Profile Generation with LLMs: Understanding consumers, merchants, and items

To elevate the quality of personalization, DoorDash is evolving how we represent our core entities. For years, we have relied on embeddings — dense numerical vectors learned by deep neural network (DNN) models — to represent entities such as consumer, store, or item to power our search and recommendation system. While embeddings are compact and compute-friendly, they come with trade-offs: They are opaque to humans, difficult to debug, and hard to interpret directly. It is nearly impossible to explain to consumers and merchandisers why two vectors are similar — for example, “0.83 cosine distance.”
Large language models (LLMs) unlock a complementary representation — rich, narrative-style profiles written in natural language. These profiles preserve semantic nuance such as “prefers spicy Sichuan dishes, avoids dairy” for intuitive understanding, while remaining fully interpretable by humans. This not only allows us to build more intuitive, human-facing product features — for example, explaining why a dish is recommended — but also serves as powerful, structured input for next-generation LLM applications. It's how we're building a more explainable and semantically aware platform. More specifically, these LLM profiles enable:
- Transparent recommendations, such as “We suggested this dish because you liked X and it matches your pescatarian preference,”
- Editable preferences that a customer support agent or the user can correct in plain English,
- Rapid feature prototyping so that product, marketing, or support teams can prompt LLMs against the profiles without retraining core models, and
- LLM-generated embedding as interpretable math representations to continue powering up DNN models.
As shown in Figure 1 below, we have developed profiles covering core entities for DoorDash’s business:
- Consumer profiles (Cx profiles): These profiles provide a 360-degree view of a consumer's food preferences, tastes, dietary needs, and lifestyle habits, breaking down preferences by day of the week and time of day.
- Merchant profiles (Mx profiles): Similar to Cx profiles, Mx profiles describe details such as a merchant's primary offerings, cuisine type, service quality, signature items, and economic values. This allows us to better understand and categorize our merchant partners.
