Defining Continual Learning
We are not short of attempts at achieving continual learning — self-distillation, real-time RL, memory scaffolds, replay methods, regularization, gradient projections, KL penalties, on-policy data, and countless more.
My complaint with a lot of these is that they are not even trying to solve the right problem.
This is my attempt to sketch out a principled, ambitious definition of continual learning in LLMs, grounded in both the classical ML literature and some of the discourse on the topic. I will also lay out my case for in-weights continual learning and lay out some of the open questions ahead.
TLDR: we are interested in an LLM being able to efficiently and compositionally learn new capabilities during sequential exposure to new, differently-distributed data, while at least preserving general capabilities.
This is part 1; soon we will share some exciting approaches we've been developing with @PrimeIntellect aimed at actually evaluating approaches using this principled definition.
A breakdown of the desiderata
The foundational problem at the core of continual learning (CL) is that of catastrophic forgetting — models trained on new task distributions exhibit worse performance on the old tasks. This challenge has been on the map since the late 1980s, when McCloskey and Cohen found that sequential learning can lead to catastrophic interference in connectionist models. This same phenomenon has been demonstrated with LLM fine-tuning, where improved performance on the fine-tuning domain degrades existing performance.
Herein comes the first clue for how we want our continual learning solution to look like:
1. Continually learning foundation models should, at least, preserve general performance when exposed to sparse new data.
Here, I am intentionally vague about the definition of general performance; the exact form will look differently in different applications. One could consider skills like general language ability, instruction following, logical and quantitative reasoning as necessary; people will disagree whether skills like coding and multilingual understanding belong here, but I want to disentangle these choices from the general requirement that there ought to be a large base of general capabilities that remains uncompromised after new learning.
The way that we have trained massive foundation models to be capable of solving a variety of tasks is by avoiding distribution shifts. Instead of sequential learning, we expose the model to large batches of data with roughly identical distribution in a multi-task learning setup, where data for a variety of tasks is represented in a single batch. This prevents catastrophic interference, as gradients are computed across the task distribution and weights pertaining to many tasks across the distribution are updated in the same optimizer step. However, with continual learning, we wish to transcend multi-task learning, and to be able to learn representations just as well from data becoming available sequentially (as it does in the real world). Therein comes the second tenet:
2. CL deals with sequential learning of tasks rather than simultaneous multi-task learning.
Furthermore, continual learning is about dealing with new data without specialized requirements on what this data should look like. We want a generalized way of learning an arbitrary amount and/or distribution of new data, without forgetting. Otherwise, even existing algorithms can trivially exhibit continual learning when the setup is maximally advantageous and we have plenty of data distributed almost identically. The distribution aspect, therefore, is a crucial requirement for any CL method worth its salt to handle, since the challenge of catastrophic forgetting occurs in the regime where the tasks being learned sequentially are different:
3. A model exhibiting CL should be able to learn from data of a different distribution than the model’s previous data distribution.
Returning to the question of the amount of new data, consider the following observation: your model can continually learn extremely scarce new data, if only you replay all of the data seen thus far plus the new data. Of course, this approach does not satisfy what we want to see with continual learning. We don’t want to replay trillions of tokens of pretraining data every time we train the model on yesterday’s conversations with a user. Therein comes the fourth desideratum of our platonic solution to continual learning:
4. Continual learning is fundamentally about efficiency, as infinite data and compute render internalizing new knowledge trivial.
A feature of multi-task (joint) training is that many tasks are seen at each training step, which helps the model build shared representations and generalize. When performing sequential learning, we want to match this baseline, and be able to generalize between skills learned at different time-points. In the CL literature, this is termed class-incremental learning — for example, training an image classifier to distinguish images from classes A and B first, followed by training it to distinguish between classes C and D, should result in a model capable not only of performing A-B and C-D classification, but one that generalizes to classifying between e.g. A and C, which were seen at different points in training. This requirements hints at cumulative and compositional nature of CL, which is our fifth requirement:
5. Continually learning models should be able to compose skills encountered at different stages of sequential training.
I believe these five to be the basis set of requirements for a continually-learning system able to adapt online to new information. There could be additional questions, such as whether to expand model capacity and grow new parameters every time we encounter new data — task-relevant heads, low-rank adapters, KV caches — while keeping the base weights of the model frozen. These methods are possible and appealing. For example, a method like Cartridges trains corpus-specific KV caches, which is a rather principled approach (since it does not expand model capacity in a way that does not already happen; KV caches are already not fixed), but at scale, it acts more like an external neural memory bank with unknown compositional properties (how do we use 1000 KV caches?). Dozens of LoRAs might be doable with a router, but still require infrastructure and optimizer innovations to be rendered usable, especially at scale. In principle, there could be reasonable ways to minimally expand model capacity over time to accommodate new connections, so I have not limited our CL problem definition to only a fixed set of weights.
