Zero-Downtime PyTorch Upgrade in Production: Approaches, Pitfalls and Lessons
Chi Zhang | Staff Software Engineer, ML Platform
Chen Yang | Sr. Staff Machine Learning Engineer, Applied Science; Lida Li | Sr. Staff Software Engineer, Ads ML Infrastructure
Pong Eksombatchai | (former) Principal Machine Learning Engineer, Applied Science; Saurabh Vishwas Joshi | Principal Engineer, ML Platform
Eric Lopez | Staff Site Reliability Engineer, Production Engineering; Mark Molinaro | Staff Software Engineer, Code and Language Runtime
Introduction
At Pinterest, machine learning (ML) models power real-time recommendations in core experiences as well as advertising at web scale. Behind the scenes, PyTorch is the de facto ML framework, enabling both distributed training and online inference across GPU fleets.
By early 2025, Pinterest production was still running PyTorch 2.1 (October 2023) on CUDA 12.1. The more-than-a-year lag meant we were missing several important improvements introduced across subsequent PyTorch 2.x releases, including more capable torch.compile and TorchInductor compiler stack, better support for modern GPU architectures like Nvidia Hopper, and maturing training efficiency features such as FP8 training. To avoid falling behind that rapidly moving baseline, we set an explicit goal to upgrade our production stack from PyTorch 2.1 to 2.6 (January 2025), bringing the Pinterest ML ecosystem onto a more modernized release.
In an earlier blog post, we shared learnings about identifying and debugging system-level bottlenecks on the training platform amid the upgrade. This article is the companion story from the online serving perspective: it is a journey of upgrading critical dependencies (notably CUDA and DCGM), working around breaking changes, resolving TorchScript incompatibilities, and rolling out PyTorch 2.6 reliably in production.
Challenges
In a production ML stack, dependencies rarely move in isolation. Behind a simple version number change lies a web of assumptions about hardware, software, and rollout strategy. Concretely, we navigated the following challenges:
Outdated Ubuntu and CUDA Driver Versions
Per the official release compatibility matrix, PyTorch 2.6 requires CUDA 12.4+, which in turn requires the Nvidia driver family to be 550+. However, as of early 2025, our GPU hosts were still based on an end‑of‑life AWS Ubuntu 20 DLAMI, configured with CUDA 12.1 and driver family 530.
When we attempted launching the application service with PyTorch 2.6 on a GPU host, the Nvidia container runtime correctly rejected it with the failure below:
nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.4, please update your driver to a newer version, or use an earlier cuda container: unknown.
Breaking LibTorch APIs
LibTorch, the C++ distribution of PyTorch, evolves alongside its Python counterpart. PyTorch 2.6 introduced numerous breaking API changes, and each incompatibility implies noticeable engineering cost: building a compatibility layer to bridge versions while keeping behavior stable in production.
TorchScript Backwards Compatibility
For online inference, Pinterest relies on an in‑house, performance‑tuned C++ service built on top of Tensorflow Serving with LibTorch APIs. It loads TorchScript artifacts exported from MLEnv, coupling the Python training environment with the C++ serving environment. A central risk in the upgrade was whether the artifacts serialized under v2.1 would remain loadable, performant and numerically correct when interpreted by LibTorch v2.6, especially for complex production models.
Caffe2 Deprecation
From PyTorch 2.4 onward (), Caffe2 is no longer shipped as part of the distribution, and by 2.6 nearly all of its code has been removed. Meanwhile, several legacy visual search use cases still relied on Caffe2 APIs and operators, which entailed an escape hatch to keep them running until migrated off Caffe2.
Zero Downtime
Swapping the jet mid-flight is challenging. The on-the-fly upgrade was required to ensure absolutely zero user-visible downtime and no measurable performance regression on core product and ads surfaces. Any degradation in model latency, throughput, or hardware efficiency could translate into negative impact on engagement or revenue, so the upgrade path needed to be compatible with our existing deployment tooling, staging environments, and monitoring, and had to demonstrate production‑quality behavior before broad rollout.
Journey to PyTorch 2.6
With those constraints in mind, we treated the upgrade as a journey of rewiring a live system — moving one piece at a time and measuring at every stage. The following sections explain how we executed each step along the path.
Adopting U24 DLAMI
The first order of business was to make our GPU fleet compatible with PyTorch 2.6, and choosing the right CUDA version was key. To avoid subtle API–driver discrepancies, we wanted the same CUDA runtime version on the host and inside the application Docker image. We settled on CUDA 12.6 with Nvidia driver family 570, which sits at the overlap between PyTorch’s 2.6 compatibility matrix and the latest AWS Ubuntu 24 DLAMI spec.
