GraphQL Data Mocking at Scale with LLMs and @generateMock
How Airbnb combines GraphQL infra, product context, and LLMs to generate and maintain convincing, type-safe mock data using a new directive.
Press enter or click to view image in full size

Introduction
Producing valid and realistic mock data for testing and prototyping with GraphQL has been a persistent challenge across the industry for years. Mock data is tedious to write and maintain, and attempts to improve the process, such as random value generation and field-level stubbing, fall short because they lack essential domain context to make test data realistic and meaningful. The time spent on this manual work ultimately takes away from what most engineers would like to focus on: building features.
In this post, we’ll explore how we’ve reimagined mocking GraphQL data at Airbnb by combining GraphQL validation, rich product and schema context, and LLMs to generate and maintain convincing, type-safe mock data. Our solution centers around a simple new GraphQL client directive — @generateMock — that engineers can add to any operation, fragment, or field. This approach eliminates the need for engineers to manually write and maintain mocks as queries evolve, freeing up time to focus on building the product.
Key challenges
After meeting with Airbnb product engineers and analyzing results from internal surveys, we distilled the most common pain points around GraphQL mocking down into three key challenges:
- Manually creating mocks is time consuming. GraphQL queries can grow to hundreds of lines, and hand-crafting mock response data is extremely tedious. Most engineers manually write mocks as either raw JSON files or by instantiating types generated from the GraphQL schema, while others modify copy-and-pasted JSON responses from the server. Although both of these methods can yield realistic-looking data that can be used for demos and snapshot tests, they require significant time investment and are prone to subtle mistakes.
- Prototyping & demoing features without the server is hard. Typically, server and client engineers agree on a GraphQL schema early on in the feature development process. Once the schema has been established, however, the two groups split off and start working in parallel: Server engineers implement the logic to back the new schema and client engineers build the frontend UI, logic, and the queries that power them. This parallelization is particularly challenging for client engineers, since they can’t actually test the UI they’re building until the server has fully implemented the schema. To unblock themselves, client engineers often hardcode data into views, leverage proxies to manipulate responses, or hack custom logic into the networking layer locally, resulting in wasted time and effort.
- Mocks get out of sync with GraphQL queries over time. Since most mocks are hand-written, they are not tightly coupled to the underlying queries and schema they are supposed to represent. If a team builds a new feature, then comes back a few months later to add new functionality backed by additional GraphQL fields, engineers must remember to manually update their mock data. As there is no forcing function to guarantee mocks stay in sync with queries, mock data tends to shift further away from the production reality as time passes — degrading the quality of tests.
These challenges are not unique to Airbnb and are common across the industry. Although tooling like random value generators and local field resolvers can provide some assistance, they lack the domain knowledge and context needed to produce realistic, meaningful data for high-quality demos, quick product iteration, and reliable testing.
Goals
When setting out to solve these challenges at Airbnb, we established three north-star goals:
- Eliminate the need to hand-write mock data. Mock data should be generated automatically to free up engineers from needing to hand-craft and maintain mock GraphQL data.
- Create highly realistic mock data. Mock data should match the user interface designs and look like real production data in order to support high-quality demos, which are highly valued at Airbnb for early feedback.
- Keep engineers in their local focus loops. Our solution should seamlessly integrate into engineers’ current development processes so they can generate mocks without context-switching to a website, separate repository, or unfamiliar tool.
@generateMock: Schema + context + LLMs = magic
To generate mock data while keeping engineers in their local focus loops, we introduced a new client GraphQL directive called @generateMock, which engineers can use to automatically generate mock data for a given GraphQL operation, fragment, or field:
Press enter or click to view image in full size
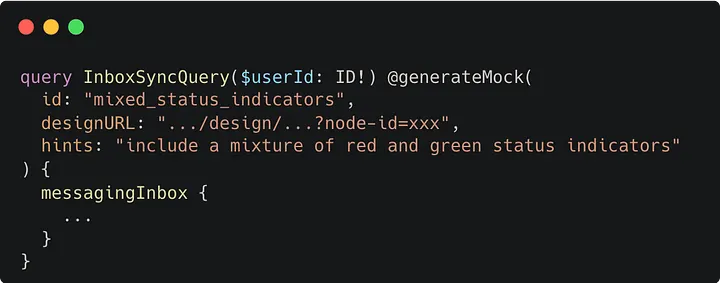
Example of @generateMock being specified on a GraphQL query.
This directive accepts a few optional arguments that engineers can use to customize the generated mock data, and the directive itself can be repeated with different input arguments to generate different mock variations:
- id: The identifier to use for the mock, as well as for naming generated helper functions. Useful when repeating the @generateMock directive to produce multiple mocks.
