Automated Schema Evolution in Pinterest’s Next-Generation DB Ingestion Framework
[
Pinterest Engineering Blog
](https://medium.com/pinterest-engineering?source=post_page---publication_nav-4c5a5f6279b6-36c5c07070de---------------------------------------)
[

](https://medium.com/pinterest-engineering?source=post_page---post_publication_sidebar-4c5a5f6279b6-36c5c07070de---------------------------------------)
Inventive engineers building the first visual discovery engine, 300 billion ideas and counting.
Yisheng Zhou | Software Engineer II
Liang Mou | Sr Staff Software Engineer
Gabriel Raphael Garcia Montoya | Staff Software Engineer
Istvan Podor | Staff Software Engineer

Introduction
In the first post of this series, we introduced Pinterest’s next-generation CDC-based ingestion platform built on Kafka, Flink, Spark, and Iceberg. In production, upstream schemas are constantly evolving, and in a distributed CDC pipeline, schema is not just metadata — it is a cross-system contract spanning ingestion, transformation, storage, and historical backfill. A schema change that is not handled carefully can break Flink jobs, block Spark upserts, or create inconsistencies between online and offline representations.
This post walks through how we make schema evolution safe in practice: the onboarding model it builds on, the changes we support and the tradeoffs we accept, how updates propagate across the stack, and how we monitor and recover when things go wrong. We end with where we’re heading next — zero-gap schema evolution.
Background & Motivation
Schema evolution was particularly challenging in our environment because our ingestion pipeline is composed of multiple tightly related stages, each of which depends on schema in a different way. A single table onboarding flow spans CDC source configuration, Kafka provisioning, Flink and Spark code generation, Iceberg CDC and base table creation, and historical bootstrap — all driven by the same schema. Once a source schema changes, that change must be reflected across code, metadata, and storage in a controlled and auditable way.
Without a unified automation framework, manual updates across these layers increase the risk of drift, failed deployments, and inconsistent datasets. We therefore needed a way to make schema evolution safe, repeatable, and scalable.
Our Solution: SLA-Based Automated Schema Evolution
To address this problem, we built an automated schema evolution framework on top of our CDC ingestion platform, providing:
- automated propagation of supported schema changes across Kafka, Flink, Spark, and Iceberg
- PR-based rollout with versioning and auditing
