Adding Document Understanding to Claude Code
The rise of coding agents like Claude Code, Cursor, Windsurf, Cognition, Lovable, etc. marks a shift in how software is built. Instead of manually wiring APIs together, you can describe what you want through natural language, and the agent can handle the technical task of writing, executing, and iterating on the code. This opens up the possibility for “low-code IT” and allowing business users to quickly build internal and external-facing applications.
But there’s a problem: by default, coding agents don’t natively understand documents. This limits their utility for building business applications. Enterprise applications live and breathe documents: contracts, financial reports, legal briefs, technical specifications, meeting notes. These documents are typically locked up within file formats like .pdf, .pptx, .docx, .xlsx and require specialized tooling to read and search over that information, tooling that coding agents don’t have.
This may sound surprising at first glance. But coding agents have real limitations for understanding files:
- Cursor doesn’t support PDF upload at all (and many other files).
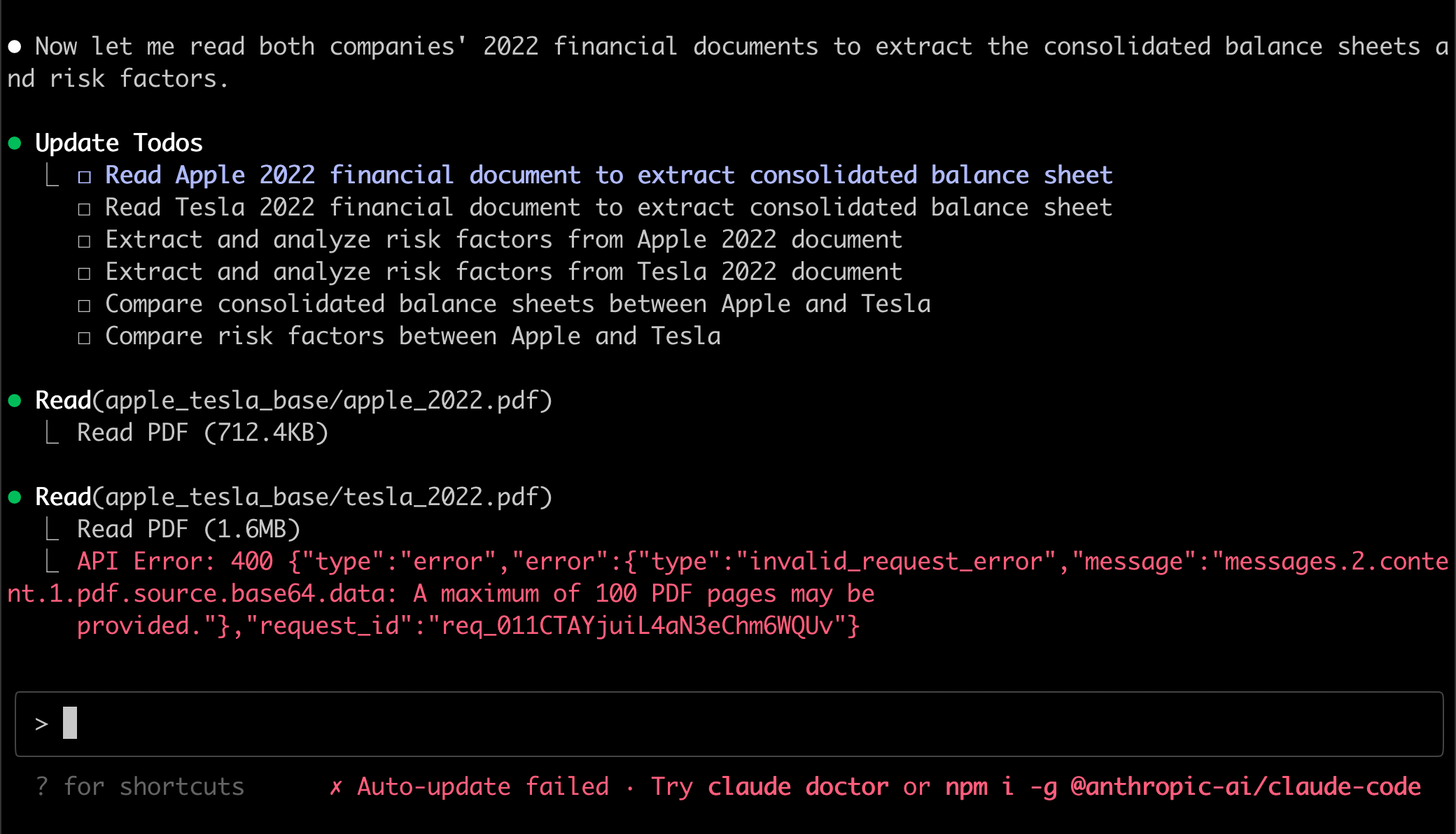
- Claude Code has a
Readcapability that has basic PDF understanding capabilities, but a max file size of 32 MB and 100 pages per request.