- hints: Additional context or instructions on how the mock should look. For example, a hint might be “Include travel entries for Barcelona, Paris, and Kyoto.” Under the hood, this information is fed to an LLM and heavily influences what the generated mock data looks like and how densely populated its fields are.
- designURL: The URL of a design mockup of the screen that will render the mock data. Specifying this argument helps the LLM produce mock data that matches the design by generating matching names, addresses, and other similar content.
At Airbnb, engineers use a command line tool we call Niobe to generate code for their GraphQL queries and fragments. After modifying a .graphql file locally, engineers run this code generator, then use the generated TypeScript/Kotlin/Swift files to send GraphQL requests. To generate mock data using @generateMock, engineers simply need to run Niobe code generation after adding the directive — just as they would after making any other GraphQL change.
During code generation, Niobe produces both a JSON file containing the actual mock data for each @generateMock directive, as well as a source file that provides functions for loading and consuming mock data from demo apps, snapshot tests, and unit tests. As shown in the Swift code below, the mockMixedStatusIndicators() function is generated on the InboxSyncQuery’s root Data type. It provides access to an instantiated type that’s populated with the generated mock data for mixed_status_indicators, allowing engineers to use the mock without having to load the JSON data manually:
Press enter or click to view image in full size

Using a generated mock in a Swift unit test.
Engineers are free to modify the generated mock JSON data as well — as we’ll see below, Niobe will avoid overwriting their modifications on subsequent generation invocations.
What does mock data look like?
The context that we provide to the LLM is vital to generating data that is realistic enough to use in demos. To this end, Niobe collects the following information and includes it in the context passed to the LLM:
- The definitions of the query/fragment/fields being mocked (i.e., those marked with @generateMock and their dependencies).
- The subset of the GraphQL schema being queried, as well as any associated documentation that is present as inline comments. This information enables the LLM to infer the types that are used by the query being mocked. Importantly, this isn’t the whole schema, because including the full schema would likely overload the context window — Niobe traverses the schema and strips out types and fields that are not needed to resolve the query, along with any extra whitespace.
- The URL for the image representation of the design document specified within designURL, if any. Niobe integrates with an internal API to generate a snapshot image of the provided node in the design document. The API pushes this snapshot to a storage bucket and provides a URL that Niobe feeds to the LLM, along with specialized instructions on how to use it.
- The additional hints specified in @generateMock.
- The platform (e.g., “iOS”, “Android”, or “Web”) for which the mock data is being generated (for style specificity).
- A list of Airbnb-hosted image URLs that the LLM can choose from if needed, along with short textual descriptions of each. This prevents the LLM from hallucinating image URLs that don’t exist and ensures that the mock data contains valid URLs which can be properly loaded at runtime when prototyping or demoing.
Press enter or click to view image in full size
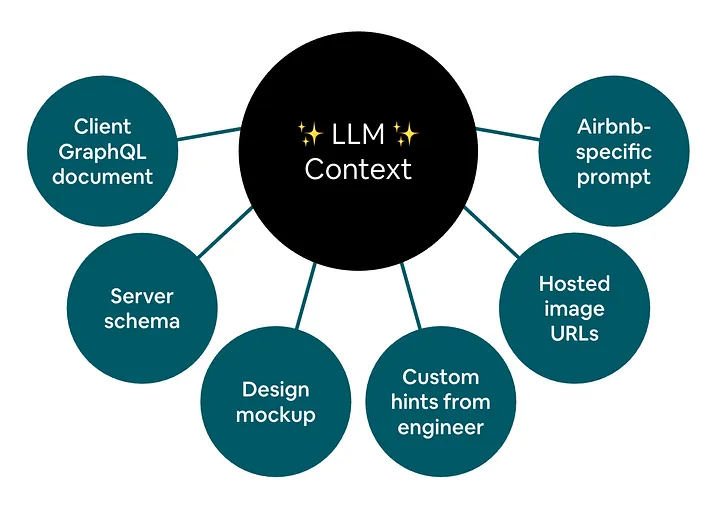
Illustration of the various pieces of context that are passed to the LLM during mock generation.
