A scalable LLM approach to enhancing chatbot knowledge with user-generated content
DoorDash’s support chatbot handles a huge volume of questions from Dashers and customers every day. Chats can range from guiding a Dasher to their next delivery and reassuring a customer about what’s happening when an order runs late to explaining new features as they launch.
But as our marketplace grows, so does the complexity of these conversations. New policies, product changes, and a long tail of edge cases all demand fresh answers. Manually maintaining the knowledge base cannot effectively scale and is too resource-intensive and time-consuming.
We needed a smarter solution. By pairing clustering algorithms with large language models (LLMs), we can surface the highest‑ROI content gaps automatically and draft accurate articles in minutes instead of weeks based on user-generated content, or UGC. This allows our team to focus on refining and elevating new content, while the heavy lifting of identifying gaps and drafting new material happens at machine speed.
In this post, we walk through the system we built, the lessons we learned, and the impact we’re already seeing.
We begin by feeding thousands of anonymized chat transcripts into a semantic clustering pipeline, selecting only those conversations that were escalated to a live agent so that we can zero in on the cases where our chatbot fell short. The clusters that emerge highlight the issues causing the most friction for Dashers and customers, allowing us to rank gaps in the knowledge base, or KB, by both frequency and severity.
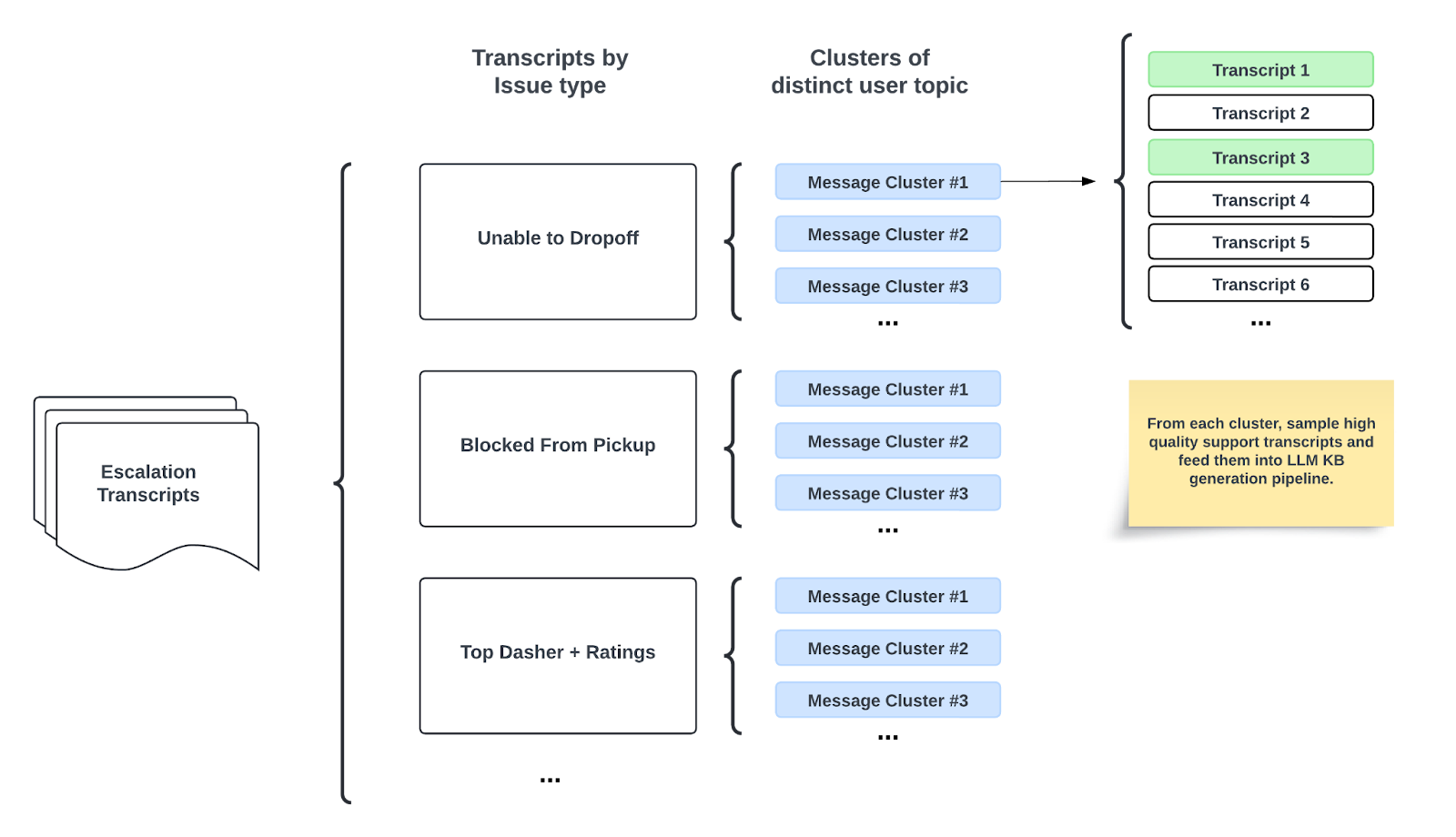
Figure 1. Escalated chat transcripts are automatically grouped into meaningful clusters using embeddings and similarity thresholds, so that each cluster highlights a distinct knowledge gap.
