Experiment without the wait: Speeding up the iteration cycle with Offline Replay Experimentation
Maxine Qian | Data Scientist, Experimentation and Metric Sciences

Ideas fuel innovation. Innovation drives our product toward our mission of bringing everyone the inspiration to create a life they love. The speed of innovation is determined by how quickly we can get a signal or feedback on the promise of an idea so we can learn whether to pursue or pivot. Online experimentation is often used to evaluate product ideas, but it is costly and time-consuming. Could we predict experiment outcomes without even running an experiment? Could it be done in hours instead of weeks? Could we rapidly pick only the best ideas to run an online experiment? This post will describe how Pinterest uses offline replay experimentation to predict experiment results in advance.
Online Experimentation Limitations
Data-supported decisions shape the evolution of our products at Pinterest. All product teams are empowered to test their product changes with online experimentation (A/B testing), a process to measure the impact on Pinterest users, aka Pinners. However, online experiments have several limitations:
- Slow data collection: It takes at least seven days and often more to allow sufficient power and capture any weekly patterns.
- Limited simultaneous arms: There can only be a limited number of variations running at the same time to allow a sufficient sample size for each.
- Risk-averse treatments: To minimize potential negative impact, there is an incentive to deploy safer, more conservative ideas instead of riskier but potentially highly impactful ideas.
- High engineering cost: The engineers need to write production-quality code since it will be deployed online to users.
Due to these limitations, it is critical to triage the ideas before running expensive online experiments.
Offline Replay Experimentation
How do we address these limitations of online experimentation? One can obtain initial directional analysis on concepts through offline evaluation of assessment metrics such as Mean Average Precision or AUC. Unfortunately, according to our empirical observation, these are often poor predictors of online experiment performance.
We created a framework called Offline Replay Experimentation, where the performance of new ideas can be simulated entirely offline based on historical data. In this framework, the new ideas in question can be anything that affects the order of the content served, such as changes to the ranking or blending functions.
While a simulation approach is less accurate than online experimentation, it complements online experimentation by eliminating waiting time for data collection, allowing for a large number of simultaneous arms, avoiding negative user impact, and saving engineering costs.
Offline replay experiments can be used to narrow the idea funnel from a large set of possible candidates to the few worth pursuing via online experiments. This framework has allowed product teams to evaluate and iterate on ideas within hours instead of weeks, dramatically speeding up the iteration cycle. It comprises two parts:
- Counterfactual Serving Simulation: It simulates what content we would have served users if we had deployed the change in the past.
- Reward Estimation: It estimates the reward (the value of different types of engagement such as click) of the counterfactual serving results for each experiment variant that we want to compare. It then compares the estimation of two variants (e.g., control vs. treatment) to calculate the lift.
There have been several blogs and papers about how to generate counterfactual serving results (e.g., Distributed Time Travel for Feature Generation by Netflix and Counterfactual Estimation and Optimization of Click Metrics for Search Engines: A Case Study). Here, we will focus on our reward estimation methodology.

Figure 1: Two components of offline replay experiment framework
Reward Estimation Methodology
We will use a toy dataset in Figure 2 to illustrate how reward estimation works. Table 1 represents the counterfactual serving logging, the items we would have served users given a new ranking or blending function. Table 2 exemplifies the production logging, the items that we have served to users and its sampling probability, as well as the user actions. Each record represents a Pin that was ranked on the page with the following information:
- The request is the key to group all of the insertions of the items (i.e., Pins) on the result page for the request.
- The position is the display position of an item for a request.
- The reward is the target variable, which usually corresponds to user actions such as click and likes.
- The sampling probability is the probability that an item showed at the position for the request.
Figure 2: Toy dataset as an illustrative example
To estimate the rewards, we find the matched records between the two datasets that share the same request, position, and item, and sum the reward of the matched records as the total reward. To eliminate the selection bias, we apply a weight, which is the inverse of the sampling probability, to each reward. Intuitively, a record with a higher sampling probability is overrepresented, so we want to apply a smaller weight to its reward value.
As illustrated in Figure 3, the only two matching records that we can find for both counterfactual serving and production loggings are {request=r1, position=1, item=a} and {request=r2, position=3, item=f}, therefore the estimated reward would be 1/0.4 + 0/0.5 = 2.5.
Figure 3: Illustrative example of how Top K Match estimator works
We call this reward estimator Top K Match. K means the depth of the slots that are included in the estimation. In our toy example, K equals 3. There are multiple variants of the reward estimator with a trade-off in bias and variance:
- Top K Unbiased Match: Top K assumes the reward of an item is independent of the items around it. We can obtain an unbiased top-K replay estimator by matching the entire ranked top-K list for each request. It only counts the reward if the ranked top-K list according to the new model is the same as the top-K list for the request in the production dataset. In Figure 2, there are no matched records for both loggings, therefore the estimated reward would be 0.
- Top K Unsorted Match: The match rate can be low for Top K Match and Top K Unbiased Match, which leads to large variance. We can address this by relaxing the match criteria to only require the request_id and item_id to match. It counts the reward if any item_id in the top-K list according to the new model is the same as the item_id in any position for the request in the production dataset. As illustrated in Figure 4 in the toy example, the matching records that we can find for both loggings are {request=r1, item=a}, {request=r2, item=d} and {request=r2,item=f}, therefore the estimated reward would be 1/0.4 + 1/0.4 + 0/0.5= 5.