Thanks to CUDA’s minor version compatibility, we could decouple the AMI upgrade from the PyTorch upgrade: SREs helped us build and roll out the new DLAMI across the fleet as an independent, backwards‑compatible step, while applications continued running PyTorch 2.1 without interruption.
Tracking Down TorchScript Deadlock & Disabling JIT Profiling Mode
During the upgrade, we learned that TorchScript issues often show up at initialization time. Our serving setup is atypical: the server loads multiple TorchScript artifacts in parallel within a single server process, and we capture CUDA graphs during model initialization so inference can run directly on CUDA graphs. This pattern is great for steady-state efficiency, but it also amplifies concurrency edge cases. Since TorchScript is in maintenance mode, our goal for this upgrade was pragmatic: prioritize stability and forward progress, even if that meant short-term mitigations, because our longer-term direction is to migrate toward torch.export-based serving.
One failure pattern looked like a deadlock: model initialization would stall during warm-up with no actionable error. After narrowing the blast radius, we found the stall correlated with TorchScript’s JIT profiling behavior under concurrent initialization. The mitigation was simple and effective: we disabled JIT profiling mode for TorchScript in serving to remove that source of nondeterminism during warm-up and CUDA graph capture. This was a deliberate “stability-first” tradeoff: we accepted giving up some profiling-driven optimizations in exchange for a predictable, non-blocking initialization path.
We also hit a second, related class of hangs after the NVFuser deprecation when switching to the newer fusion behavior. In our environment, the model could hang during warm-up, meaning the model server would never become ready. Since TorchScript already limits what it can fuse, and we didn’t want to sink time into optimizing a subsystem we plan to retire, we chose the most direct path: disable the fuser for TorchScript in serving. That unblocked the rollout at the cost of a modest performance regression (roughly 5–10% in serving efficiency). On Ads model servers, removing fusion optimizations increased SM activity by ~10–15% and led to ~1–5 ms P99 latency regressions at model level, though these were not observable at the higher-level Ads system overview due to concurrent work beyond model inference.
For “silent hangs” that could not be resolved cleanly by a runtime knob, our fastest path to resolution was an isolation workflow: build a minimal reproducible example, binary search the model code, identify a small offending module, and rewrite it into an equivalent implementation that avoids the TorchScript bug. The consistent theme across these issues was to optimize for containment: keep initialization reliable, keep rollback simple, and avoid over-investing in TorchScript-specific tuning when the strategic direction is to move off TorchScript entirely.
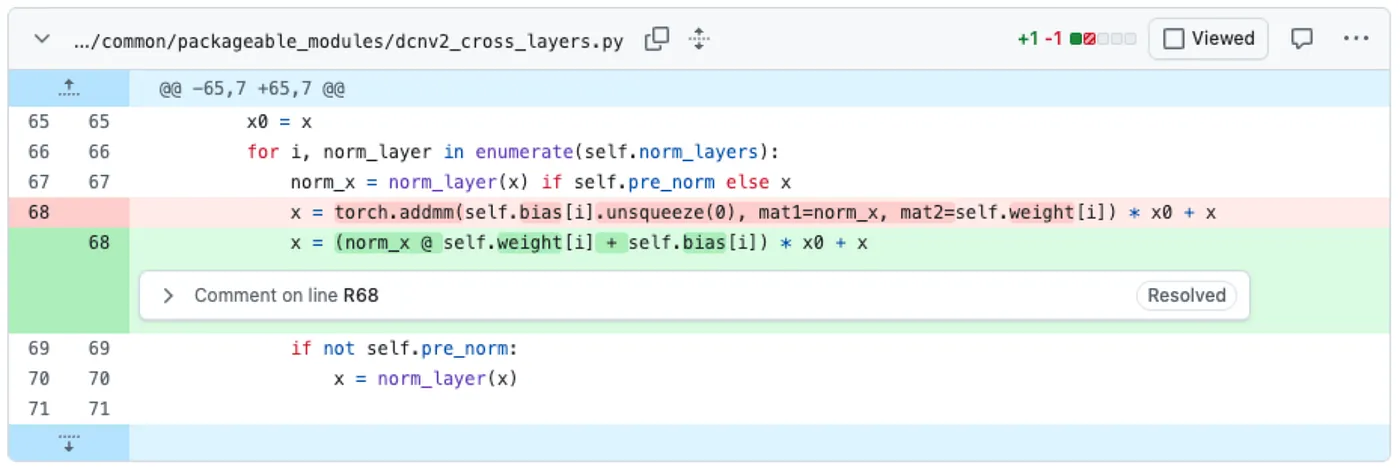
Figure 1: One example of TorchScript bug fix: inline “torch.addmm” into raw operators
Bridging Breaking APIs and Deprecated Caffe2
At Pinterest, all online C++ services are built by Bazel on top of a shared Docker image that pre‑installs LibTorch and core CUDA libraries (e.g. CUDA Runtime). Application binaries then link them dynamically via linker flags such as -ltorch and -lcudart.