All this information is consolidated into a prompt we fine-tuned against Gemini 2.5 Pro. We chose this model because of its 1-million token context window, plus the fact that in our internal tests this configuration performed significantly faster than comparable models while producing mock data of similar quality. Using this approach, we’re able to produce highly realistic JSON mocks which, when loaded into the application, yield very convincing results as shown below:
Press enter or click to view image in full size
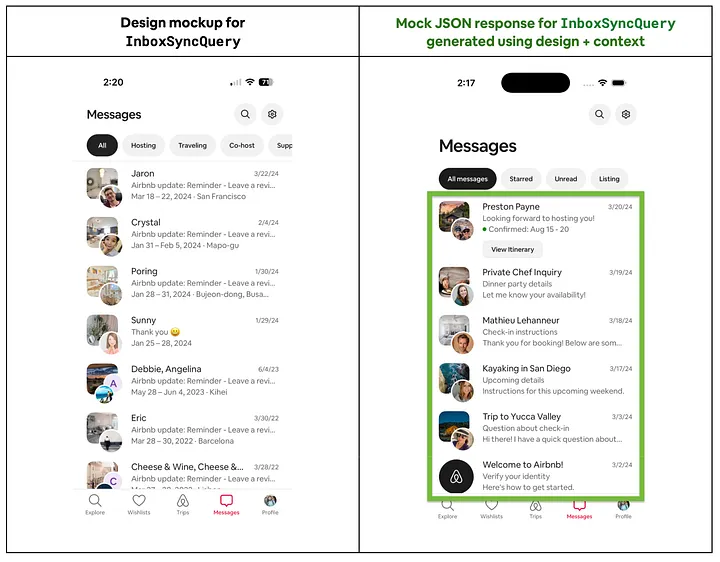
Screenshot of a design mockup compared to a mock that was generated using @generateMock.
The data in the screenshot on the right looks quite realistic, but if you look closely you may notice that the data is indeed mocked — all the photos are coming from the seed data set that we feed the LLM.
How it works
When an engineer uses the Niobe CLI to generate code for their GraphQL files, Niobe automatically performs mock generation as the final step of this process, as shown in the flowchart below:
- If the @generateMock directive includes a designURL, Niobe validates the URL to ensure it includes a node-id, then uses an internal API to produce an image snapshot of that particular node. The API, in turn, pushes this snapshot to a storage bucket and provides Niobe with its URL.
- Next, the CLI aggregates all the context described in the section above — including the URL of the design snapshot — and crafts a prompt to send to the LLM. This prompt is then sent to the Gemini 2.5 Pro model, and results are streamed back to the client in order to show a progress indicator in the CLI.
- Once the mock JSON response has been received from the LLM, Niobe performs a validation step against this data by passing the GraphQL schema, client GraphQL document, and JSON data to the graphql NPM package’s graphqlSync function.
- If the validation produces errors (for example, if the LLM hallucinated an invalid enum value or failed to populate a required field), Niobe aggregates these errors and feeds them back into the LLM along with the initial mock data. This retry mechanism is used to essentially “self-heal” and fix invalid mock data.
– This step is critical to reliably generating mock data. By placing the LLM within our existing GraphQL infrastructure, we’re able to enforce a set of guardrails through this validation step and provide strong guarantees that the mock data produced at the end of the pipeline is fully valid — something that wouldn’t be possible by using a tool outside our GraphQL infrastructure like ChatGPT.
– Finally, once the mock data has been validated, Niobe writes it to a JSON file, alongside a companion source file which provides functions for loading the mock from application code.
Press enter or click to view image in full size
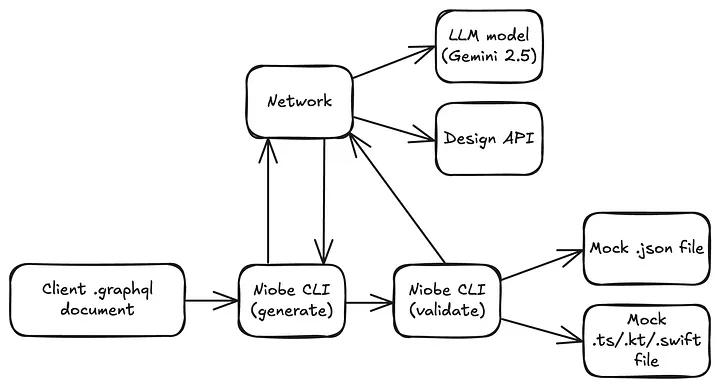
Flowchart of how mock generation works under the hood.
@respondWithMock: Unblocking client development
In addition to generating realistic mock data with @generateMock, we also wanted to empower client engineers to iterate on features without waiting for the backend server implementation. A second directive, @respondWithMock, works alongside @generateMock to make this possible:
Press enter or click to view image in full size
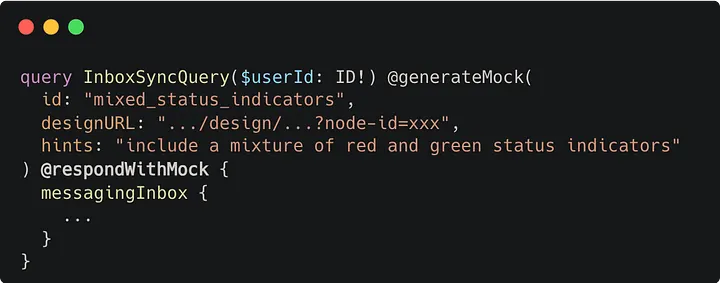
Simple example of using the @respondWithMock directive.