- SLA-based eventual consistency between online and offline schemas
- clear recovery paths for unsupported or ambiguous cases
A core design principle is that schema evolution is not treated as an atomic operation. Instead, we treat it as a multi-stage convergence process across the control plane and data plane, which lets us preserve pipeline availability while gradually restoring schema and data correctness.
Architecture Overview
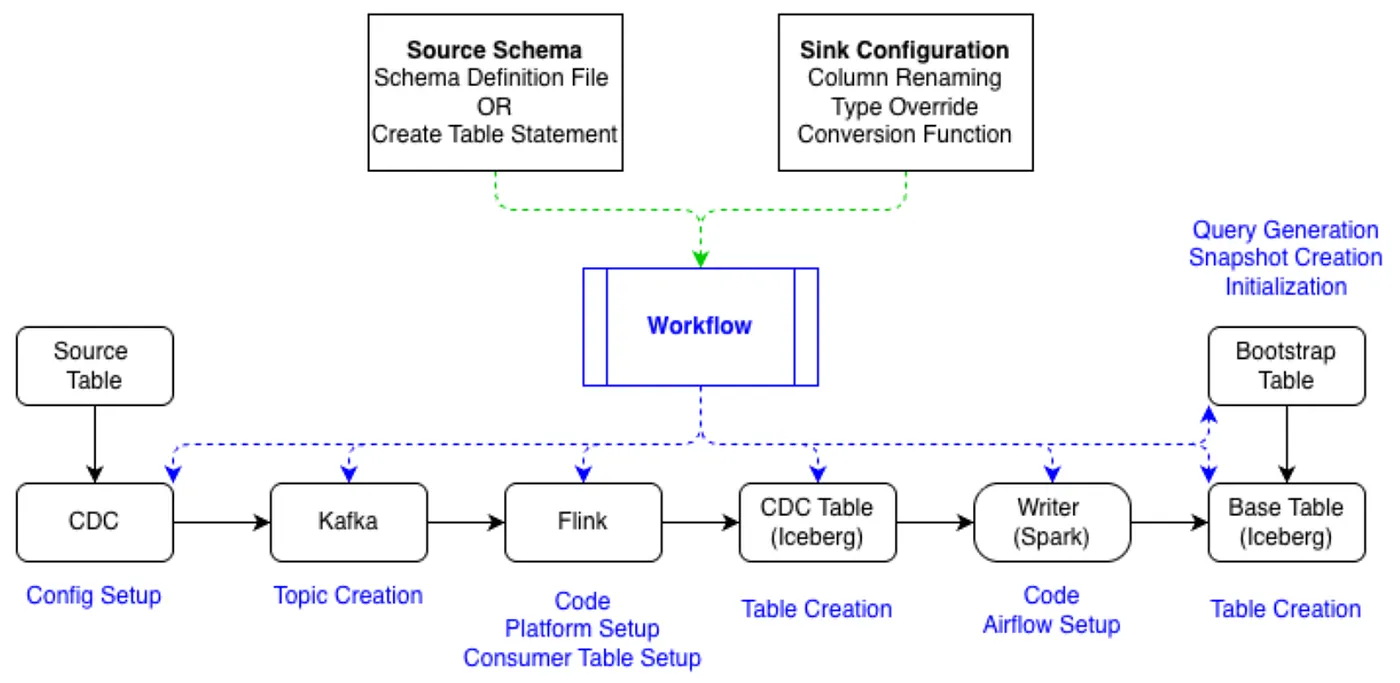
The underlying data flow remains the same as in Part 1

Each stage relates to schema differently. The CDC layer emits raw row updates; Kafka transports them. Flink parses source records and applies type conversion or custom transformation logic before writing to the CDC Iceberg table. Spark periodically reads the CDC table and upserts into the base Iceberg table, while bootstrap jobs load historical data so the base table can be initialized without data loss.
A source schema change is therefore not just a DDL update. It requires updates to generated Flink code, Spark writer logic, Iceberg table definitions, bootstrap queries, and pipeline metadata.
Onboarding
Automated schema evolution depends on a reliable onboarding model. For many tables, we rely on a dedicated schema definition file as the source of truth. Each column is defined with a name, a type, and a stable numeric identifier that persists across revisions, which lets us track columns unambiguously even when fields are reordered or renamed.
Other tables expose only a CREATE TABLE statement. This works for initial setup but is less reliable for schema diffing because it lacks stable identifiers — a textual change could signify a rename, a destructive drop-and-add, or a broader semantic reorganization. We discuss how we resolve this ambiguity in the Unsupported and Edge Cases section.
On top of the source schema, we maintain a sink configuration that defines how online fields map to offline representations — column renaming, type overrides, and conversion functions to Iceberg-compatible types (for example, a created_at BIGINT in epoch milliseconds can be mapped to an Iceberg TIMESTAMP via a built-in conversion function).
Using this schema and sink configuration, our automated workflow generates Flink transformation code, Spark writer code, Iceberg CDC and base table definitions, and the associated onboarding and bootstrap queries, along with the supporting setup across each pipeline stage. The same code and schema generation logic is reused during schema evolution, which guarantees that an evolved table produces the same artifacts it would have if onboarded fresh — eliminating drift between the onboarding and evolution paths.
