深入了解 GPT-OSS:OpenAI 最新的 LLM 架构
[
[

Press enter or click to view image in full size
按回车或点击以查看完整图像
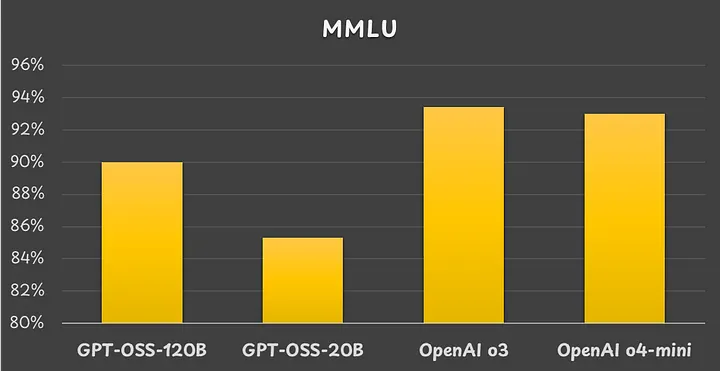
Massive Multitask Language Understanding (MMLU) benchmark results. Image by the author.
大规模多任务语言理解(MMLU)基准结果。图片由作者提供。
It has been several years since OpenAI shared information about how its LLMs work. Despite the word “open” in its name, OpenAI has not yet disclosed the inner workings of GPT-4 and GPT-5.
自从OpenAI分享有关其LLM工作原理的信息以来已经过去了好几年。尽管其名称中有“开放”一词,但OpenAI尚未披露GPT-4和GPT-5的内部工作原理。
However, with the release of the open-weight GPT-OSS models, we finally have new information about OpenAI’s LLM design process.
然而,随着开放权重的GPT-OSS模型的发布,我们终于获得了关于OpenAI的LLM设计过程的新信息。
To learn about the latest state-of-the-art LLM architecture, I recommend studying OpenAI’s GPT-OSS.
要了解最新的最先进的LLM架构,我建议研究OpenAI的GPT-OSS。
Overall LLM Model Architecture
整体LLM模型架构
To fully understand the LLM architecture, we must review OpenAI’s papers on GPT-1 [1], GPT-2 [2], GPT-3 [3], and GPT-OSS [4].
要全面理解LLM架构,我们必须回顾OpenAI的关于GPT-1 [1]、GPT-2 [2]、GPT-3 [3]和GPT-OSS [4]的论文。
The overall LLM model architecture can be summarized as follows:
整体LLM模型架构可以总结如下:
Press enter or click to view image in full size
按回车或点击以查看完整图像
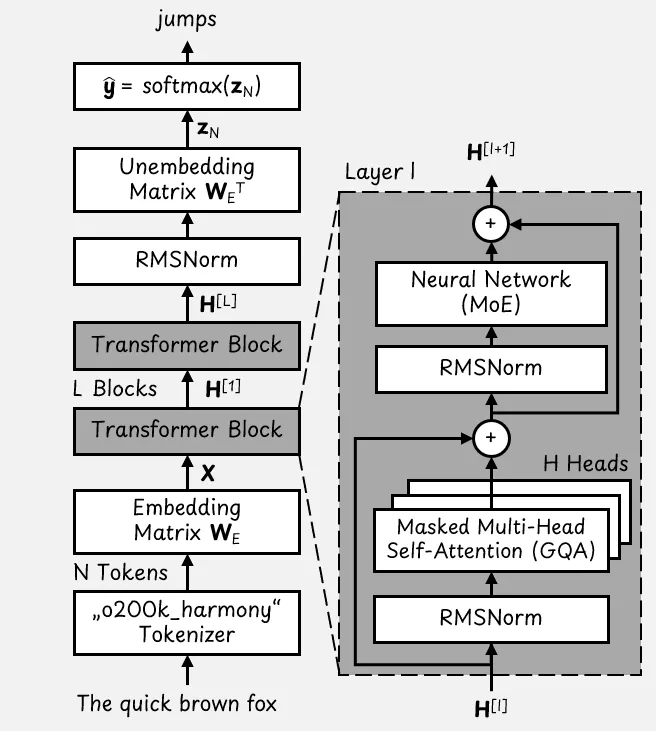
The basic GPT-OSS Transformer architecture. Image adapted from [5]
基本的GPT-OSS Transformer架构。图像改编自[5]
Based on this figure, we start at the bottom with an example input sentence, “The quick brown fox”. The goal of the LLM is to predict the next token, which could be “jumps”.
根据这个图,我们从底部开始,以一个示例输入句子“快速的棕色狐狸”作为起点。LLM的目标是预测下一个标记,可能是“跳跃”。
Tokenization
标记化
First, the tokenizer converts the input sentence into a list of N tokens. The o200k_harmony tokenizer is based on the byte pair encoding (BPE) algorithm [6] and has a vocabulary of 201,088 tokens.
首先,分词器将输入句子转换为 N 个令牌的列表。o200k_harmony 分词器基于字节对编码(BPE)算法 [6],并具有 201,088 个令牌的词汇表。
This means that each token is a one-hot vec...