By equipping coding agents with the right tools around document understanding:
- They can pull in more context. This means building apps that better adapt to business requirements.
- They can use the tools within the generated code. This means building apps that are more agentic, generalized, and higher accuracy.
In this blog we use Claude Code as a proxy for all coding agents. At its core, this post helps to explore what it means to equip Claude Code with the ability to understand and work with an entire bucket of PDFs.
Why Do We Care?
A recent MIT report mentioned that the 5% of AI agents that do make it to production are those that can deeply embed themselves in custom business workflows. A lot of those workflows are document-based - 90% of enterprise data is locked up within documents. Without document understanding tooling, coding agents are missing core context and are also unable to build useful automations.
- Missing Core Context: When you ask Claude Code to build a financial reporting dashboard, it should understand what your quarterly reports actually look like, how your data is structured, and what metrics matter to your business. In a lot of enterprise settings, these documents are probably locked up as PRDs and product specs within a file repository like Google Drive or Sharepoint. Without this context, Claude Code will generate generic templates based on assumptions.
- Unable to Build Useful Automations: Ask Claude Code to build contract review software and it might generate code that looks for keywords like "termination" or "liability," but completely miss the nuanced legal language that determines enforceability. This means that the automations Claude Code generates is brittle and not generalizable to various inputs, which also means they’re not very useful.
Building most business applications requires Claude Code to have both (1) and (2). Imagine you’re a private equity analyst looking to automate due diligence analysis over a data room of financial documents. Claude Code would need an initial layer of document understanding to process an example set of financial docs (are they public filings, reports), along with previous due diligence reports, in order to understand the business requirements. It would also need to leverage these modules during the generated workflow.
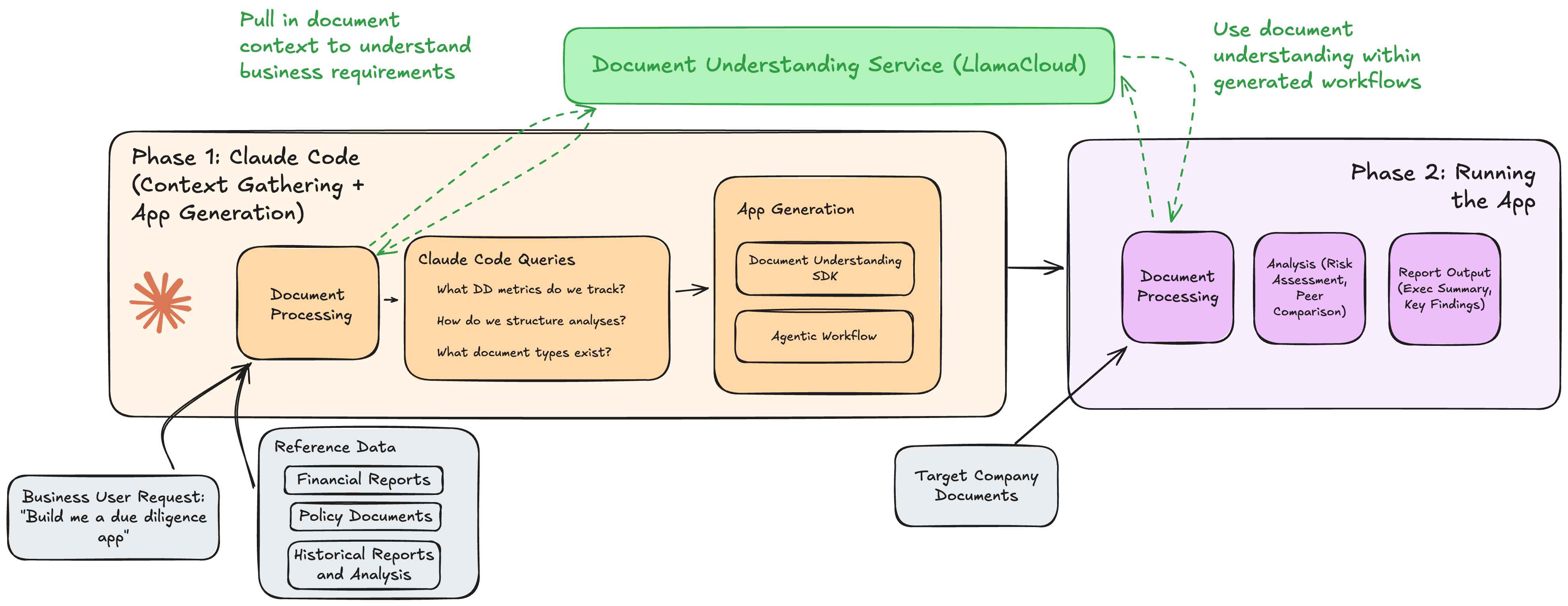
Three Ways to Give Claude Code Document Understanding
Over the past few months, we’ve been exploring ways to bridge this gap. Here are three complementary patterns for adding document intelligence to Claude Code. Each approach has their own tradeoffs, and we describe them in detail so you can pick and choose which one(s) to use for your own purposes.