To create these clusters, every chat summary we use is run through an open-source embedding model, chosen for its strong performance in semantic-similarity tasks. Those vectors flow into a lightweight clustering routine: For each new embedded chat, we measure its cosine similarity to all current cluster centroids. If the best match exceeds a configurable threshold — in practice, 0.70 ≤ τ ≤ 0.90 — we assign the chat to that cluster and update the centroid via a running mean. If it does not exceed the threshold, we spin up a brand-new cluster. We iterate over thresholds until we find the sweet spot that merges duplicates without blurring genuinely different issues. This often requires manually inspecting the top K-clusters to confirm that each truly represents a distinct issue. We then merge any clusters that simply rephrase the same question. As a result, each cluster corresponds to a distinct topic — for example, 'How can I raise my rating?' — giving us a ranked, data-driven backlog of KB articles to write, as shown in Figure 1.
These high‑ROI topics then pass through an LLM that simultaneously tackles two jobs:
- Smart classifier: This classifies each cluster as either an actionable problem — for example, “My delivery was late; what can I do?” — or an informational query, such as “How do ratings work?”. Actionable clusters trigger workflow recipes and policy look‑ups, while informational ones become prime candidates for new KB articles, as shown in Figure 2.
- First‑draft generation: For each informational cluster, the model ingests the issue summary plus a handful of exemplary support agent resolutions to produce a polished draft of the KB articles that contain appropriate instructions to resolve the issue, as shown in Figure 3.
