Improving Web Vulnerability Management through Automation
Vulnerability management is important, but can be incredibly time consuming. We have to scan our systems and then fix the vulnerabilities that we’ve discovered. In a large software engineering organization this becomes more challenging — service owners are responsible for fixing vulnerabilities in their systems along with all their other work, and security has to track this work, nudge engineers to actually fix things, and report to CISO/compliance/etc. Fortunately much of this work lends itself to automation, letting security engineers focus on understanding and fixing vulnerabilities! In this post we’ll focus specifically on web vulnerabilities, and some of the fun automation challenges this process poses.
The Old Ways Are Not Best
Until recently, due to our ever evolving environment and infrastructure considerations, Lyft’s web vulnerability process was a very manual intensive process, from scanning and tabulating results to deduplicating issues. In addition, it was necessary to manually prepare reports on a regular basis. All of this work represented a significant effort (3 months a year), and took time away from vulnerability analysis.
Our engineer performed the following manual steps every month, in addition to the aforementioned report:
- Run the scan on their computer using Burp (via UI) on a list of URLs, and then export the findings to an xml document. Scans could take several days, and often paused due to errors.
- Run a script on the xml document to turn it into a CSV file of issues that could be consumed by Jira.
- Import the CSV file into Jira as new issues. The issues were compared with existing issues, and closed as duplicates needed. Issues were triaged as well- severity might be upgraded or downgraded, for example. Finally, issues were assigned to service owners.
Better Living Through Automation
Ideally, the only step where human intervention is required is triage and assigning the issues to service owners. Running scans, converting the scan result to Jira issues and deduplicating issues should all be completely automated. The report should also be automated, given that all of the data on extant vulnerabilities are in Jira, and the report is always the same format. We also would like to run each of these steps independently. Scans should be able to run whenever without affecting jirafication or the quarterly report. One potential issue is that Jira ticket status can be changed by end users as fixed, which can render reports incorrect. This is mitigated by the scanner running frequently and reopening issues it finds still active. More problematic is marking issues as won’t fix, which causes the scanner to ignore them in the future. This is mitigated by regular manual inspection of won’t fix issues on an ongoing basis.
Architecture
From a functional perspective, we have three requirements. First, we need to scan one or more URLS, and generate an xml report. Second, we need to consume the xml report and generate Jira Issues for new vulnerabilities. Third, we need to generate the quarterly report and upload it to our document repository. Each of these can be thought of as a workflow where we consume data produced by the previous workflow:
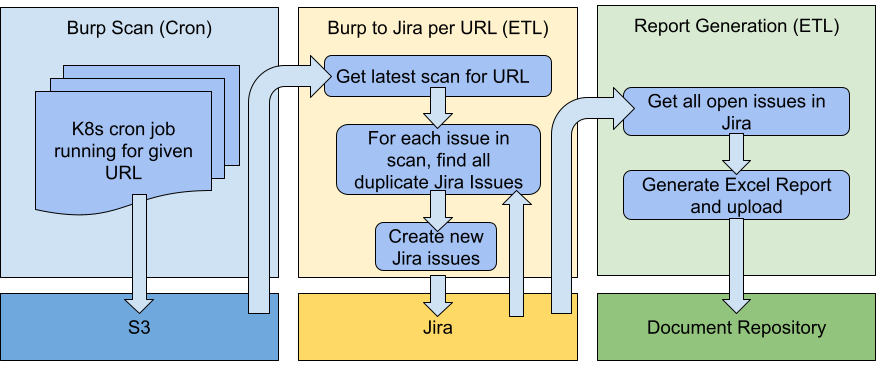
Scans should happen regularly, so that means we’ll use either an ETL or cron job. However, since they can take several days, we have to rule out ETLs as Lyft’s ETL infrastructure prefers much shorter run times for individual tasks. Consuming the scan output and making Jira API calls seems like a much better fit for an ETL, as does report generation. Both of these tasks should run relatively quickly, and we can take advantage of Lyft’s data infrastructure and tooling for faster development and prototyping. One problem we immediately run into is we need to pass the scan results to the etl. The cron cannot just save the data to the data warehouse like our ETLs can, so we store the findings in S3, and the ETL can then query S3 for the latest results.
Another consideration is deduplication. The legacy manual process relied on first creating issues in Jira, and then marking them as duplicates. This struck us as unnecessary; before creating new issues in Jira we can query existing issues for the vulnerability type and url, and if this exists, we have a duplicate and don’t need to create a new issue. This is great because it reduces the amount of issues in Jira; we can simply say for an existing issue we saw it again, and it’s still not fixed (or it has been marked as ‘won’t fix’).
Next, we decided to make scans more atomic, that is, scan a single URL and generate issues in Jira for a single URL. This makes it easy to add new URLs incrementally to the system- we may want to first schedule scans, but not turn on Jira issue creation (or only turn it on in staging).
Finally, given that all the web vulnerabilities are tracked in Jira, we can get all the information needed for our report with a single Jira query. As different severities have different resolution SLAs, and we know when the issue was originally created, it is trivial to calculate overdue issues!
Implementation
From an implementation perspective, we built most of the system on top of Flyte, Lyft’s data processing and machine learning orchestration platform. At Lyft, Flyte is the preferred platform (over Airflow) for various reasons from tooling to Kubernetes support. Most development was done with Jupyter notebooks hosted on Lyftlearn, Lyft’s ML Model Training platform, which allowed rapid prototyping and testing.
Burp is normally run in UI mode, but also supports headless mode, which can be enhanced by writing one’s own plugins. Moreover, Burp is configured via various configuration files. What we really want is to run a burp scan as a CLI command with a URL as an argument. This was accomplished by writing a plugin and some wrapper scripts.
The Excel-formatted quarterly report is generated using the excellent Xlsxwriter Python library. This gives precise control over building a spreadsheet cell-by-cell, as we have a rather strict format. Of note, one can write Pandas dataframes directly to an Excel file, but this gives less control over formatting.
A major criticism that can be leveled at this system is using Jira as our vulnerability database. Jira is fantastic for issue management, but as one starts doing things with Jira that it is not designed for- such as high query volume, or tracking multiple versions of vulnerabilities, or custom integrations with our infrastructure, it will not work as well as a general purpose datastore like Dynamo. Currently our task management all happens in Jira- assigning owners, commenting on tickets, etc., so some level of Jira integration is required. Ultimately given limited time and developer resources, this was the fastest way to get to a better experience. In the mid-term we will likely move to using an intermediate database to store vulnerability data, however.
Commentary
And just like that, our engineers are no longer occupied by trivial work, and can focus their energy on understanding vulnerabilities and driving their resolution. Per our number earlier, our engineers have an extra 3months a year now!
We cannot emphasize enough the need to build good tools- but tools should also be easy to understand and maintain. Even if you don’t have data infrastructure like Lyftlearn and Flyte to build on top of, the principles are the same- break the problem into manageable pieces and solve each one independently. This system was trivial to build; not including the slog to get Burp running as a CLI tool, everything was built in a week of engineer time.
This system is also easy to operate. Each of the three workflows is independent, and can be run ad-hoc. The scanner can go do whatever it wants; the jira stage doesn’t care. As long as it can find scan results in S3, it works. Likewise, the report generator works as long as it has access to Jira. Compliance wants a report right now? Fantastic, we can trigger the ETL!
Lyft Security is hiring! Join us as we develop secure solutions to complex problems.