Advancing Our Chef Infrastructure: Safety Without Disruption
Last year, I wrote a blog post titled Advancing Our Chef Infrastructure, where we explored the evolution of our Chef infrastructure over the years. We talked about the shift from a single Chef stack to a multi-stack model, and the challenges that came with it – from updating how we handle cookbook uploads to navigating the limitations around Chef searches.
If you haven’t had a chance to read that post yet, I highly recommend checking it out first to get the full context for this post.
At Slack, keeping our service reliable is always the top priority. In my last post, I talked about the first phase of our work to make Chef and EC2 provisioning safer. With that behind us, we started looking at what else we could do to make deploys even safer and more reliable.
One idea we explored was moving to Chef Policyfiles. That would have meant replacing roles and environments and asking dozens of teams to change their cookbooks. In the long run, it might have made things safer, but in the short term it would have been a huge effort and added more risk than it solved.
So instead, this post is about the path we chose: improving our existing EC2 framework in a way that doesn’t disrupt cookbooks or roles, while still giving us more safety in our Chef deployments.
Splitting Chef Environments
Previously, each instance had a cron job that triggered a Chef run every few hours on a set schedule. These scheduled runs were primarily for compliance purposes — to ensure our fleet remained in a consistent and defined configuration state. To reduce risk, the timing of these cron jobs was staggered across availability zones, helping us avoid running Chef on all nodes simultaneously. This strategy gave us a buffer: if a bad change was introduced, it would only impact a subset of nodes initially, giving us a chance to catch and fix the issue before it spread. However, this approach had a critical limitation. With a single shared production environment, even if Chef wasn’t running everywhere at once, any newly provisioned nodes would immediately pick up the latest (possibly bad) changes from that shared environment. This became a significant reliability risk, especially during large scale-out events, where dozens or hundreds of nodes could start up with a broken configuration.
To address this, we split our single production Chef environment into multiple buckets: prod-1, prod-2, …, prod-6. Service teams could still launch instances as “prod,” but behind the scenes we mapped each instance to one of these more specific environments based on its Availability Zone. That way, new nodes no longer pulled from one global source of truth – they were evenly distributed across isolated environments, which added an extra layer of safety and resilience.
At Slack, our base AMIs include a tool called Poptart Bootstrap, which is baked in during the AMI build process. This tool runs via cloud-init at instance boot time and is responsible for tasks such as creating the node’s Chef object, setting up any required DNS entries, and posting a success or failure message to Slack (with customisable channels based on the team that owns the node).
To support the environment split, we extended Poptart Bootstrap to include logic that inspects the node’s AZ ID and assigns it to one of the numbered production Chef environments. This change allowed us to stop pointing all production nodes at a single shared Chef environment and instead spread them across multiple environments.
Previously, changing the cookbook versions in the single prod environment affected the entire fleet. With this new bucketed approach, we gained the flexibility to update each environment independently. Now, a change to a single environment only impacts nodes in specific AZs, significantly reducing risk and blast radius during deployments.
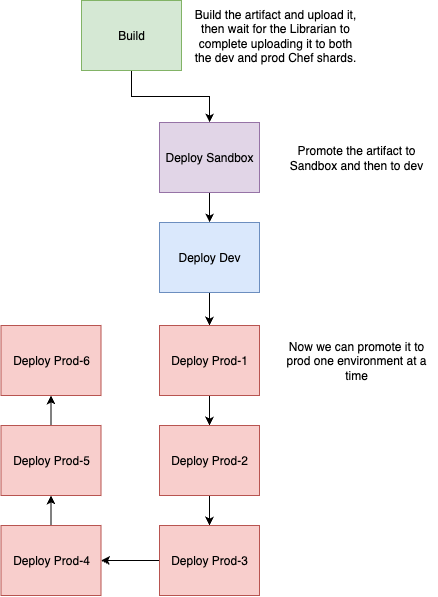
With this approach, we promote the latest cookbook changes to the sandbox environments at the top of the hour. These changes are then managed by a Kubernetes cron job and rolled out to the dev environments at the top of the hour, and finally begin rolling out to production environments starting at 30 minutes past the hour.
prod-1 is treated as our canary production environment. It receives updates every hour (assuming there have been new changes merged into the cookbooks) to ensure that changes are regularly exercised in a real production setting – alongside our sandbox and dev environments. This enables us to catch production-impacting issues early and in smaller, safer increments.