Figure 4: Illustrative example of how Top K Unsorted Match estimator works
It’s worth mentioning that sampling probability is often not available during implementation, and it requires a non-trivial change to the system to instrument it. To simplify the problem, we set up a random bucket of a small set of total traffic, in which we randomize the order of the top N results and then p equals 1/N.
Real Examples
We applied the offline replay experiment on Home feed ranking and blending models and observed compelling results.
We first calculated the statistical power of the three reward estimators and found Top K Match and Top K Unsorted Match can have sufficient power to detect our desired effect size, while Top K Unbiased Match is greatly underpowered. We then ran both offline replay experiments using these two sufficiently-powered estimators and online experiments on 26 experiment comparison variant pairs.
Using the metric Click as an example, we found a strong correlation between online and offline lift, as shown in Figure 5. In general, offline lift is correlated with a smaller online lift, but the rank orders of the variants based on them are similar.
A similarly strong correlation was also found comparing online and offline decision-making results (i.e., significantly positive, insignificant, significantly negative). These results show that Top K Unsorted Match (K=8) performs the best (i.e. has the highest correlation between online results and offline replay). If we run an offline replay experiment, it would allow us to identify over 90% of the candidates that showed a statistically significant and positive lift in an online experiment while filtering out over 75% of candidates that showed an insignificant or negative lift in an online experiment.
Figure 5: Online experiment Lift vs. Offline Experiment Lift
We also compared offline replay results with Mean Average Precision (MAP), which was previously used to select candidates for online experiments in Figure 6. Offline replay experiment significantly outperforms MAP. In fact, using MAP, we are only able to identify 25% of ideas that would ultimately show a statistically significant positive lift in an online experiment.
Figure 6: Online experiment lift vs. Predicted lift based on MAP (left) and Online experiment lift vs. Predicted lift based on Offline replay experiment (right)
To understand how an offline replay experiment can help narrow the candidate set of variants that we want to test, we took a look into how the offline replay experiment would rank the variants compared with online. In the validation data, there are five experiments with more than one treatment variant. Figure 7 shows the data of one example experiment. We separately calculated the ordering of variants based on offline replay experiment lifts and online experiment lifts. Using the ordering from online experiments as the ground truth, we found offline replay experiments can identify the variant with the highest lift for all the experiments in our sample. It demonstrates that we could gain valuable early insights from offline replay and only pick the top ideas to validate in online experiments.
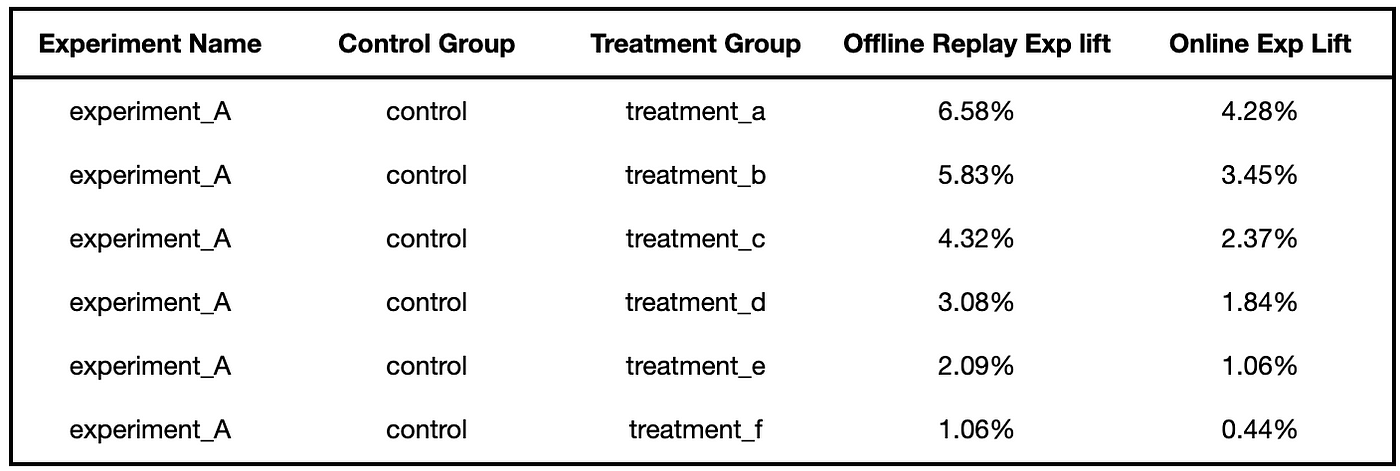
Figure 7: Data of one example experiment
Offline replay experimentation is a valuable addition to our idea evaluation toolbox and complements online experimentation in many ways. Combining offline and online experimentation, we can strike a balance between accuracy and velocity, unlocking product innovation far more quickly and efficiently.
Acknowledgments
Shout out to Bee-Chung Chen, Chen Yang, Fan Jiang, and Kent Jiang, Sam Liu for their contributions. Special thanks to Aidan Crook, Olafur Gudmundsson, Yaron Greif, and Zheng Liu for their feedback and support.
To learn more about engineering at Pinterest, check out the rest of our Engineering Blog, and visit our Pinterest Labs site. To view and apply to open opportunities, visit our Careers page.