- Item profiles: These profiles offer a detailed description of individual food items, including ingredients, taste profiles, and dietary classifications.
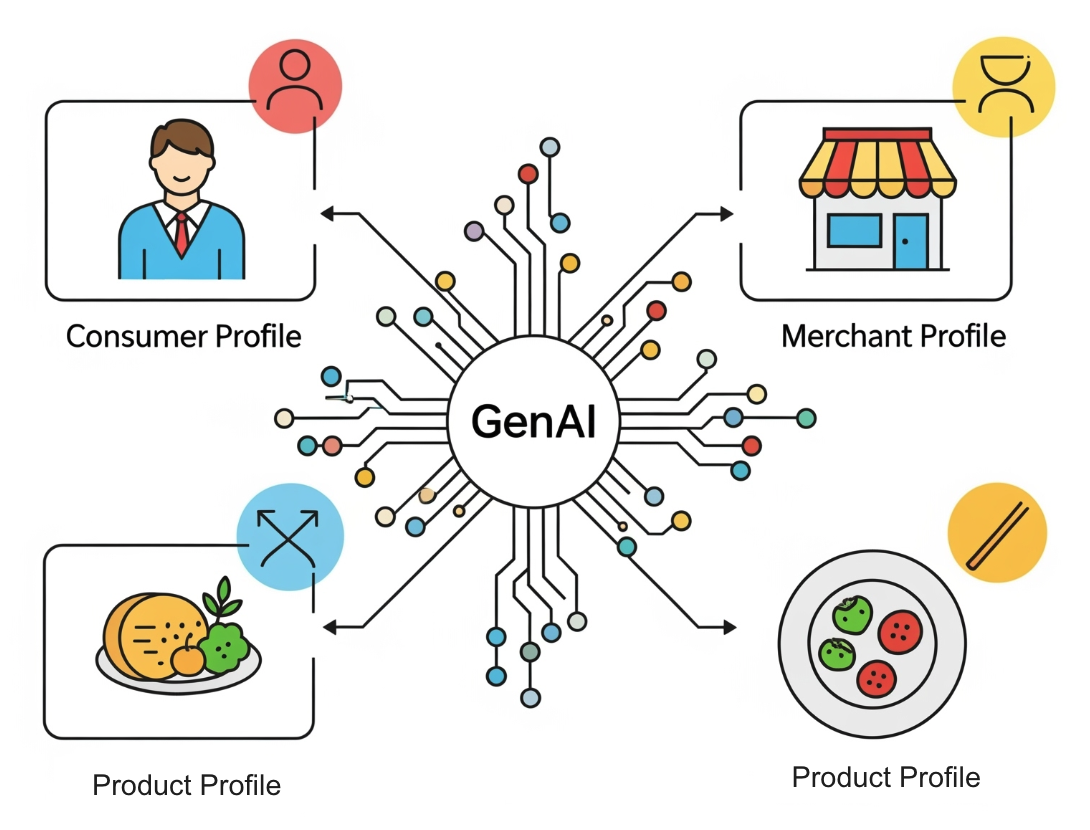
Figure 1: DoorDash uses GenAI to generate profiles for consumers, merchants, and products, including restaurant dishes as well as convenience and grocery items.
Traditionally, building such detailed profiles would require massive manual effort and would be difficult to scale. Our approach, which leverages LLMs, offers several key advantages:
- Scalability: We can generate profiles for millions of consumers, merchants, and items in a fraction of the time it would take to do so manually.
- Richness and detail: LLMs can generate nuanced and human-readable descriptions, capturing subtle details that would be missed using traditional methods.
- Automation: The process is largely automated, reducing the need for manual intervention and ensuring consistency.
- Adaptability: The models can be continuously updated with new data, ensuring that the profiles remain accurate and relevant over time.
Our profile generation process is broken down into the following high-level steps:
- Schema definition: As shown in Figure 2, we start by defining the structure and attributes of the core entities, ensuring consistency and clarity. We aim to generate a JSON blob for each entity, allowing the schema to evolve flexibly to meet future product needs while ensuring we identify key facets in each profile.
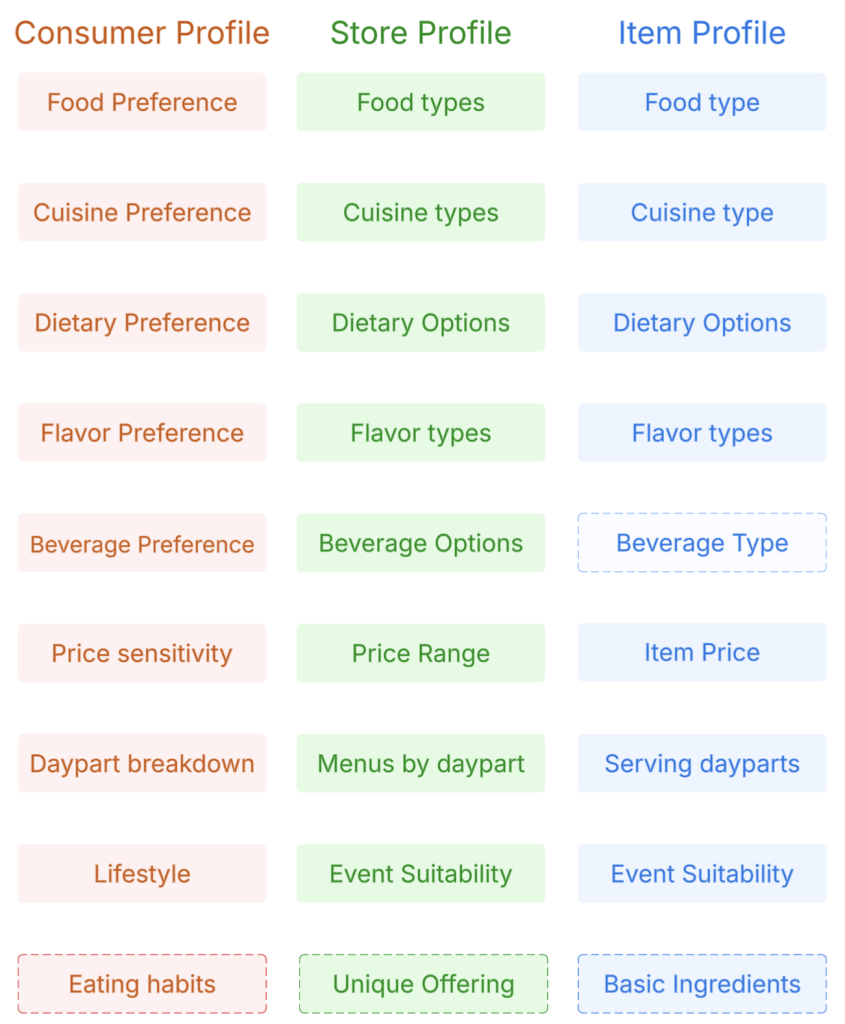
Figure 2: Key facets for consumer, store, and item profiles ensure characteristics are shared among profiles. In addition to these shared facets, each profile type has different facets to capture unique aspects.
- Input data preparation and aggregation: This foundational stage involves gathering, cleaning, and structuring the vast array of data points necessary to generate comprehensive profiles of consumers, merchants, and items. The effectiveness of the subsequent LLM-driven profiling relies heavily on the quality and richness of this input. More specifically:
- For a consumer profile, we look at the detailed order history, including the items and restaurants from which they've ordered along with metadata — for example, descriptions, titles, prices, and food tags — and the time of day they placed orders.