Changes to prod-2 through prod-6 are rolled out using a release train model. Before a new version is deployed to prod-2, we ensure the previous version has successfully progressed through all production environments up to prod-6. This staggered rollout minimises blast radius and gives us the opportunity to catch regressions earlier in the release train.
If we waited for a version to pass through all environments before updating prod-1 – as we do with prod-2 onward – we’d end up testing artifacts with large, cumulative changes. By contrast, updating prod-1 frequently with the latest version allows us to detect issues closer to when they were introduced.
Here’s an example showing how artifact version A moves through each environment in this release cycle:
Hour X:00
Sandbox ---> Version A (Latest)
Dev ---> Version A (Latest)
Prod-1 (no change - currently at version Z)
Prod-2 (no change - currently at version Z)
Prod-3 (no change - currently at version Z)
Prod-4 (no change - currently at version Z)
Prod-5 (no change - currently at version Z)
Prod-6 (no change - currently at version Z)
Hour X:30
(Now that Prod-2 to Prod-6 are all on the same version, we’ll begin updating them again)
Sandbox (no change - currently at version A)
Dev (no change - currently at version A)
Prod-1 ---> Version A (dev version) Prod-2 ---> Version A (prod-1 version)
Prod-3 (no change - currently at version Z)
Prod-4 (no change - currently at version Z)
Prod-5 (no change - currently at version Z)
Prod-6 (no change - currently at version Z)
Someone committed a change, resulting in the creation of a new artifact called B.
Hour (X + 1):00
Sandbox ---> Version B (Latest)
Dev ---> Version B (Latest)
Prod-1 (no change - currently at version A)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version Z)
Prod-4 (no change - currently at version Z)
Prod-5 (no change - currently at version Z)
Prod-6 (no change - currently at version Z)
Hour (X + 1):30
Sandbox (no change - currently at version B)
Dev (no change - currently at version B)
Prod-1 ---> Version B (dev version)
Prod-2 (no change - currently at version A)
Prod-3 ---> Version A (prod-2 version)
Prod-4 (no change - currently at version Z)
Prod-5 (no change - currently at version Z)
Prod-6 (no change - currently at version Z)
Someone committed a change, resulting in the creation of a new artifact called C.
Hour (X + 2):00
Sandbox ---> Version C (Latest)
Dev ---> Version C (Latest)
Prod-1 (no change - currently at version B)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version A)
Prod-4 (no change - currently at version Z)
Prod-5 (no change - currently at version Z)
Prod-6 (no change - currently at version Z)
Hour (X + 2):30
Sandbox (no change - currently at version C)
Dev (no change - currently at version C)
Prod-1 ---> Version C (dev version)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version A)
Prod-4 ---> Version A (prod-3 version)
Prod-5 (no change - currently at version Z)
Prod-6 (no change - currently at version Z)
Someone committed a change, resulting in the creation of a new artifact called D.
Hour (X + 3):00
Sandbox ---> Version D (Latest)
Dev ---> Version D (Latest)
Prod-1 (no change - currently at version C)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version A)
Prod-4 (no change - currently at version A)
Prod-5 (no change - currently at version Z)
Prod-6 (no change - currently at version Z)
Hour (X + 3):30
Sandbox (no change - currently at version D)
Dev (no change - currently at version D)
Prod-1 ---> Version D (dev version)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version A)
Prod-4 (no change - currently at version A)
Prod-5 ---> Version A (prod-4 version)
Prod-6 (no change - currently at version Z)
Someone committed a change, resulting in the creation of a new artifact called E.
Hour (X + 4):00
Sandbox ---> Version E (Latest)
Dev ---> Version E (Latest)
Prod-1 (no change - currently at version D)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version A)
Prod-4 (no change - currently at version A)
Prod-5 (no change - currently at version A)
Prod-6 (no change - currently at version Z)
Hour (X + 4):30
Sandbox (no change - currently at version E)
Dev (no change - currently at version E)
Prod-1 ---> Version E (dev version)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version A)
Prod-4 (no change - currently at version A)
Prod-5 (no change - currently at version A)
Prod-6 ---> Version A (prod-5 version)
Someone committed a change, resulting in the creation of a new artifact called F.
Hour (X + 5):00
Sandbox ---> Version F (Latest)
Dev ---> Version F (Latest)
Prod-1 (no change - currently at version E)
Prod-2 (no change - currently at version A)
Prod-3 (no change - currently at version A)
Prod-4 (no change - currently at version A)
Prod-5 (no change - currently at version A)
Prod-6 (no change - currently at version A)
Now that Prod-2 to Prod-6 are all on the same version, we’ll begin updating them again and this cycle will continue till the end of time.