Supported Schema Changes
Not all schema changes are equally safe in a distributed CDC system. To keep the system reliable and operationally manageable, we intentionally restrict automated schema evolution to additive changes:
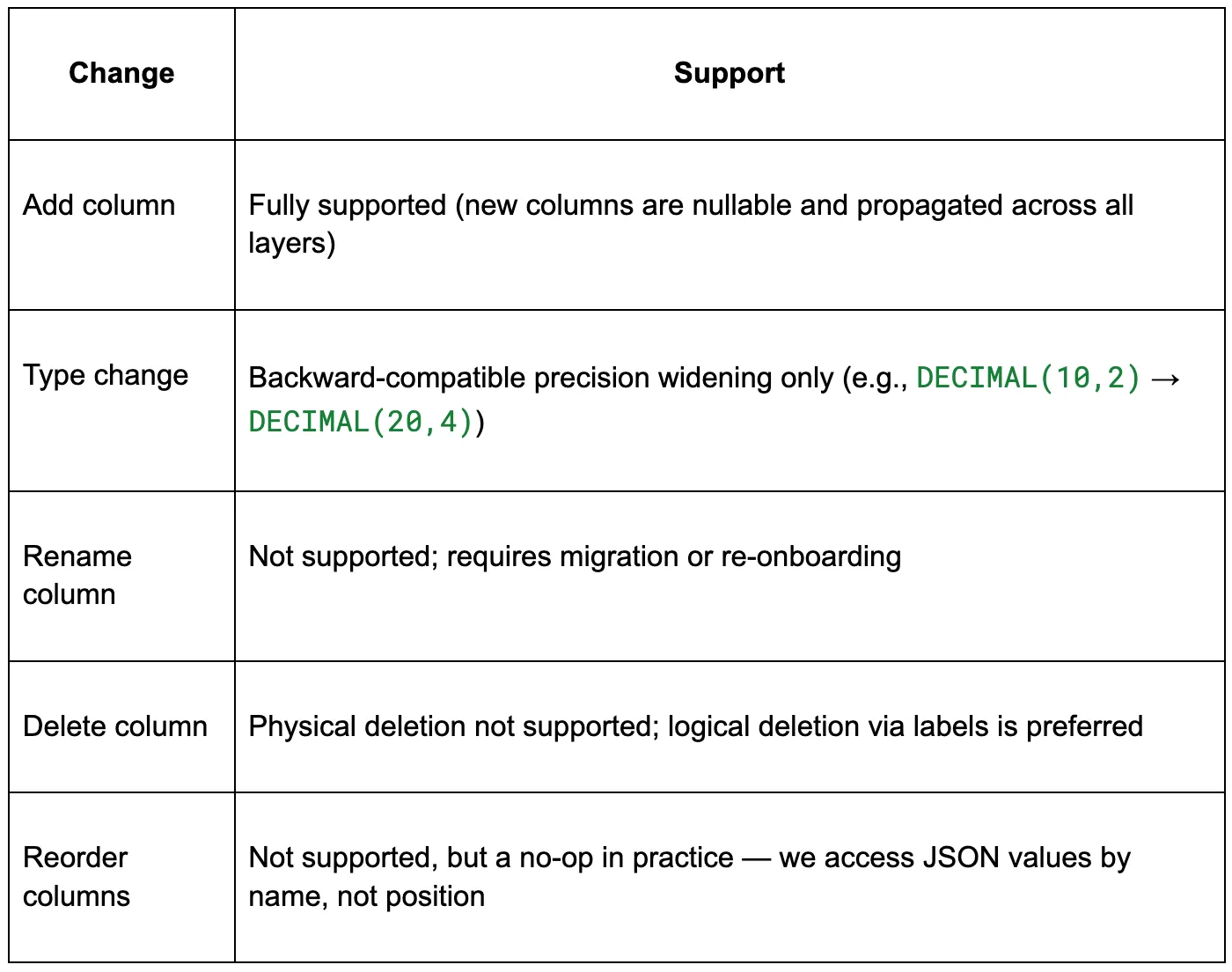
This is a deliberate tradeoff. Additive-only changes preserve backward compatibility, avoid historical replay complexity, and minimize the risk of breaking existing consumers.