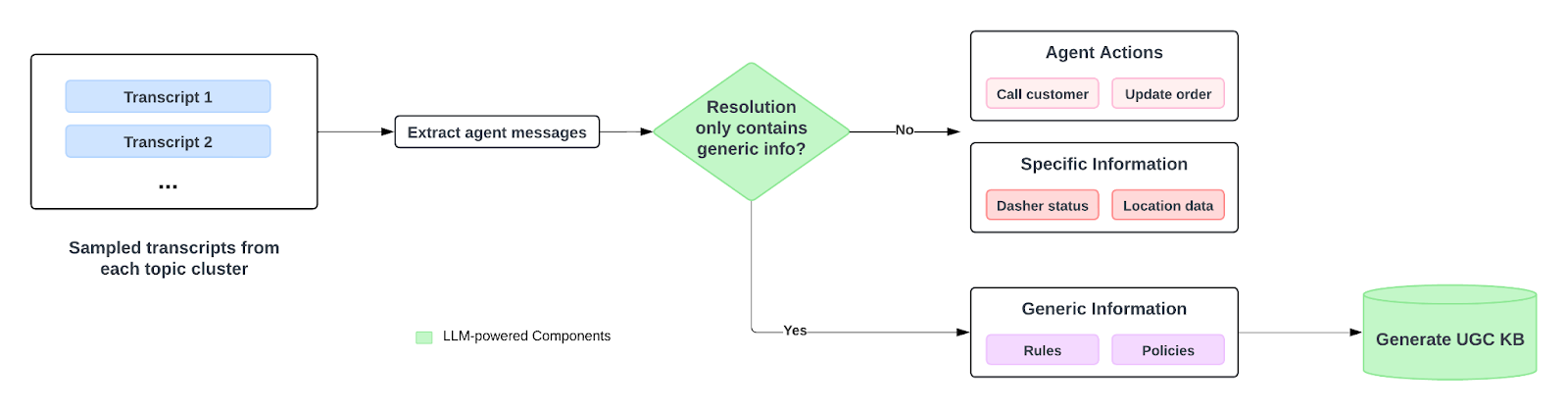
Figure 2. LLM processes transcripts and classifies them into different resolution types. Generic informational resolution becomes a prioritized candidate for new KB articles.
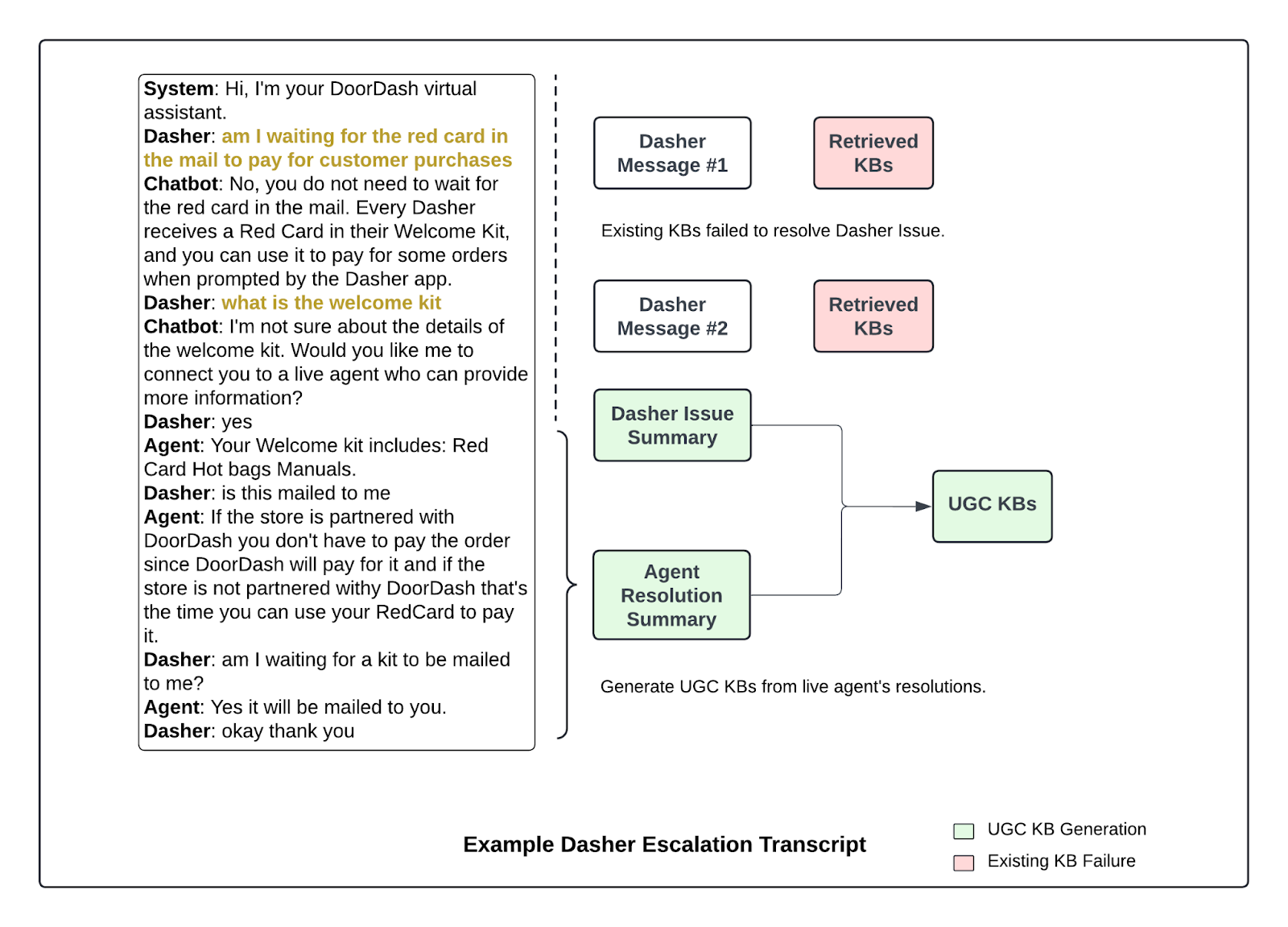
Figure 3. Unresolved chatbot interactions are escalated to live agents, whose resolutions are converted into new user-generated KB articles by LLM.
Subscribe to our Engineering blog to get regular updates on all the coolest projects our team is working on
Each auto‑draft flows into a lightweight review queue where content specialists and our operations partners sanity‑check policy references, tone, and edge cases. Even within a single topic cluster, for example, order cancellation, there can be multiple valid resolutions depending on the order type, delivery status, whether a temporary policy overrides the standard workflow, or whether the chat contains personal details that shouldn’t be used verbatim. Reviewers flag these nuances and either spin off tailored variants or annotate the draft so the chatbot can branch correctly at runtime.
To help the LLM capture that complexity, we increased the transcript sample set provided for each article and added explicit instructions for the LLM to surface policy parameters, conditional paths, and privacy redactions. During the first review pass, we still uncovered rough edges such as vague phrasing and missing conditional logic. As a result, we refined the prompt and re‑ran the KB generation. Edits now take minutes instead of days and every correction is logged and fed back into our future iteration.