- For merchants, relevant data includes the past year's item sales, menu metadata -- such as category, title, and subtitle -- and store ratings/reviews. This encompasses both item sales and customer reviews in the app.
- For a dish item, we look for images, descriptions, and customization options, if available.
- Prompt engineering: These engineered features are then fed into an LLM, which is prompted to generate a detailed, human-readable profile. This is where the "magic" happens; the LLM synthesizes the various data points into a coherent and insightful description of the consumer, merchant, or item.
- LLM model selection: Offline, we then compare profile outputs across different model providers and between reasoning and non-reasoning models using sampled but representative cases. We have discovered that employing a reasoning model with a medium reasoning effort during profile generation significantly improves the capture of subtle nuances.
- Post-processing: This step focuses on appending extra fields and attributes to the LLM-generated profiles for various use cases and purposes, allowing us to accommodate data that doesn't require LLM inference.
Figure 3 shows an example of the process involved in generating a consumer profile.

Figure 3: In this example of consumer profile generation, the LLM can capture a consumer’s preferences based on their purchase history to generate a detailed explanation across dayparts.
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
The Principle: Use code for facts, use LLMs for narrative: Our guiding principle for generating profile facets is to use the right tool for the job to ensure speed, accuracy, and cost efficiency. For example:
- We use traditional code such as SQL or scripts for factual extraction:
- What: Directly querying objective, structured data.
- Examples: Calculating order frequency/average spend listing top-selling items, price ranges, or ingredient lists, or getting explicit tags such as "Vegan.”
- We use LLMs for narrative synthesis**:**
- What: Interpreting multiple or multi-modal signals to generate new, human-readable insights.
- Examples: Summarizing a consumer's taste profile ("Loves spicy food, prefers healthy lunches"); describing a merchant's ambiance from reviews ("A cozy date-night spot"); or describing an item's flavor ("A rich, savory broth").