Instead of landing a gigantic all-at-once upgrade that both upgraded shared libraries and rewrote the application code, we introduced a compile-time macro, PINS_LIBTORCH_VERSION, the value of which was set to the release date of a specific PyTorch version. For example, in the snippet below, 20250129means January 29, 2025 — the date PyTorch 2.6 was released.
cc_library(
name = "torch",
# As of August 2025, we're upgrading PyTorch from v2.1 to v2.6. To bridge
# breaking API changes, \`PINS_LIBTORCH_VERSION\` macro is defined to distinguish
# version-specific code at preprocessing stage.
#
# According to https://bazel.build/reference/be/c-cpp#cc_library.defines, all
# dependents of this target will inherit the macro definition in their compile
# command line.
defines = [
"PINS_LIBTORCH_VERSION=20250129",
],
linkopts = ["-ltorch"],
visibility = ["//visibility:public"],
)
We also pinned a specific Caffe2-compatible base Docker image for visual search services. It kept most of the stack on the modern runtime and gave Caffe2-dependent services a clear, and time-boxed window to migrate off their legacy dependencies.
Time-windowed Multi-stage Rollout
Once we gained confidence in correctness and performance from shadow traffic testing, we rolled out the upgrade phase by phase, one product surface at a time. We deliberately disabled automated releases to keep operations simple and fully controlled: we started with the lowest‑traffic surface, let it bake over a weekend, then expanded to larger surfaces. Each new surface rollout fit into a single day, and we aimed to complete the full production upgrade within about a week, avoiding a long, drawn‑out transition.
Production Aftercare
This section details two production issues encountered during and immediately following the PyTorch upgrade, along with the steps taken to resolve them and stabilize production.
Lost DCGM Metrics Recovery
During cluster replacements to upgrade the CUDA driver, we noticed DCGM metric loss specifically on AWS g6e family instances. Because (1) these metrics are critical for GPU health monitoring, and (2) the issue only appeared after the upgrade, we paused to find the root cause before continuing the rollout. The chart below shows DCGM profiling metrics dropping occasionally.
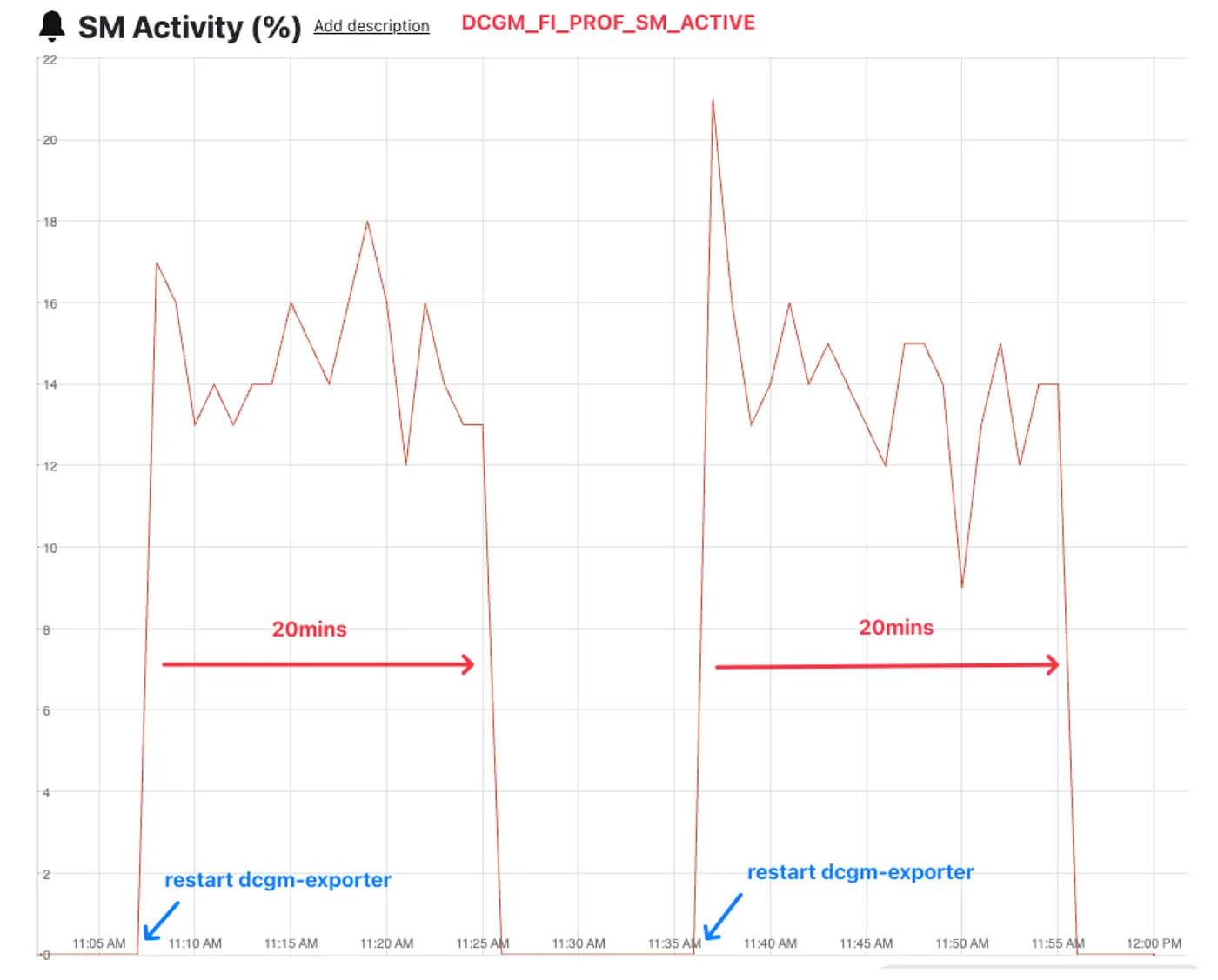
Figure 2: SM activity metric loss on a AWS g6e.4xlarge instance
At first glance, the drops looked cyclical. But the intervals were not consistent. After correlating the dips with host-level events, we found a clear trigger: Puppet runs (Pinterest fleet-wide configuration management) consistently preceded metric loss, and new deploys often restored the metrics.
We traced the problem to a resource conflict in our provisioning stack similar to this. Both the host and our DCGM exporter sidecar attempted to collect GPU metrics, but nv-hostengine only allows one active collector at a time. When Puppet restarted the host process, it competed with the pod’s process, creating a continuous contention cycle.