Type changes are particularly risky because they can introduce incompatibility across parsing logic, storage schema, and downstream consumers. We therefore allow only a narrow subset where semantic meaning is unchanged — primarily numeric precision widening, which doesn’t require reinterpretation of existing data or rewriting historical records. All other type changes (e.g., STRING → INT, narrowing precision, lossy conversions) require coordinated migration or full backfill and are handled outside the schema evolution workflow.
For unsupported changes, more disruptive cases like new primary keys or columns with default values can still be handled through migration or re-onboarding. To prevent unsupported changes from entering the pipeline accidentally, we run automated schema change PR checks as part of the workflow.
How Schema Evolution Works
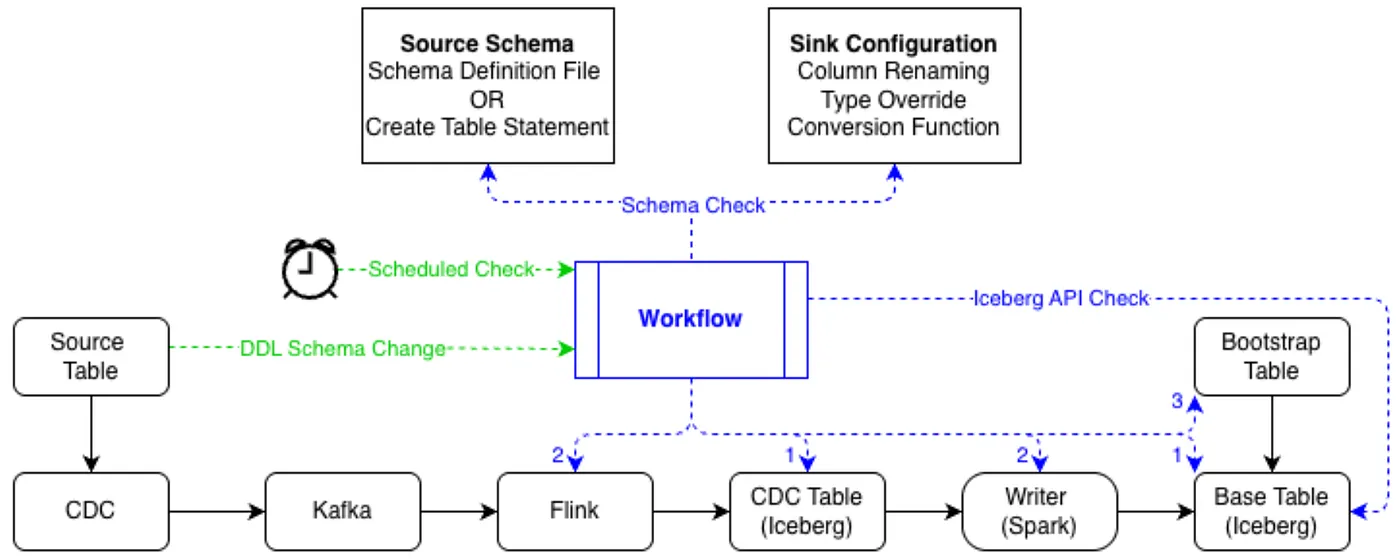
The system detects upstream schema changes through two complementary mechanisms. In the push-based path, an upstream schema update generates a DDL CDC message that triggers a workflow comparing the new schema against current Iceberg table metadata via the Iceberg catalog API; if a supported difference is found, schema evolution is invoked automatically. In the pull-based path, a daily comparison job independently checks online schemas against their offline counterparts and triggers evolution on drift. Push-based detection enables low-latency response, while pull-based detection serves as a safety net for anything missed.
Once triggered, the workflow updates the Iceberg schemas for the CDC and base tables, regenerates Flink and Spark code from the latest schema and sink configuration, updates version metadata for auditing, refreshes the create and bootstrap queries, and opens a PR so all changes are reviewable. Raw consumer tables don’t need to change — they consume the raw payload, so the schema-aware parts of the pipeline begin at the transformation and offline storage layers.
All schema evolution changes flow through this PR-based workflow, which gives us auditability, versioning, and a safer operational model.