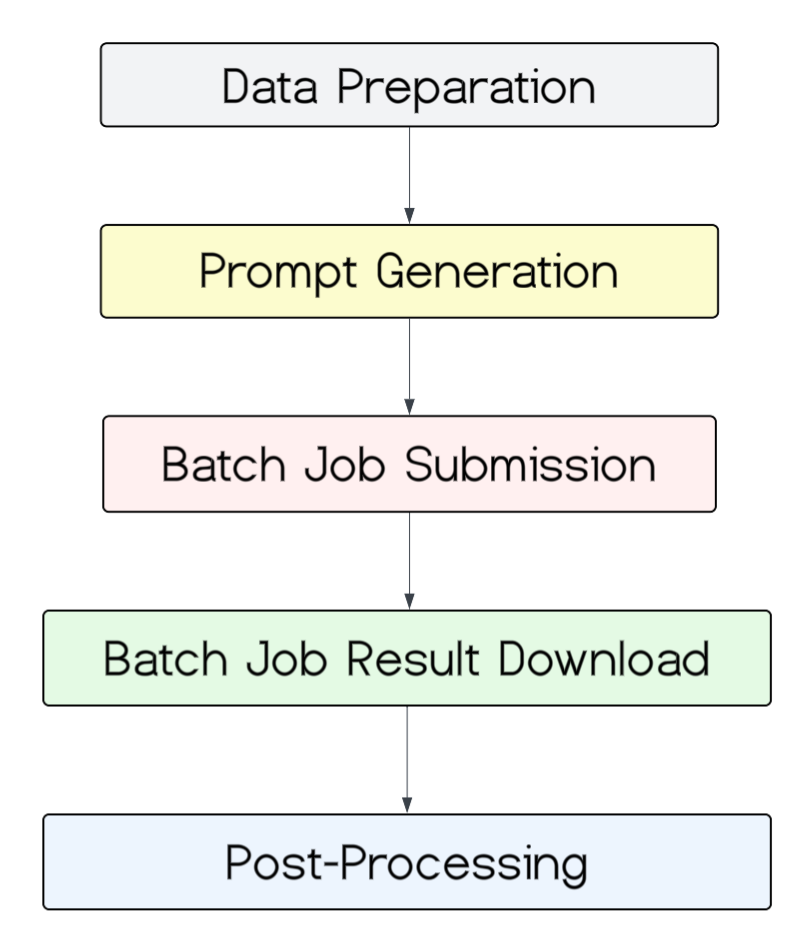
Figure 4: This is the hierarchy for key components of the productionization pipeline.
As shown in Figure 4, the pipeline moves batches through the process. Both consumer and merchant profile pipelines now run in Fabricator as batch jobs. The item profile generation job will be productionized by the end of 2025. To achieve cost efficiency and streamline the process, we prepare prompts in PySpark and submit them to the LLM in bulk rather than issuing one request per entity.
- Cost-efficient: Running in batch cuts per-profile spend by roughly 50% because we amortize latency, network overhead, and container start-up across thousands of rows.
- Efficiency: Spark distributes preprocessing and prompt generation jobs, while Fabricator’s batch API fans out the requests. We regularly push millions of records within an hour on a modest cluster size.
To isolate dependencies and control triggers for the batch jobs, profile generation is split into the following components:
- Data preparation job: Similar to base instances, this collects base data into Amazon S3.
- Prompt generation job: Generates prompt for each entity — consumer, store, or item — in one Pyspark job using a user-defined function (UDF).
- Batch job submission job: Batches the job and uploads it in Portkey files to create the batch jobs. This step stores batch_ids into S3 for tracking purposes.
- Batch result download job: Usually, a batch job is promised for completion within 24 hours. To improve efficiency, the batch download job runs one day after the batch job submission, fetching batch output.
- Post-processing jobs: Sometimes, there is a need to append additional fields for different use cases and purposes; such jobs would be run through post-processing.
These rich, narrative profiles, in conjunction with traditional embeddings, unlock a new suite of capabilities across our platform. They serve as a foundational layer both for improving existing systems and building entirely new product experiences.
