DeepSeek MoE -- An Innovative MoE Architecture
DeepSeek MoE -- An Innovative MoE Architecture
Those who have been following DeepSeek’s work since DeepSeek V3/R1 might easily think that a significant portion of DeepSeek’s efforts are focused on engineering optimizations for efficiency. However, reviewing DeepSeek’s papers over the past year reveals that they have actually been continuously innovating in model architecture and training methods, with V3 and R1 being scaled versions based on previous architectural innovations. The DeepSeek MoE paper introduces the main innovations in MoE architecture by DeepSeek, which currently appears promising and could potentially become the standard for future MoE architectures.
MoE vs Dense
First, let’s discuss the differences between MoE and traditional Dense architectures. Early LLMs were mostly based on Dense architectures, where every token generation requires activating all neurons for computation. This approach is quite different from how the human brain operates, as the brain doesn’t need to engage all brain cells for every problem. If it did, humans would be exhausted. Therefore, a natural idea is to no longer activate all neurons when generating tokens, but instead activate only those most relevant to the current task. This led to the MoE (Mixture of Experts) architecture, which divides neurons in each layer of the LLM into N Experts, with a Router selecting the K most relevant Experts to activate.
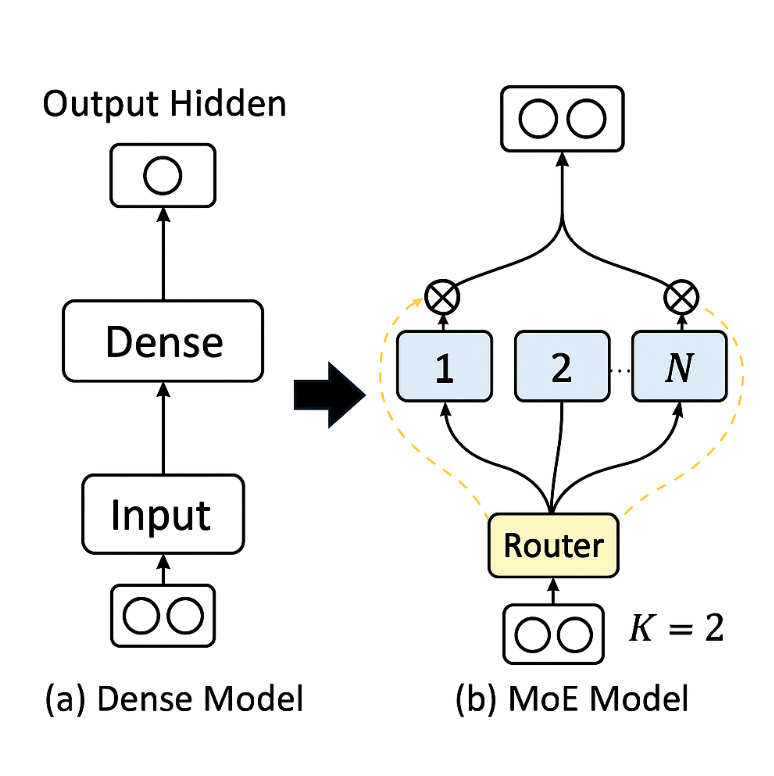
The benefit of this architecture is that during inference, not all neurons need to be activated, significantly reducing computational effort. In the most common 8-choose-2 mode before DeepSeek MoE, the computational load can be reduced to nearly one-third of a Dense model.
While the MoE architecture seems ideal, it essentially uses a few Experts to mimic the performance of a Dense model. The key lies in whether each Expert is specialized enough to truly mimic the Dense model’s performance. If we compare it to the human brain, when neurons are sufficiently specialized, specific tasks can be completed by activating only a few neurons.