Hour (X + 5):30
Sandbox (no change - currently at version F)
Dev (no change - currently at version F)
Prod-1 ---> Version F (dev version)
Prod-2 ---> Version F (prod-1 version)
Prod-3 (no change - currently at version A)
Prod-4 (no change - currently at version A)
Prod-5 (no change - currently at version A)
Prod-6 (no change - currently at version A)
As you can see above, changes now take a bit longer to roll out across all our production nodes. However, this delay provides valuable time between deployments across different availability zones, allowing us to catch and address any issues before problematic changes are fully propagated.
By introducing split production environments (e.g., prod-1 to prod-6), we’ve been able to sidestep the old problem of new nodes pulling in a bad config the moment they came online. Now, each node is tied to the environment for its AZ, and changes roll out gradually instead of everywhere at once. That means if something goes wrong in one AZ, we can keep scaling safely in the others while we fix the issue.
It’s a much more resilient setup than before – we’ve taken away the single point of failure and built in guardrails that make the whole system safer and more predictable.
What changed in the way we trigger Chef?
Now that we have multiple production Chef environments, each one receives updates at different times. For example, if a version is currently in the middle of being rolled out, the next version must wait until that rollout is fully completed across all production environments. On the other hand, when there are no updates in progress, a new version can be rolled out to all environments more quickly.
Because of this variability, triggering Chef via a fixed cron schedule is no longer practical – we can’t reliably predict when a given Chef environment will receive new changes. As a result, we’ve moved away from scheduled runs and instead built a new service that triggers Chef runs on nodes based on signals. This service ensures Chef only runs when there are actual updates available, improving both safety and efficiency.
Chef Summoner

If you remember from my previous blog post, we built a service called Chef Librarian that watches for new Chef cookbook artifacts and uploads them to all of our Chef stacks. It also exposes an API endpoint that allows us to promote a specific version of an artifact to a given environment.
We recently enhanced Chef Librarian to send a message to an S3 bucket whenever it promotes a version of an artifact to an environment. The contents of that S3 bucket look like this:
agunasekara@z-ops-agunasekara-iad-dinosaur:~ >> s3-tree BUCKET_NAME
BUCKET_NAME
└── chef-run-triggers ├── basalt │ ├── ami-dev │ ├── ami-prod │ ├── dev │ ├── prod │ ├── prod-1 │ ├── prod-2 │ ├── prod-3 │ ├── prod-4 │ ├── prod-5 │ ├── prod-6 │ └── sandbox └── ironstone ├── ami-dev ├── ami-prod ├── dev ├── prod ├── prod-1 ├── prod-2 ├── prod-3 ├── prod-4 ├── prod-5 ├── prod-6 └── sandbox
Under the chef-run-triggers key, we maintain a nested structure where each key represents one of our Chef stacks. Within each stack key, there are additional keys for each environment name.
Each of these environment keys contains a JSON object with contents similar to the example below:
{ "Splay": 15, "Timestamp": "2025-07-28T02:02:31.054989714Z", "ManifestRecord": { "version": "20250728.1753666491.0", "chef_shard": "basalt", "datetime": 1753666611, "latest_commit_hash": "XXXXXXXXXXXXXX", "manifest_content": { "base_version": "20250728.1753666491.0", "latest_commit_hash": "XXXXXXXXXXXXXX", "author": "Archie Gunasekara <agunasekara@slack-corp.com>", "cookbook_versions": { "apt": "7.5.23", ... "aws": "9.2.1" }, "site_cookbook_versions": { "apache2": "20250728.1753666491.0", ... "squid": "20250728.1753666491.0" } }, "s3_bucket": "BUCKET_NAME", "s3_key": "20250728.1753666491.0.tar.gz", "ttl": 1756085811, "upload_complete": true }
}
Next, we built a service called Chef Summoner. This service runs on every node at Slack and is responsible for checking the S3 key corresponding to the node’s Chef stack and environment. If a new version is present in the signal sent out by Chef Librarian, the service reads the configured splay value and schedules a Chef run accordingly.
The splay is used to stagger Chef runs so that not all nodes in a given environment and stack try to run Chef at the same time. This helps avoid spikes in load and resource contention. We can also customize the splay depending on our needs – for example, when we trigger a Chef run using a custom signal from Librarian and want to spread the runs out more intentionally.
However, if no changes are merged and no new Chef artifacts are built, Librarian has nothing to promote, and no new signals are sent out. Despite that, we still need to ensure Chef runs at least once every 12 hours to maintain compliance and ensure nodes stay in their expected configuration state. So, Chef Summoner will also run Chef at least once every 12 hours, even if no new signals have been received.