Among the primary applications for this new capability are:
- Powering personalization with storytelling: The most direct impact is on features where we communicate directly with the user. Natural language profiles allow us to:
- Build an explainable recommendation experience: We can move beyond "black box" recommendations and explicitly tell a user why a store or item is a good match.
- Craft dynamic content: As shown in Figure 5, we can generate personalized carousels, store descriptions, and item summaries that are tailored to an individual's taste, rather than showing a generic view to everyone.
- Enable conversational search experiences: Provide the deep contextual understanding necessary for a conversational AI or "Magic Cart" feature to comprehend complex requests such as "Find me a healthy, low-carb lunch similar to the salad I ordered last Tuesday."
Figure 5: This is an example of profile-powered personalized carousels for image contextualization, including both carousel title, store selection, and store header.
- Enhancing next-generation models: These profiles serve as a powerful new input for our machine learning systems, including:
- Rich input for traditional machine learning: Provides new features through such narratives and summarizations as semantic IDs and embeddings.
- Solving the cold-start problem: For new merchants or products, a profile can be bootstrapped from the metadata at the start, instead of engagements, providing a strong baseline for personalization long before a significant order history has been established.
- Providing actionable, human-readable insights: Ultimately, these profiles are a powerful tool for internal teams for such things as accelerated analytics, allowing marketing, strategy, and operations teams to understand consumer segments and merchant characteristics through easy-to-read descriptions and reducing the reliance on complex SQL queries for qualitative insights.
Creating profiles is just the first step. To make this a core, reliable component of our platform, we must focus on a robust engineering roadmap centered on three key areas: Evaluation, serving, and iteration.
Ensuring the quality and accuracy of our profiles is paramount to building user trust. Our evaluation strategy is twofold:
- Offline evaluation: Assess new profile versions against current ones to make data-driven decisions.
- Model-based evaluation: As shown in Figure 6, use LLM-as-a-judge to automatically score profile quality using source data, generated profile, and a rubric, enabling rapid offline iterations.
- Task-specific evaluation: Employ LLMs as judges for task-specific evaluations offline to gauge the quality of applications using the generated profiles.
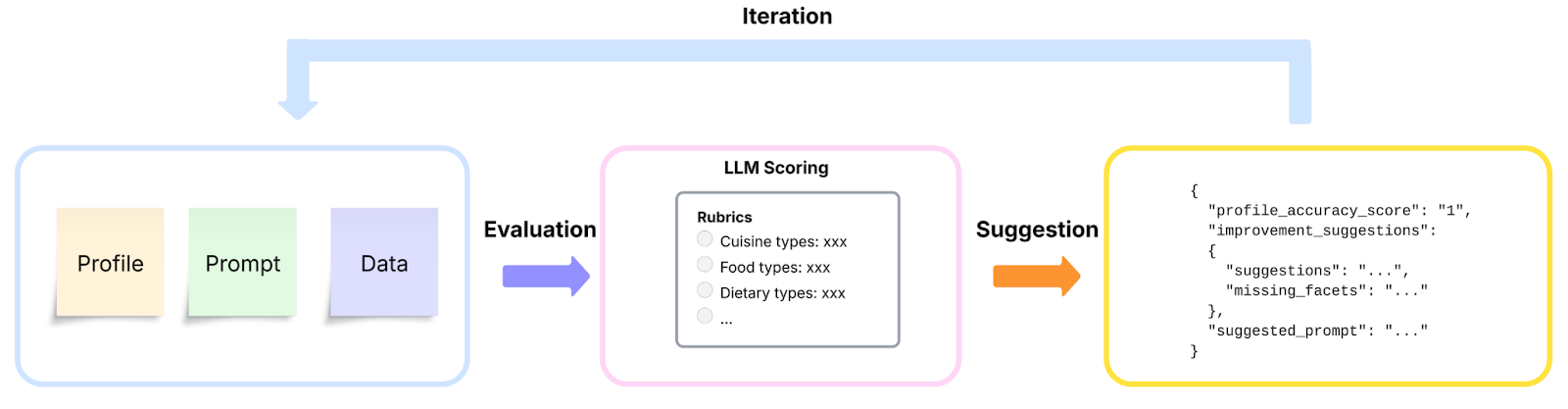
Figure 6: Example of model-based evaluation using LLM as a judge to automatically improve the prompt
- Online evaluation: The ultimate test is whether these profiles improve the user experience in production.