A Three-Phase Convergence Model
A key idea in our design is that schema evolution happens in phases rather than all at once:
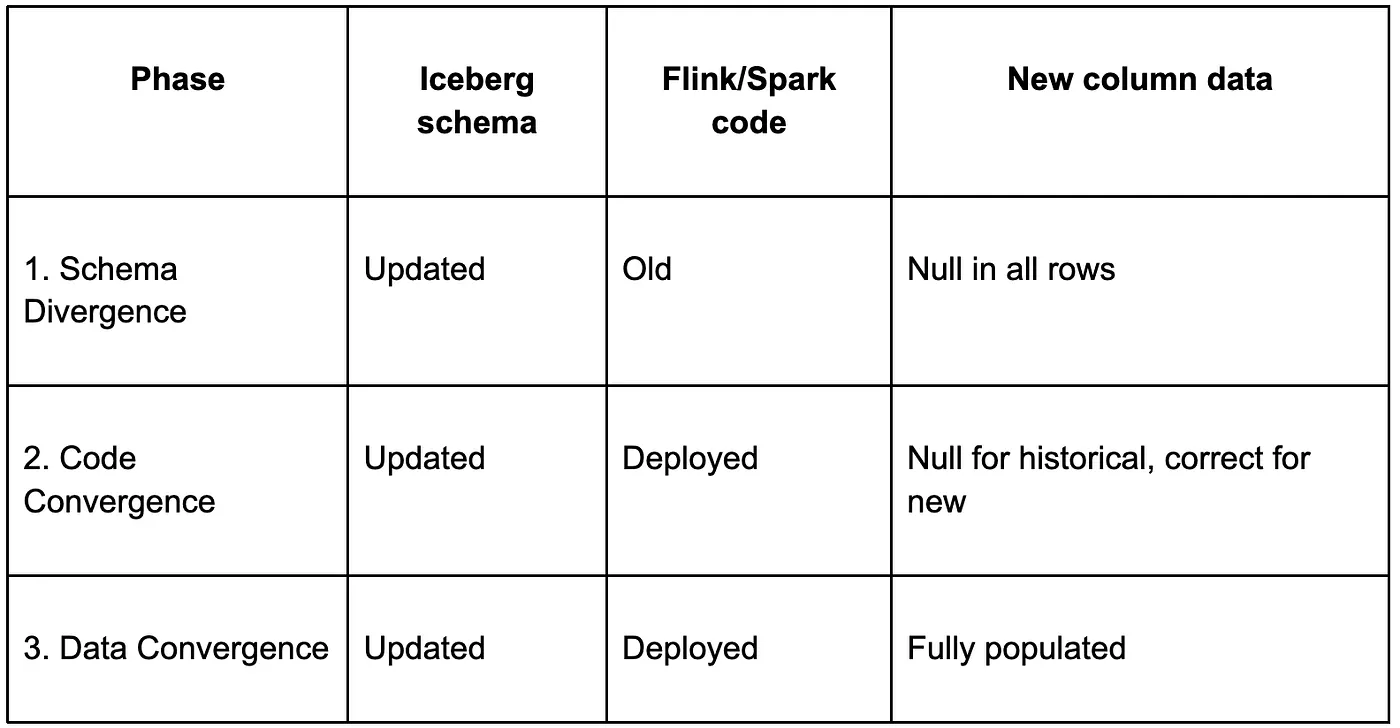
Phase 1: Schema Divergence. The Iceberg schemas are updated first. Because our generated Flink and Spark code selects columns by name rather than position, and Iceberg treats newly added columns as nullable with a default of null, existing jobs continue running without failure — they simply write null for the new column until the parsing logic is deployed.
Phase 2: Code Convergence. The updated Spark and Flink code is rolled out. Spark is updated first so backfill can begin from the relevant watermark timestamp; Flink is then updated so new incoming records are parsed and written correctly.