Once approved, articles are surfaced by the chatbot via a RAG layer, as shown in Figure 4. The chatbot now retrieves the right article, blends it with conversation history and context, and answers with accurate and timely information.
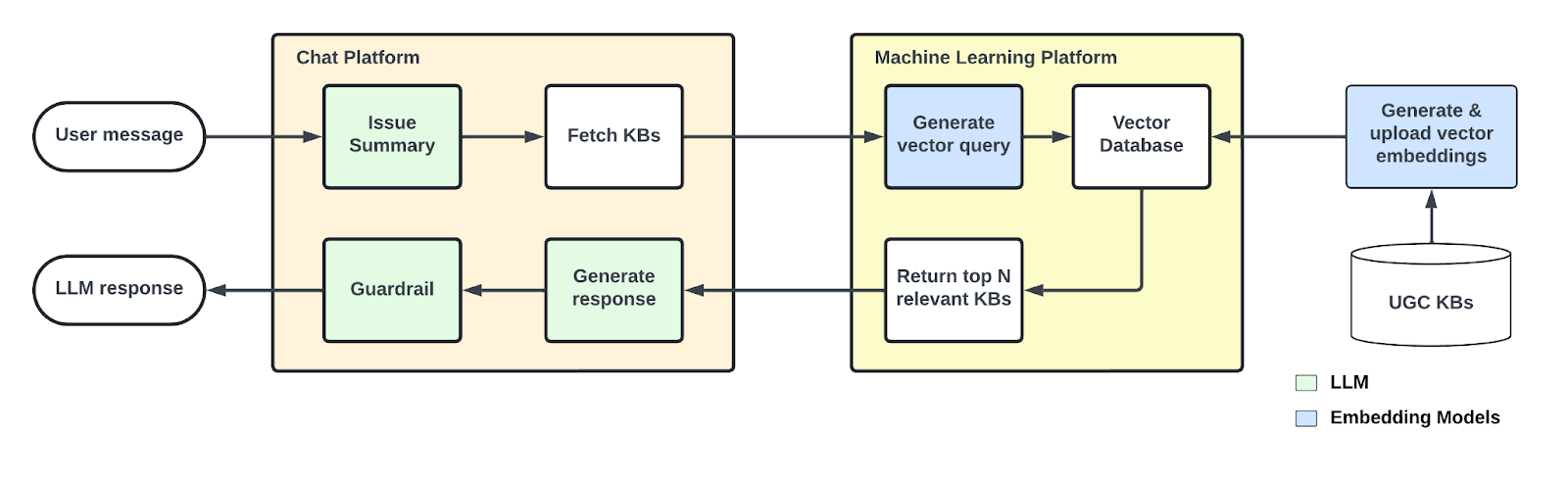
Figure 4. Serving UGC KBs in production: user-generated KBs are embedded, stored, and retrieved through a vector database, enabling the chat platform to fetch the most relevant content and generate safe, accurate LLM responses.
For retrieval to work reliably in production, the chatbot and the UGC KB generation pipeline must remain consistent with one another. Differences in how issues are summarized or embedded can create mismatches that reduce accuracy and make it harder to surface the right KB article at the right time.
- The prompt and model used for the issue summary in production should be very similar to those used in the UGC KB article generation to ensure effective retrieval.
- The embedding model used in the support chatbot production to convert an issue summary into vectors must be the same as the one used for generating vectors from the issue summary in the UGC KB database.
In practice, we make retrieval even more accurate by embedding only the “user issue” portion of each UGC KB article, rather than the entire KB entry. During serving, the chatbot compares the embedding of the live user issue summary directly against these stored issue embeddings. Once the most similar match is found, the system surfaces the corresponding KB content associated with that issue. This design keeps the retrieval targeted, reduces noise, and increases the precision of matching user problems with the right KB solution.