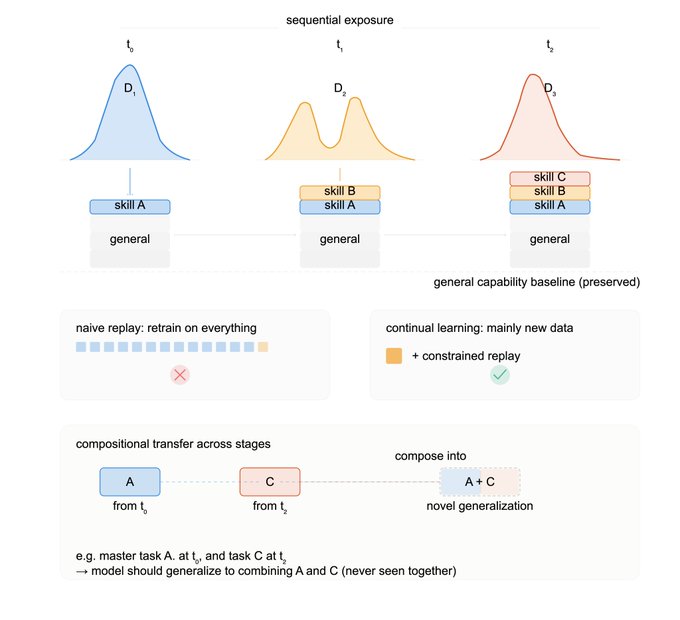
Figure 1: Visual overview of the definition. Top row outlines sequential exposure to novel data distributions while preserving general capability; middle row shows the efficiency requirement; bottom row highlights compositionality and positive transfer.
The case for parametric CL
Why do we want to go through the hassle of touching a model’s weights at all? Wouldn’t a harness effectively internalize new knowledge and skills (be it in .md files, a knowledge graph, a vector store, etc) and absolve us from dealing with continual learning in the weights?
Harness-based memory has distinct advantages: the new knowledge is readily available for inspection and editing, and the model can incorporate it in-context with excellent generalization by leveraging the superior in-context learning capabilities of LLMs. The only challenge is retrieving the right piece of information at the right time to inject it into the context, but this retrieval problem has been the subject of extensive research and we have plenty of options, from RAG to agentic navigation to skill discovery to RLMs.
Harness innovations notwithstanding, I see two primary reasons that in-weights learning might be a desirable primary driver of true effective continual learning.
Scaling. Storing knowledge in the harness can yield impressive results, but the fixed nature of the underlying LLM places a hard ceiling. A key desire in online learning is that your skill tree should scale constructively, not destructively; you want the model to get smarter as it learns more, and not dumber. With harness-based memory approaches, growing a skill tree results in diminishing returns and potentially even performance degradation. For example, when your set of skill files or memory markdowns grows to hundreds or thousands, you begin suffering from context rot and/or retrieval difficulties. At scale, discovery mechanisms might mitigate this, but the fixed nature of the model prevents any net-positive accumulation of knowledge, skills, or wisdom. A model of roughly the same intrinsic intelligence would operate over an increasingly growing bank of knowledge. In contrast, parametric knowledge fundamentally changes the amount of intelligence per forward pass, which holds significantly greater compounding potential.
Automaticity. Neural memory is advantageous in allowing hyper-efficient automatic recombination of knowledge, which is a prerequisite for flexible compositionality. Of course, an LLM can exhibit compositionality over in-context information, but as the knowledge bank grows, compositional ability reduces to the lowest common denominator of how good the retriever is. Creativity requires intuitive recombination of knowledge from different domains, often in ways not obvious enough to be amenable to intentional retrieval. Consider, for instance, how neural pretrained knowledge of programming can assist with general, non-code reasoning, while retrieving quality code snippets would hardly exhibit the same effect. At a high level, internalized neural knowledge of coding has created some generalizable representations that automatically aid reasoning, without reliance on interventions higher on the abstraction ladder. The goal of internalizing new data into the weights is to promote this kind of automaticity, so that new connections are made intentionally without relying on the bottleneck of retrieval and context rot.
Open questions
Scaffold training. Parametric learning is difficult and untransparent, whereas scaffolds are intuitive and still amenable to improvements in the way the models use them. Agentic RL training of LLMs with a harness is a form of parametric learning that still utilizes a harness to achieve the desired memory functionality. Many believe in isolating the LLM’s “cognitive core” by stripping away all the encyclopedic memorized knowledge, and train this core to effectively use external harnesses to access knowledge when needed. These approaches have shown promising results, and it remains to be seen if CL with the aforementioned desirable properties can be achieved this way, without dealing with the difficulties of modifying a model’s weights.
Overwriting knowledge. Sequentially learning new knowledge will inevitably result in contradictory data being introduced, possibly due to a change in the state of the environment. How is this data integrated, and how adaptable do we want the model to be? If the syntax for a software library changes, we’d likely want the model to adapt quickly; if an article disputing the second law of thermodynamics is presented to the model, we want to prevent overwriting centuries of physics knowledge. Navigating this complexity is not unique to parametric methods, but it requires some thought on the meta-optimization layer (what are the right ways to continually learn?).
Data efficiency. Most parametric methods of incorporating knowledge are less sample-efficient than ICL — whereas merely inserting a SKILL file in context is enough to prepare an agent to use it, internalizing it into the weights would likely require bootstrapping a synthetic dataset based on the skill to augment the limited content available. The generation of useful synthetic datasets can therefore be considered to be a subset of the continual learning problem, unless/until more data-efficient methods for weight updates are introduced. This introduces questions about the quality, diversity and trustworthiness of the augmented data, and applicability to frontier models and difficult skills.
Benchmarking continual learning
Stay tuned for part 2 :)