Phase 3: Data Convergence. Spark backfills historical data if needed, Flink processes new data correctly, and the base table converges to the latest online schema and content.
Get Pinterest Engineering’s stories in your inbox
Join Medium for free to get updates from this writer.
This staged approach decouples schema propagation from data correctness. Instead of forcing the entire system to change atomically, we allow temporary divergence within a bounded SLA and use deployment sequencing to restore full consistency.
SLA and Deployment Strategy
An SLA-based model is acceptable at Pinterest because schema changes are not usually consumed in real time — what matters is that the new schema becomes available within a predictable, operationally safe window.
Spark deployment follows a standard code deployment model; table changes are persisted in the intermediate CDC tables, so they won’t be lost. Flink deployment is more sensitive because a failed Flink job combined with Kafka retention expiration could result in data loss. To mitigate this, we deploy Flink through CI/CD with a staging validation step: the workflow first updates a staging pipeline (Kafka → Flink → CDC table), and once verified, applies the production table change and deploys to production.
There’s also a pull-based daily comparison that serves a dual purpose: if schema differences are detected, evolution is triggered automatically; if not, the same workflow performs routine maintenance such as small-file compaction for merge-on-read tables.
Unsupported and Edge Cases
Columns with Default Values. The source system may not emit CDC events for historical rows. Recovery: perform a manual bootstrap and roll back the Spark watermark to backfill missing values.
Sensitive Data Changes in Non-Sensitive Pipelines. Adding a sensitive column to a non-sensitive pipeline is blocked. The change requires migration to a secured pipeline.
Primary Key Changes. Primary keys affect deduplication semantics of the CDC table. We automate parts of this process, but edge cases — such as column name conflicts with reserved raw-data fields — may require manual intervention.
Ambiguous CREATE TABLE Diffs. Self-serve MySQL schemas declare each table via a standalone CREATE TABLE definition in a centralized repository. Because this artifact lacks stable column identifiers, a textual change may represent a rename, a delete-plus-add, or another semantic rewrite. Rather than inferring intent from the file, we resolve ambiguity using a two-layer strategy:
- Build time: A guardrail instantiates the previous schema in a temporary environment and uses Skeema to derive the intended ALTER statement, preventing dangerous transitions before code integration.
- Deployment time: An audit mechanism captures the full execution context — replicaset, hostname, resolved ALTER, a normalized before/after schema diff, and the originating PR number — and persists it to a dedicated service table exposed through a REST API.
The audit trail is grounded in the database’s actual DDL history. In MySQL specifically, DDL statements are written to the binlog as statement events even when binlog_format=ROW, giving a faithful record of what was executed. When a textual CREATE TABLE diff is ambiguous, we resolve it against this audit trail rather than re-inferring intent from the file.
Concurrent Schema Changes. Only one workflow runs at a time. Subsequent changes are queued and processed sequentially, preventing race conditions and guaranteeing serialized convergence.
Column Transformations: Some use cases require transformations to be applied to the content of a column before it is ingested into the sink Iceberg table (ex: unix timestamp to ISO timestamp). We handle these by annotating the online schema with transformations that need to be applied in the offline pipeline, and inject data transformation functions into the ingestion pipeline that convert the data into the expected format.
Error Handling and Recovery
Spark Failures. Because Spark is watermark-based, the next successful run resumes from the previous watermark and backfills the missing interval.
Flink Parsing Failures. If generated Flink code cannot run, CI/CD blocks the rollout. Engineers inspect the Flink logs and fix the parsing issue before deployment proceeds.
Full Recovery. When the automation fails, a customer needs a backfill within the SLA window, or new columns with default values cannot be reflected in CDC messages, we fall back to the onboarding system: select a source backup snapshot taken after the schema evolution point, override the base table with that snapshot, and roll back the Spark watermark. This restores consistency between online and offline tables.
Observability
Reliable schema evolution requires more than pipeline health checks. A job can be running while the data is still incomplete or incorrect.
For that reason, we monitor schema evolution through both system-level and data-quality signals.