1. Access your Docs through MCP
Claude Code natively supports the Model Context Protocol (MCP). There is a long list of official MCP integrations that allow connecting to any SaaS service, from Salesforce to Confluence to Figma. If your data source is primarily a collection of files, you will need to do pre-processing on the document collection before exposing it as an MCP endpoint to Claude Code.
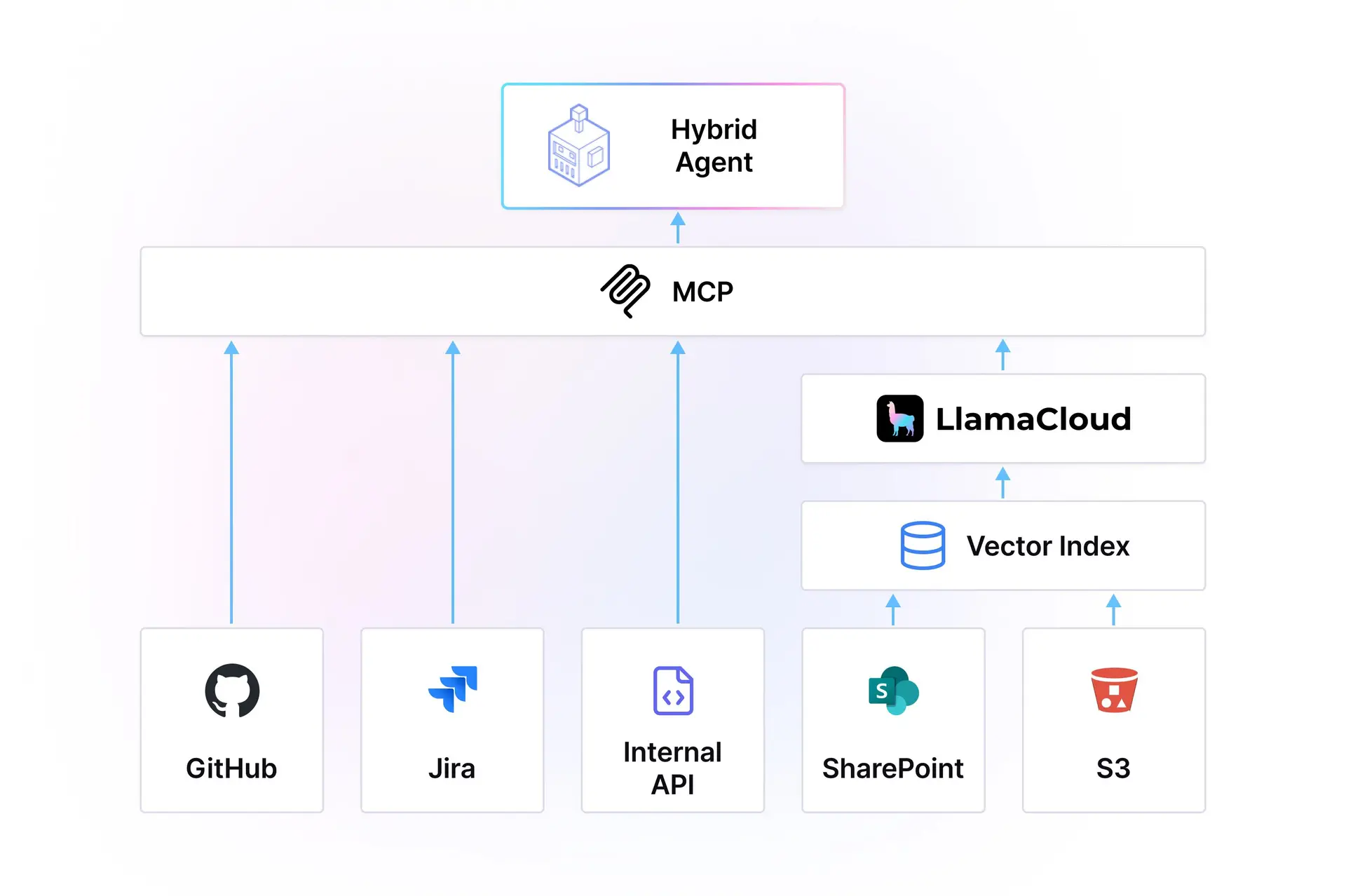
How: You need a service to parse, chunk, and embed your documents (PRDs, financial reports, claims) into a storage system (vector db, structured database, graph database), and expose it as a set of MCP tools. During code generation, Claude Code can choose to query the MCP server to give it rich context about your business processes, policies, and data structures.