The Summoner service keeps track of its own state locally – this includes things like the last run time and the artifact version used – so it can compare any new signals with the most recent run and determine whether a new Chef run is required.
The overall flow looks like this:
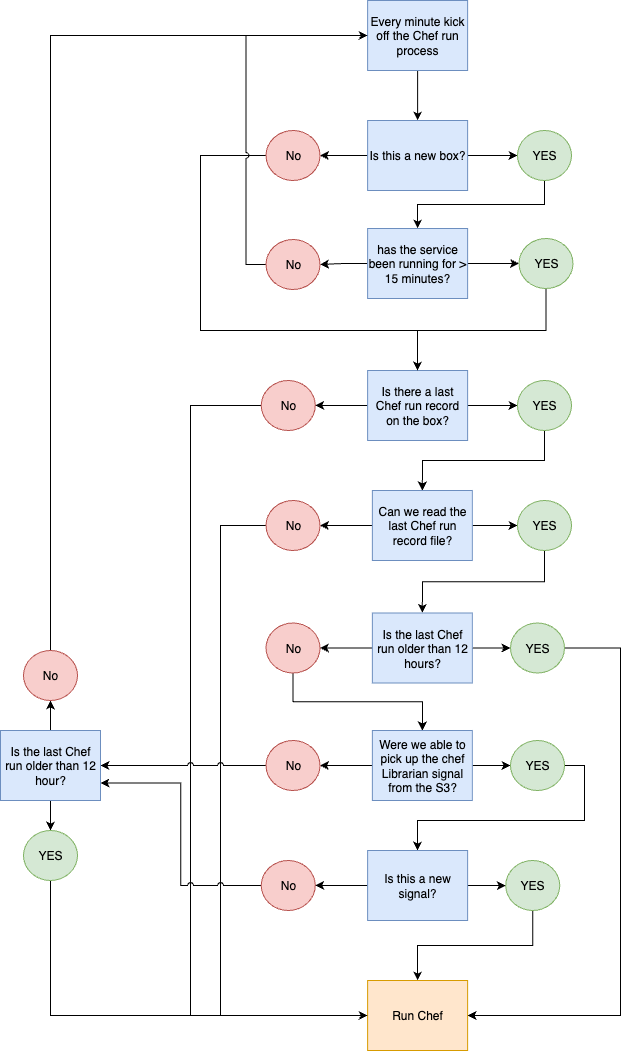
Now that Chef Summoner is the primary mechanism we rely on to trigger Chef runs, it becomes a critical piece of infrastructure. After a node is provisioned, subsequent Chef runs are responsible for keeping Chef Summoner itself up to date with the latest changes.
But if we accidentally roll out a broken version of Chef Summoner, it may stop triggering Chef runs altogether – making it impossible to roll out a fixed version using our normal deployment flow.
To mitigate this, we bake in a fallback cron job on every node. This cron job checks the local state that Chef Summoner stores (e.g., last run time and artifact version) and ensures Chef has been run at least once every 12 hours. If the cron job detects that Chef Summoner has failed to run Chef in that timeframe, it will trigger a Chef run directly. This gives us a recovery path to push a working version of Chef Summoner back out.
In addition to this safety net, we also have tooling that allows us to trigger ad hoc Chef runs across the fleet or a subset of nodes when needed.
What’s Next?
All of these recent changes to our EC2 ecosystem have made rolling out infrastructure changes significantly safer. Teams no longer have to worry about a bad update impacting the entire fleet. While we’ve come a long way, the platform is still not perfect.
One major limitation is that we still can’t easily support service-level deployments. In theory, we could create a dedicated set of Chef environments for each service and promote artifacts individually – but with the hundreds of services we operate at Slack, this quickly becomes unmanageable at scale.
With that in mind, we’ve decided to mark our legacy EC2 platform as feature complete and move it into maintenance mode. In its place, we’re building a brand-new EC2 ecosystem called Shipyard, designed specifically for teams that can’t yet move to our container-based platform, Bedrock.
Shipyard isn’t just an iteration of our old system – it’s a complete reimagining of how EC2-based services should work. It introduces concepts like service-level deployments, metric-driven rollouts, and fully automated rollbacks when things go wrong.
We’re currently building a Shipyard and targeting a soft launch this quarter, with plans to onboard our first two teams for testing and feedback. I’m excited to share more about Shipyard in my next blog post – stay tuned!