When this directive is present, Niobe alters the code that’s generated alongside the mock data to include extra details about this annotation. At runtime, the GraphQL client uses this to load the generated mock data, then seamlessly returns the mocked response instead of using data from the server. This effectively allows client engineers to unblock themselves from waiting on the server implementation, since they can easily use locally mocked data when querying unimplemented fields. The screenshot of the inbox screen earlier in this post is actually a real screenshot that was taken by generating with these two directives and running the Airbnb app in an iOS simulator — no manual mocking, proxying, or response modification needed!
@respondWithMock can also be specified on individual fields. When used on fields within a query instead of on the query itself, the GraphQL client will actually request all fields from the server except those annotated with @respondWithMock, then patch in locally mocked data for the remaining fields — producing a hybrid of production and mock data, and making it possible for client engineers to develop against new (unimplemented) fields in existing queries. Engineers can even repeat this directive and use query input variables to decide if and when to return a specific generated mock at runtime, as shown below:
Press enter or click to view image in full size
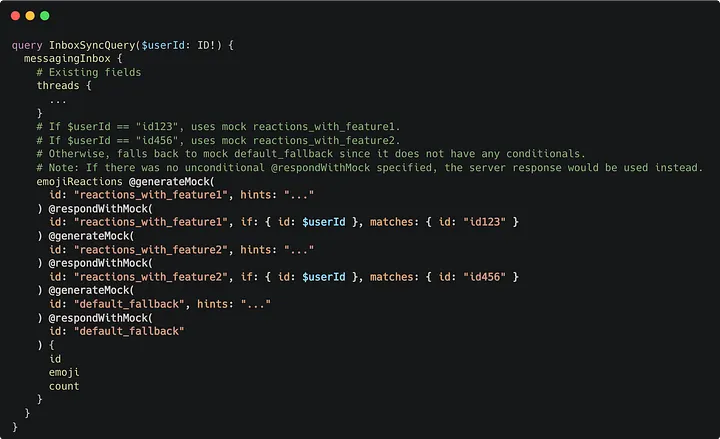
Using @respondWithMock with conditionals and on individual fields.
Schema evolution: Keeping mocks truthful
The final challenge we addressed was the issue of keeping mocks in sync with queries as they evolve over time. Since Niobe manages mock data that is generated via the @generateMock directive, it can be smart about maintaining that mock data. As part of mock generation, Niobe embeds two extra keys in each generated JSON file:
- A hash of the client entity being mocked (i.e., the GraphQL query document).
- A hash of the input arguments to @generateMock.
Press enter or click to view image in full size

Niobe embeds version hashes in mock data in order to determine when a given mock needs to be updated.
Each time code generation runs, Niobe determines whether existing mocks’ hashes differ from what their current hashes should be based on the GraphQL document. If they match, it skips mock generation for those types. On the other hand, if one of the hashes changed, Niobe intelligently updates that mock by including the existing mock in the context provided to the LLM, along with instructions on how to modify it.
It’s important that Niobe doesn’t unnecessarily modify existing mock data for fields that are unchanged and still valid, since doing so could overwrite manual tweaks that were made to the JSON by engineers or break existing tests that rely on this data. To avoid this, we provide the LLM with a diff of what changed in the query, and tuned the prompt to focus on that diff and avoid making spurious changes to unrelated fields.
Finally, each client codebase includes an automated check that ensures mock version hashes are up to date when code is submitted. This provides a guarantee that all generated mocks stay in sync with queries as they evolve over time. When engineers encounter these validation failures, they just re-run code generation locally — no manual updates required.
Conclusion
“@generateMock has significantly sped up my local development and made working with local data much more enjoyable.” — Senior Software Engineer
By integrating highly contextualized LLMs — informed by the GraphQL schema, product context, and UX designs — directly into existing GraphQL tooling, we’ve unlocked the ability to generate valid and realistic mock data while eliminating the need for engineers to manually hand-write and maintain mocks. The directive-driven approach of @generateMock and @respondWithMock allows engineers to build clients before the server implementation is complete while keeping them in their focus loops and providing a guarantee that mock data stays in sync as queries evolve.
In just the past few months, Airbnb engineers have generated and merged over 700 mocks across iOS, Android, and Web using @generateMock, and we plan to roll out internal support for backend services soon. These tools have fundamentally changed how engineers mock GraphQL data for tests and prototypes at Airbnb, allowing them to focus on building product features rather than crafting and maintaining mock data.
Acknowledgments
Special thanks to Raymond Wang and Virgil King for their contributions bringing @generateMock support to Web and Android clients, as well as to many other engineers and teams at Airbnb who participated in design reviews, built supporting infrastructure, and provided usage feedback.
Does this type of work interest you? Check out our open roles here.