Once we pinpointed the cause, the fix was straightforward. DCGM provides the functionality to have the exporter attached to a running hostengine via DCGM_REMOTE_HOSTENGINE_INFO environment variable. With this set, we can “take the lock” and collect these metrics on the host, then tell the sidecar to ask the host process for the metrics as needed. After that change, DCGM metrics stayed stable and we could safely monitor the rest of the rollout.
Uncovering a Cgroup Driver Gotcha
After the upgrade, we started seeing intermittent model deploy failures on GPU instances across all product surfaces. The failures shared similar symptoms:
- CUDA operations failing with
cudaErrorNotPermittederror - Hosts occasionally reporting the GPU as “busy or unavailable” or even zero visible devices
Once a host entered this state, all subsequent CUDA operations failed until we restarted the application container or replaced the host.
The bug was hard to reproduce and initially sent us in the wrong direction. We tried a variety of mitigations: tuning different CUDA runtime/driver version combinations, adjusting CUDA memory pools, and even restarting the server on every model deploy. Unfortunately, none of those changes fixed the underlying problem.
The turning point came from a related observation on the problematic hosts: Nsight occasionally reported “Failed to initialize NVML: Unknown Error”. That led us to the Nvidia Container Toolkit troubleshooting guide, which documents a known issue about systemd cgroup driver.
The fix turned out to be in the container runtime configuration. Following Nvidia’s suggested workarounds, we rebuilt the DLAMI with Docker configured to use cgroupfs cgroup driver for GPU workloads. The sporadic model deploy failures ceased after the AMI patch was deployed across the fleet.
Wrap Up
Our journey of PyTorch upgrade turned out to be much more than a version bump: it was a cross-stack engineering effort. Along the way, we were reminded that many of the hardest problems live at the seams — between AMIs, DCGM exporters and container runtimes — rather than in PyTorch itself.
Overall, we hope this blog post offers a useful reference for your own efforts to keep PyTorch up-to-date at production scale, and perhaps a few ideas for how to structure the journey when “just upgrade the framework” turns into a much bigger story.
Acknowledgement
This effort was a true team work. In addition to the core team, we also want to extend special thanks to
- Jihui Yang for his significant contributions to CUDA builds
- Claire Liu, William Su, Sihan Wang, Randy Carlson and Hongda Shen for their support in Ads models
- Tao Mo for testing the upgrade across various Core product surfaces
We also acknowledge the ML Serving Platform team members for their diligence and dedication throughout the production rollout.