The DeepSeek MoE paper introduces two innovations they made to push the specialization of each Expert to the extreme:
- More and smaller Experts
- Knowledge-sharing Experts
More and Smaller Experts
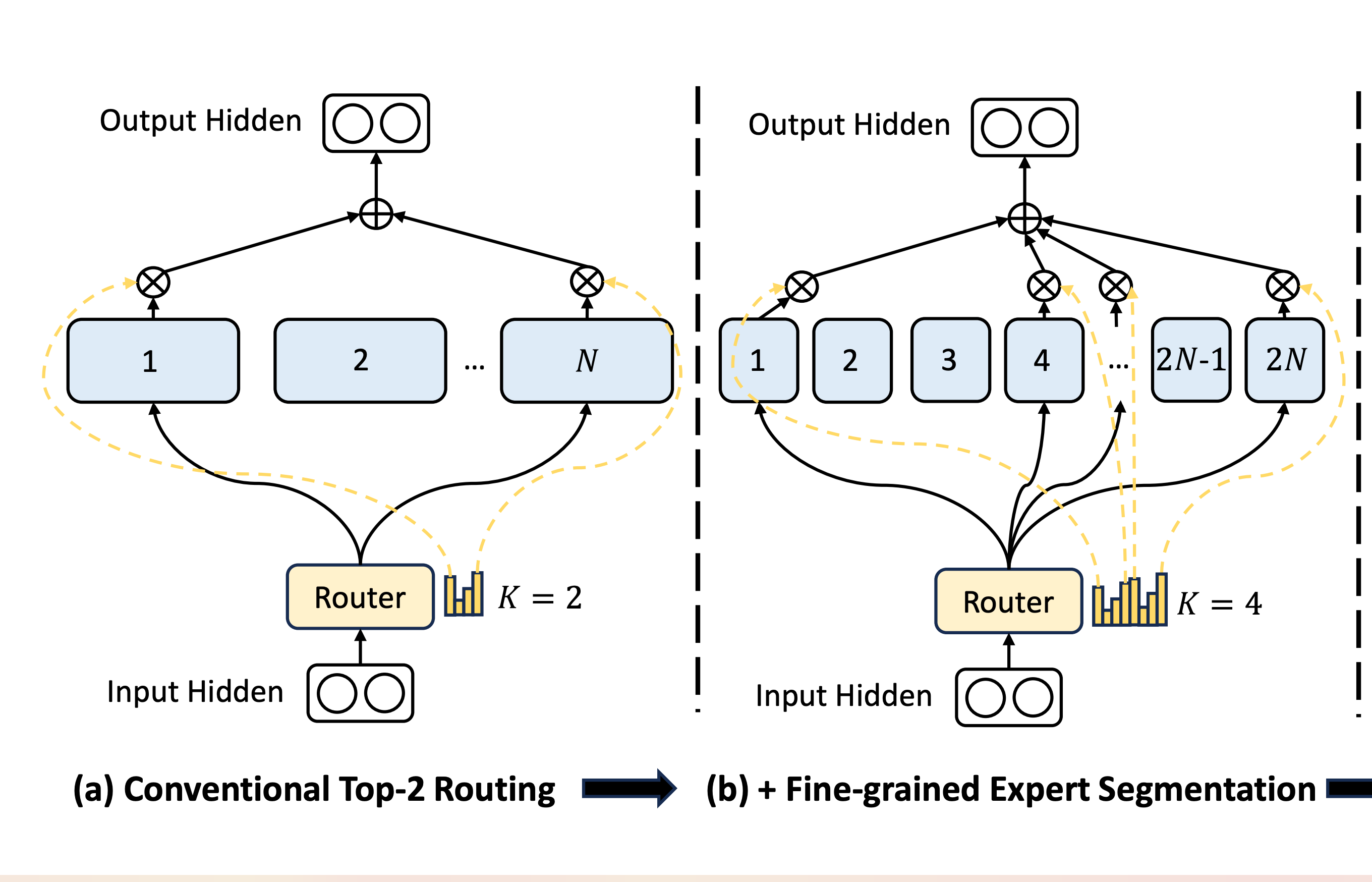
Using more and smaller Experts to increase the specialization of each Expert seems to be a straightforward approach. However, previous mainstream MoE architectures typically used 8 or 16 Experts. Given the myriad types of problems LLMs need to handle, this number of Experts clearly cannot achieve high specialization, resulting in each Expert having a lot of irrelevant knowledge for the current task.
However, as the number of Experts increases, training difficulty also rises, and the Router can easily end up selecting only a few Experts, leading to extreme load imbalance. Ultimately, the theoretical MoE architecture might end up activating the same small group of Experts each time, effectively turning into a small model. Therefore, most previous MoE architectures did not have a large number of Experts.
DeepSeek designed a set of loss functions that penalize repeatedly selecting the same Expert, thereby forcing the Router to more evenly distribute the selection of Experts. This approach solved the training problem, allowing DeepSeek to gradually scale the number of Experts. From 64 choose 6 in this paper, to 128 choose 12, to 160 choose 6 in V2, and finally to 256 choose 8 in V3.
It’s evident that DeepSeek has progressively expanded the number of Experts, and the proportion of Experts needed to be selected has also decreased from 9% to 2%, proving that with sufficiently specialized Experts, fewer activations are needed to complete corresponding tasks.