- Explicit feedback: In addition to an application-specific AB experiment, we can also surface the profile to the consumer and let them control the narrative. We can also convert the whole flow into a closed feedback loop for profile improvements.
In production, profile delivery relies on two core pipelines—a high-performance, low-latency storage layer and a versioned API for downstream retrieval:
- Low-latency and universal storage layer: The profiles we generate are stored in a high-performance, low-latency feature store or database. This ensures that downstream services can fetch profile data with the service level agreement requirement that they empower associated product features.
- Versioning/serving API: We are working to expose a clear, versioned API for other engineering teams to easily retrieve profiles. This API will become a fundamental part of our personalization infrastructure.
A static profile generation system will quickly become stale. We must build a continuous loop for improvement, especially for consumer profiles, while also:
- Closing the feedback loop: The insights from both offline and online evaluations will be fed directly back into the development cycle. For example, if A/B tests show that profiles mentioning specific cuisines drive higher engagement, we can update our prompts to favor that style.
- Creating systematic prompt engineering: We will treat our prompts as code, with version control, testing, and a structured process for experimentation to continuously refine the output.
- Developing model fine-tuning: As we collect high-quality examples of pairs — such as source_data, profile_text — validated by our human evaluation process, we will move towards fine-tuning our models. Fine-tuning can lead to higher accuracy, better adherence to our desired format, and lower inference costs over time.
Moving from opaque embeddings to human-readable language profiles doesn’t just add clarity — it unlocks whole new product surfaces. Teams can now explain recommendations, let users correct their profiles, and feed richer context to any future LLM feature. In short, narrative profiles turn our data into something for data-rich companies to use.
We’re deeply grateful to the entire Core CX organization for driving our GenAI initiative and go-to-market strategy.
- ML engineers — Sai Kolasani, Yuxiang Wang, Di Li, Chunlei Li, and Zhenzhen Liu: Your experimentation made the routine impossible.
- Backend engineers — Jun Jin, Phil Kwon, Atharva Patil, James Wang, Yefei Wang, Siyao Xiao, Ankit Prasad, Jeremy Pian, Ran Yu, Ujjwal Gulecha, Yunlong Gao, Ray Yamada, and Eric Gu for all the collaborations to enable its usage in production.
- Product and S&O partners — Aliza Rosen, Parul Khurana, Spring Ma, Kunal Moudgil, Mauricio Barrera, and Kathleen Zhou.
This project thrives because of your expertise, persistence, and teamwork. Thank you all!
Senior Software Engineer, Traffic
Engineering Manager, New Verticals - Retail
Software Engineer, Cloud Engineering
Senior Engineering Manager, Merchant Success
Statement of Non-Discrimination: In keeping with our beliefs and goals, no employee or applicant will face discrimination or harassment based on: race, color, ancestry, national origin, religion, age, gender, marital/domestic partner status, sexual orientation, gender identity or expression, disability status, or veteran status. Above and beyond discrimination and harassment based on “protected categories,” we also strive to prevent other subtler forms of inappropriate behavior (i.e., stereotyping) from ever gaining a foothold in our office. Whether blatant or hidden, barriers to success have no place at DoorDash. We value a diverse workforce – people who identify as women, nonbinary or gender non-conforming, LGBTQIA+, American Indian or Native Alaskan, Black or African American, Hispanic or Latinx, Native Hawaiian or Other Pacific Islander, differently-abled, caretakers and parents, and veterans are strongly encouraged to apply. Thank you to the Level Playing Field Institute for this statement of non-discrimination.