Offline experiments using an LLM judge are conducted to benchmark improvements over existing KB articles to significantly increase the relevance of the retrieved material. Online A/B testing with selected audiences is conducted to assess impact; results show the project effectively lowers escalation rates. For example, high-traffic escalation message clusters saw escalation rates drop from 78% in the control group to 43% in the treatment group, and roughly 75% of KB retrieval events in treatment now contain only UGC KB content. These results confirm that the new UGC content is closing the most critical knowledge gaps, allowing the chatbot to resolve informational queries that it previously had to escalate.
Leveraging LLMs and clustering isn’t just a neat technical trick; it’s already improving customer satisfaction, reducing escalations on long‑tail Dasher issues, and freeing our specialists from manual transcript review so they can focus on novel edge cases. Through pairing machine speed with human judgment, we’re scaling support without sacrificing quality.
And we’re not stopping here. Ongoing LLM judge evaluations and phased online experiments keep us honest, while follow-up initiatives such as adding personalized, order-specific context into the UGC pipeline — so that future articles aren’t just generic how‑tos but dynamically tailored to each Dasher, customer, or order status — already show initial success. If you’re tackling similar challenges, we hope these lessons help you ship faster and support smarter.
We would like to thank Kyoo Jo, Ferid Celosmanovic, and Peter Chao for their valuable inputs during the KB iteration and for reviewing the quality of the knowledge base. Special thanks to Chenran Gong for helping with the experiment setup, and to Blake Parsons for providing insightful product input.