sentiment comments.
Inference
We operationalized model inference to score newly created/edited comments in near-real time using Pinterest’s streaming data platform (Flink) as shown in Figure 4. We host the multi-task comment model in Pinterest’s online model serving platform (SMS). To prepare inputs for DistillBert, we host the corresponding tokenizer from hugging face as a service in Python Flask. The Flink job receives comments and their associated metadata from a Kafka queue populated by front-end API services on new comment-create or comment-edit events. This job uses the language of the comment as a filter to infer comments for only supported languages. It communicates with the Flask service over HTTP to get DistillBert inputs. It fetches other input features required by the model from a bunch of Pinterest’s data services (such as Galaxy Signal Service and Terrapin). The Flink job converts all the features into tensors and then makes a request to SMS for predictions. Eventually, it sinks the inference results into several data clients such as Rockstore, RealPin, and Kafka for serving and use by other consumers. Rockstore is a distributed key-value store and an administrative management and coordination API & MySQL backend store for the Pinterest KVStore platform. RealPin is a performant object retrieval system with highly customizable ranking, aggregating, and filtering capabilities.
Figure 4. Inference workflow for scoring comments
Serving
We have two separate serving workflows that use inference outputs and enforce policies as well as rank comments. Separation of workflows provides logical modularization and facilitates simplified operations, management, and diagnostics. First workflow filters unsafe and spam comments, and the other takes appropriate action of filtering or ranking using sentiment and quality scores among other factors. We currently treat replies as independent comments and provide similar treatment.
Conclusion
Our machine learning solution provides a formidable defense against likely policy-violating comments and ensures a safe ecosystem for our Pinner community to engage and be inspired. Identifying harmful comments and assessing comments’ quality will continue to evolve because of the role played by context, evolving trends, and other nuances like sarcasm, negations, comparatives, tone, polarity, sentiment transition, meaning transitions, etc. We plan to iteratively improve our solutions and revise our community guidelines. We also see opportunities to utilize the model for additional use cases, such as closed captioning, direct messaging, and other text-based forms of user engagement.
To learn more about Engineering at Pinterest, check out our Engineering Blog, and visit our Pinterest Labs site. To view and apply to open opportunities, visit our Careers page.
Acknowledgments
A huge thanks to Nina Qiyao Wang, Beatrice Zhang, Abhishek Jathan, and Hanyi Zhang for their contribution in the development and deployment of the model. We thank Maisy Samuleson and Ashley Chin for analysis, product insights, and support. Thanks to Andrey Gusev for insights and facilitation. Thanks to Shaji Chennan Kunnummel and Nilesh Gohel for sharing their technical insights. Finally, we thank Harry Shamshanky for his support in publishing this blog.