Why: This gives your coding agent a quick and dirty way to access a large pile of context. When you ask it to "create an expense approval workflow," it already knows your company's spending limits, approval hierarchies, and policy exceptions because it can query your indexed policy documents.
Tradeoffs: There are a few downsides with this approach.
- The quality of your context depends heavily on your indexing/retrieval/MCP implementation! There are no official MCP servers for popular file repositories like Sharepoint, and many of the community ones do not have robust endpoints for search.
- The coding agent can directly access context, but it cannot access the indexing implementation itself to build a robust document understanding workflow.
- If your coding agent is accessing dozens/hundreds of MCP servers, you run into the problem of federated search. This is where a centralized, high-accuracy index still matters. As we argued in “Does MCP Kill Vector Search?”, federated MCP is powerful but insufficient without a preprocessing and indexing layer over unstructured data. (If you don’t believe us, Glean argued the same thing here).
Tools like LlamaCloud made accessible through the open-source LlamaCloud MCP server or https://mcp.llamaindex.ai/ help to alleviate (3) and partially (1): it provides centralized indexing to reduce the downsides of federated retrieval. It also has high-quality standardized modules for parsing, indexing, and retrieval, though it doesn’t have the richness of operations that you may get through a CLI (see below).
2. Operate over your Docs through the CLI
Coding agents are extremely good at using command-line tools, which provide a diverse range of operations that you cannot get through “pure” semantic search (e.g. grep , cat , find ). Adding an agentic reasoning/tool calling layer to search allows you to get powerful results even if the search tools themselves are simplistic (see Windsurf’s implementation of code search).
The main existing limitation is that coding agents suck at reasoning over files: Standard CLI operations like grep , cat , and find are designed for structured text, not complex documents. They can't parse a PDF's table structure, understand the semantic meaning of a passage, or extract specific fields from scanned invoices.
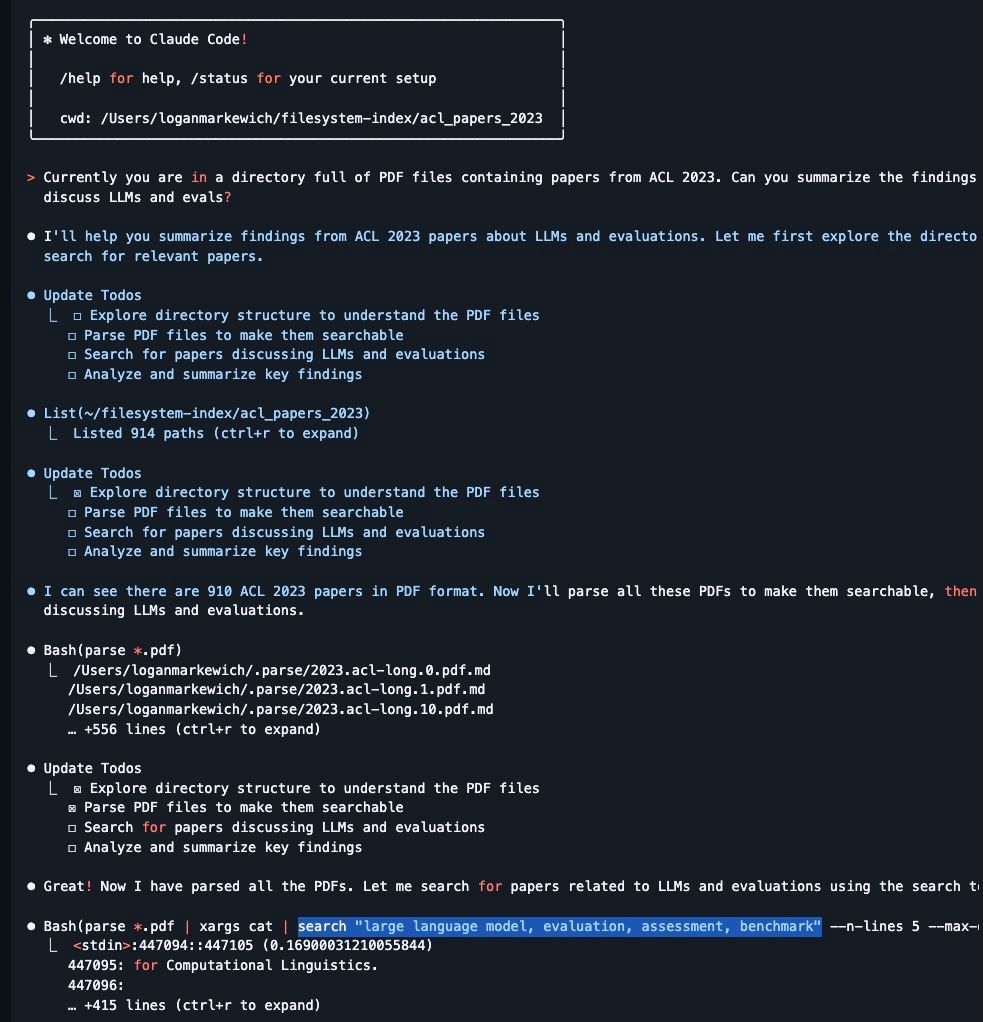
The solution: Give the coding agent context on an expanded set of CLI commands that can do document parsing, extraction, and search. This lets them read documents, dump it to a cache, get all the benefits of grep and cat over the indexed data, but still give the coding agent access to semantic search.
Why: Imagine tasking a coding agent with analyzing 100+ legal briefings to identify precedent cases. With enhanced CLI tools, it can efficiently search across the entire corpus, extract relevant citations, and cross-reference findings—all while staying within the familiar command-line interface that coding agents excel at using.
Tradeoffs: You need to ensure 1) all the files are available locally / in an environment where you can access a CLI, and 2) we found this approach works well over ~1k docs, but it is not entirely clear whether it works well over 1M+ documents, where you would need to fall back to semantic search.
Tools like SemTools add parse and search commands that give coding agents true document understanding capabilities. This approach is particularly powerful because it maintains the flexibility and composability that makes CLI tools so effective while adding the document intelligence that business applications require.