Knowledge-sharing Experts
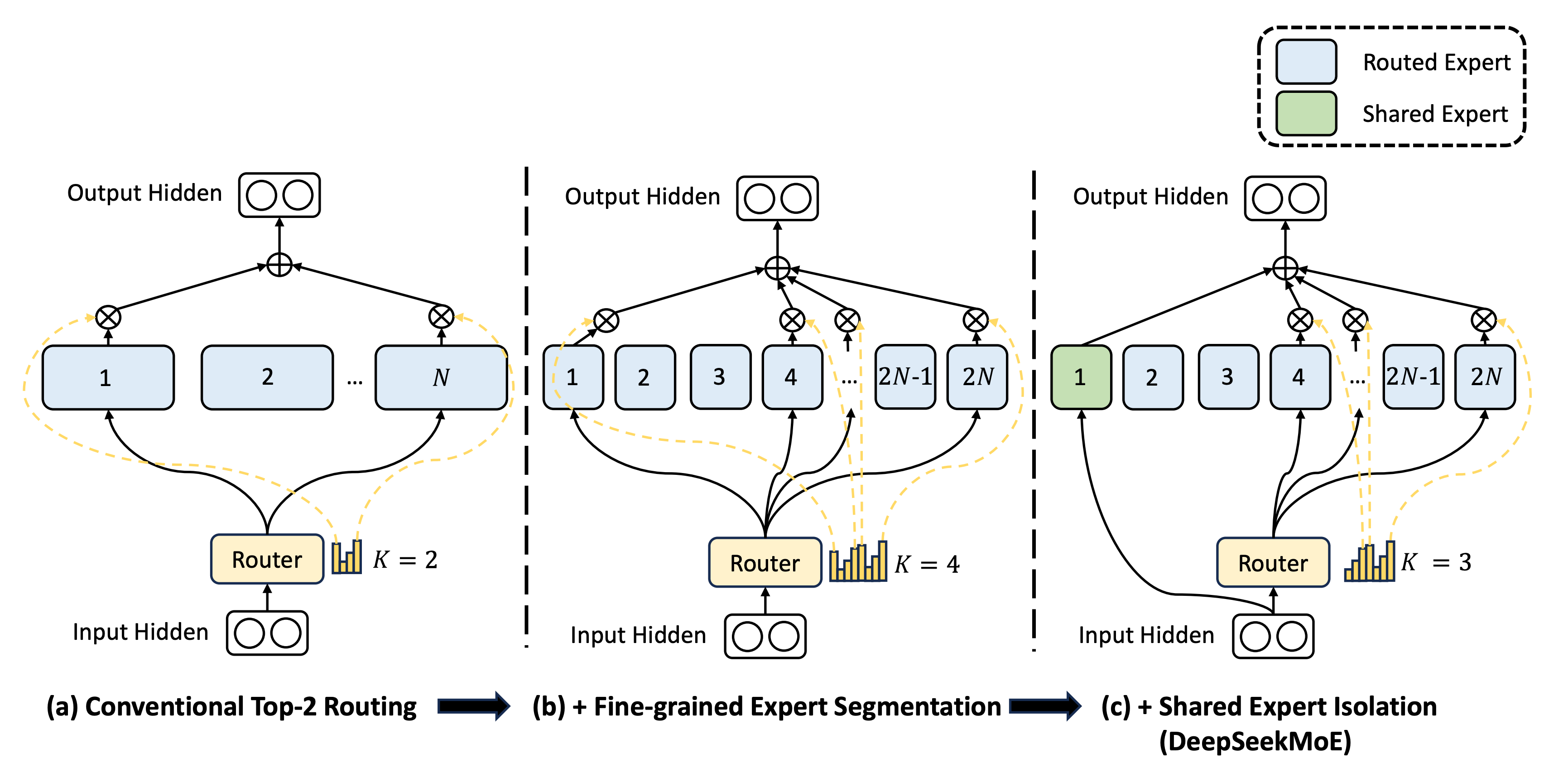
As Experts become smaller and their number increases, another issue arises: each Expert needs not only specific domain knowledge but also some general knowledge, such as general language understanding and logical analysis, which might be required by every Expert. If each Expert memorizes this knowledge, it leads to significant knowledge redundancy, which becomes more pronounced as the number of Experts increases. This can limit the specialization of each Expert and lead to resource waste during training and inference.
DeepSeek’s solution is to add a set of shared Experts, which are activated for every training sample. They aim for these shared Experts to learn general knowledge during training, so other Experts don’t need to learn this general knowledge and can focus on specialized knowledge. During inference, these shared Experts are also activated each time to provide general knowledge information.
This is another intuitive architectural innovation. However, since the Expert scale in previous MoE architectures was not large, the significance of this optimization was not apparent. Only when the scale increases does this problem become apparent. In this paper, DeepSeek scaled the number of shared Experts proportionally with the number of Experts. However, with more training and practice, they found that not so many shared Experts were needed, and by V3, only one shared Expert was used.
Reflections
After reading this paper, my biggest takeaway is that DeepSeek is not blindly stacking data with an already validated architecture but is genuinely innovating at the model level. This has resulted in many frameworks being unable to run DeepSeek’s models or having poor performance immediately after the V3/R1 boom, as DeepSeek’s model architecture is significantly different from others.
Moreover, unlike the innovations like MLA, GRPO, and NSA mentioned in other DeepSeek papers, which require complex mathematical skills, these two model innovations are relatively intuitive. However, at that time, only DeepSeek dared to try this approach, while others were still following Llama’s Dense model. Having the courage to make unconventional attempts requires a lot of bravery, and here I can only once again express my respect to the DeepSeek team.