Pipeline-level metrics include Kafka traffic health, Flink job health, Spark job health, and workflow execution health.
Schema and data-level metrics include schema evolution latency, Kafka-to-Flink lag, Spark watermark delay, and null column count.
These signals help us determine not only whether the pipeline is alive, but whether schema convergence is progressing as expected. They also provide triggers for fallback actions such as rollback or bootstrap-based recovery when needed.
Toward Zero-Gap Schema Evolution
Our current system provides SLA-based eventual consistency, but a temporary gap remains between schema update and full data correctness. We are exploring a design to eliminate it.
The core idea is a dynamic Iceberg sink that applies schema updates directly at the CDC table layer. If the source can parse newly added fields into a generic record, those fields can be written through a generic conversion path even before specialized Flink code is deployed, and the dynamic sink evolves the Iceberg schema automatically.
Unsupported types are routed to a dead-letter queue (DLQ) for manual backfill later. This approach reduces dependency on CI/CD for every schema change, at the cost of more complexity in runtime correctness and generic parsing. The design is currently waiting for a Flink version bump.
Conclusion & What’s Next
We built automated schema evolution into Pinterest’s CDC ingestion framework by treating schema as a cross-system contract and applying a staged convergence model across Kafka, Flink, Spark, and Iceberg. The current SLA-based design supports additive schema changes with bounded operational risk, clear recovery paths, and strong automation, and we continue investing in zero-gap evolution to further reduce manual effort and improve reliability.
In the following post, we will cover the incremental processing logic built on top of this ingestion framework and how we use it to support downstream use cases efficiently. Stay tuned for the future post: Incremental Processing on CDC Pipeline.
Acknowledgments
Huge thanks to my teammates Owen Zhang, Vi Nguyen, and Artem Tetenkin for building the Next Generation DB Ingestion at Pinterest together.
This project would not have been possible without the significant contributions and support of the following partners:
- Delivery Infra: Elly Chen, Sowmya Prakash, Bingxin Zhang, Jackie Xu
- Storage Services: Leonardo Marques Maciel Silva, Liqi Yi
- Storage Foundations: Tailin Lyu, Yu Su, John Grass
- Streaming/Batch Processing: Kevin Browne, Kanchi Masalia
- Big Data Storage: Pucheng Yang
- Big Data: Yi Pan
- Data Privacy: Keith Regier
- GitHub: Nathan Hilton
- Logging: Vahid Hashemian, Jeff Xiang, Jesus Zuniga
Special gratitude goes to Shardul Jewalikar, Ang Zhang, and Roger Wang for their continuous guidance, feedback, and support throughout the project.
Disclaimer
Apache®️, Apache Flink®️, Apache Iceberg®️, Apache Kafka®️, Apache Spark®️,and Kafka®️ are trademarks of the Apache Software Foundation (https://www.apache.org/).
Amazon®️, AWS®️, S3®️, and EC2®️ are trademarks of Amazon.com, Inc. or its affiliates.
Debezium®️ is a trademark of Red Hat, Inc.
MySQL®️ is a trademark of Oracle Corporation.
RocksDB®️ is a trademark of Meta Platforms, Inc. or its affiliates.
TiDB®️ is a trademarks of Beijing PingCAP Xingchen Technology and Development Co.
[

](https://medium.com/pinterest-engineering?source=post_page---post_publication_info--36c5c07070de---------------------------------------)
[

](https://medium.com/pinterest-engineering?source=post_page---post_publication_info--36c5c07070de---------------------------------------)Last published 12 hours ago
Inventive engineers building the first visual discovery engine, 300 billion ideas and counting.
[

](https://medium.com/@Pinterest_Engineering?source=post_page---post_author_info--36c5c07070de---------------------------------------)
[

](https://medium.com/@Pinterest_Engineering?source=post_page---post_author_info--36c5c07070de---------------------------------------)329 following
https://medium.com/pinterest-engineering | Inventive engineers building the first visual discovery engine https://careers.pinterest.com/