3. Teach Claude Code How to Build Agentic Document Workflows
The first two sections above help Claude Code get more enterprise context through your documents, but don’t necessarily help it structurally build a better business application.
Rules-based approaches won’t generalize: whether the generated app is interpreting contracts, invoices, or financial filings, it will not be very useful if the generated code is primarily rules-based and uses poor-quality document modules. All of these input documents are high-dimensional and can vary widely in complexity; rules-based approaches will easily break on the vast majority of inputs. The coding agent generates hard-coded rules to process invoices with a specific format. When invoice layouts change or new vendors use different templates, the application breaks. The agent can't interpret results or adapt to new document types.
The solution: A better business application fundamentally needs to be AI-native. This final step “teaches Claude Code how to fish” - instead of just providing context in a one-off manner, it gives Claude Code the underlying document parsing, extraction, and workflow tooling so that it can directly use these modules in the generated application.

How: Append to CLAUDE.md in a standardized way to use document parsing and workflow modules:
- The document parsing APIs need to handle complex document layouts, provide confidence scores and citations for extracted data, and maintain consistency across different document types.
- The workflow APIs need to enable coding agents to build multi-step workflows that combine document processing with human oversight, error handling, and quality validation
- If you have a large amount of documentation to provide to your agent (for example, over 20K tokens), then you will likely get better results by developing a documentation retrieval tool with MCP. Overloading the CLAUDE.md file will have negative impacts past a certain point.
Why: This will give it a standardized language to build applications that interpret documents and reason over it in a general manner. When new invoice formats appear, the underlying document intelligence adapts automatically. The application can understand what it's processing and provide meaningful feedback about confidence levels and extracted data quality.
Tools like vibe-llama give your coding agents standardized context on how to build these agentic document workflows, powered by LlamaCloud for document understanding and LlamaIndex Workflows for agent orchestration.
Get Started!
The best thing to do is all three!
We're moving from a world where applications are built by engineers who understand both business requirements and technical implementation, to one where domain experts can directly express their needs to coding agents that handle the technical complexity.
But this transition only works if coding agents can bridge the gap between natural language business requirements and the messy reality of enterprise data. Documents are where this gap is most apparent—and most critical to solve.
We’re building that bridge at LlamaIndex. All this tooling is available today - whether you’re a more technical or less technical AI builder, our resources help provide a robust, reusable foundation for document-centric workflows.
Connector Resources:
Core Services: