Evolution of Multi-Objective Optimization at Pinterest Home feed
Homefeed: Jiacong He, Dafang He, Jie Cheng (former), Andreanne Lemay, Mostafa Keikha, Rahul Goutam, Dhruvil Deven Badani, Dylan Wang
Content Quality: Jianing Sun, Qinglong Zeng
Introduction
In feed recommendation, we recommend a list of items for the user to consume. It’s typically handled separately from the ranking model where we give probability predictions of user-item pairs.
Pinterest’s feed recommendation follows a cascaded system design with retrieval [1][2], pre-ranking [3], ranking [4][5], and re-ranking. While most of these prior works focus on optimizing immediate actions for each candidate Pin, this work will primarily focus on how we build the final layer of the recommendation funnel for multi-objective optimization. This is a critical part of our recommendation system as it helps us balance short-term and long-term engagement, drive new use case adoption, and satisfy various business requirements. Throughout the years, we have made substantial improvements on this layer through both algorithmic and infrastructure upgrades. In this tech blog post, we will share our experiences, learnings and improvements we’ve made over the years on this critical layer.
Overall System Design
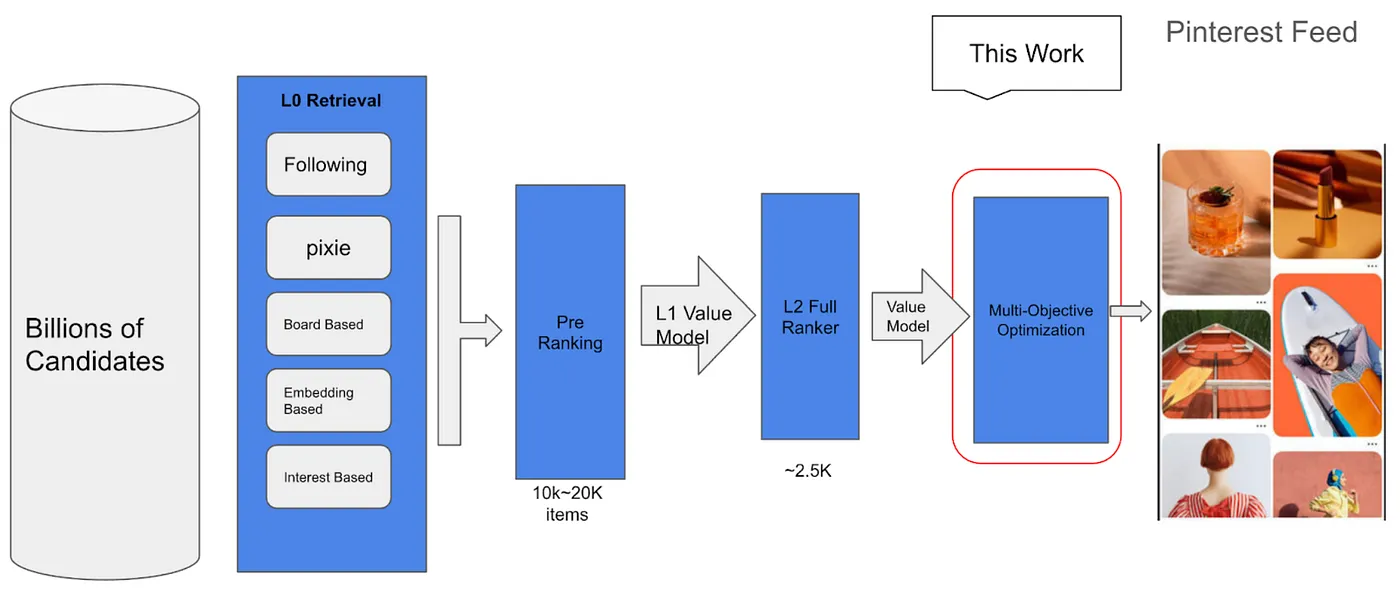
Figure 1. Cascaded Design of Pinterest Funnel.
Figure 1 illustrates the cascaded funnel design of our feed recommendation system from retrieval to ranking to the multi-objective optimization component. While earlier stages mostly optimize for certain positive actions (e.g., saves) given an impression, the multi-objective optimization layer tackles a different problem: determining the best composition of a feed served to the user. This is critical as users tend to have lower intent when visiting Home Feed and their browsing behavior will be significantly impacted by what they see. For example, visually repetitive content is less engaging and is likely to reduce the user’s session length and the likelihood that a user will revisit Pinterest.
Multi-Objective Optimization Design
In this section, we describe the detailed design of our multi-objective optimization layer.
Diversification
Feed diversification is an important factor for continued user satisfaction. We empirically found that when removing the feed-level diversity component, users’ immediate actions (e.g., saves) increase on day 1 but quickly turn negative by the second week. This also comes with a reduced session time and other negative downstream effects which significantly reduces the user’s long-term satisfaction. It is important to note that when users engage with less diverse content, engagement signals will also be affected, reinforcing the system to generate less diverse content.
To achieve better short-term and long-term engagement, we applied a diversity-based re-ranking algorithm in our feed as the main part of the multi-objective optimization layer. It is also one of the most important parts of the multi-objective re-ranking system.
V1: Determinantal Point Process (DPP)
DPP is widely used in the industry for feed diversification [6][7]. In our first generation of feed diversification, we leveraged DPP as the main component.
Mathematically, DPP is parametrized by a kernel matrix Lₙₓₙ where the diagonal entry Lᵢᵢ measures the relevance/quality of the i-th item, and the off-diagonal entries Lᵢⱼ = Lⱼᵢ measure the similarity between item i and j. Practically, we use learned embedding such as GraphSAGE [8] and categorical taxonomy as a lever to determine item and item similarity. Thus, DPP’s kernel matrix can be generalized to L = f₀(Λ) g𝜓(S) f₀(Λᵀ) where Λ is the diagonal matrix whose diagonal entries are relevance scores of items, f₀(·) is a monotonic increasing element-wise transformation.
Our first version of the feed diversification algorithm was implemented in 2021 based on the DPP algorithm.
Since its launch, it has become one of the most impactful components in our system. As the system becomes increasingly responsive through more real-time signal adoption such as in TransACT[5], we have found out that user satisfaction improves when they have more diverse feed recommendations through DPP. We conducted an ablation study by removing the DPP component and found that the user’s time spent impression reduced by over 2% after the first week.
V2: Sliding Spectrum Decomposition
Sliding Spectrum Decomposition (SSD) [9] is a position‑adaptive diversification method used in the recommendation system that views a candidate feed as a mixture of latent “spectra” (topics/intents/styles). As we render the feed top‑down, SSD repeatedly decomposes the local similarity structure within a sliding window and rebalances exposure: under‑represented spectra are promoted while over‑represented spectra are softly penalized. This yields locally smooth yet globally balanced diversity, complementing slate‑global methods like DPP.
Mathematically, let X ∈ Rⁿˣᵈ be item embeddings and S ∈ Rⁿˣⁿ a symmetric similarity matrix built from learned representations (e.g., GraphSAGE). At position t with window size w, restrict S to the window S^(ᵗ) and compute a top-K spectral decomposition S^(ᵗ) ≈ U^(ᵗ) Λ^(ᵗ) U^(ᵗ)ᵀ. Let r ∈ Rⁿ be base relevance scores. SSD tracks cumulative exposure Eₖ(𝑡) per local spectrum k and defines an adjusted utility: Uᵢ(𝑡) = f(rᵢ) − β ∑ₖ₌₁ᴷ wₖ(𝑡)·(uₖ^(ᵗ)[i])² where f(·) is a monotone transform of relevance, β controls diversity strength, and wₖ(𝑡) increases with exposure relative to current spectral mass (e.g., wₖ(𝑡) ∝ Eₖ(𝑡) / (ε + λₖ^(ᵗ)). The next item is i⁎ = argmaxᵢ(Uᵢ(𝑡)); exposures are updated and the window slides.
Compared to DPP, sliding spectrum decomposition has lower computational complexity given that it avoids Cholesky-style similarity matrix decompositions. The original paper introducing SSD algorithm (link) gave a comprehensive comparison between different variations of DPP algorithms vs SSD algorithms:

Table 1: Comparisons of greedy inference complexity for SSD and DPP with dense item embeddings. In general, we have 𝑁 > 𝑇 > 𝑤 and 𝑑 > 𝑤. [9]
Moreover, the implementation logic of sliding spectrum decomposition is built from standard linear-algebra blocks (windowed similarity, top-K eigen/SVD, weighted penalties, etc.) and can be implemented cleanly in PyTorch with straightforward operations. It avoids positive semi-definite enforcement, log-determinants, and fragile numerical issues common in DPP (e.g., jittered kernels, Cholesky failures), enabling a straightforward “PyTorch-style” model approach with vectorized scoring and lower serving latency.
In early 2025, we launched the SSD algorithm, leveraging PyTorch for its diversification logic. This was executed on our company-wide model serving clusters. The SSD algorithm’s simplicity allowed us to incorporate more features for evaluating pairwise Pin similarities, ultimately leading to improved balance between engagement and diversification.
Unified Soft-Spacing Framework
With SSD it further enabled us to incorporate quality goals when evaluating pairwise pin similarities in the backward window. For content less aligned with our quality standards, we added a quality penalty score on top of the SSD objective for which we call it “soft spacing”, as it allowed us to avoid having these content clustered together while also balancing with engagement and diversification.
We define the soft spacing penalty: qᵢ(t) = 𝟙[cᵢ ∈ R] ∑{d=1}^w (1/d) 𝟙[c{t−d} ∈ R]. It’s applied when item i belongs to the sensitive set R and nearby previously placed items in the backward window also belong to R, with each prior item inversely weighted by distance. We then subtracted the soft spacing penalty term to the adjusted utility Uᵢ(t) with a coefficient λ to balance with other objectives.
This is an important next step for improving content quality on Pinterest and protecting users from content that warrants additional caution, where in the past we usually rely on strong enforcement like filtering which sometimes leads to less satisfying user experience if there is no backfill. In mid 2025 we launched the soft spacing penalty on content with elevated quality risk, to restrict its distribution and ensure the utmost quality standards at Pinterest. In late 2025 we further abstracted the logic via building an easy to use, config-based framework to make it more extendable to meet and adapt to quality needs.
System Infrastructure Evolution
At the launch of DPP, the main multi-objective optimization (blending) layer is composed of a sequence of “nodes.” Several Lightweight Reranking nodes first perform low-latency reordering to optimize for short-term engagement and coarse diversity. Candidate pins are then passed to the DPP node, where the more time-intensive DPP algorithm is applied. Before the system outputs the final recommendation list, additional heuristic reordering logic is still needed, such as the spacing strategies mentioned earlier. This chain of nodes is embedded within the Home Feed recommendation backend system. While this setup is relatively robust because it can directly leverage existing backend dependencies, it makes iteration on blending-layer logic challenging due to limited flexibility for local testing and the difficulty of experimenting with new features.
With the introduction of SSD, a significant portion of the blending layer’s logic, including much of the diversification logic, has been migrated to PyTorch and is now hosted within the company’s model serving cluster. Our ongoing efforts aim to transfer more heuristic logic from the blending layer to the model server, thereby simplifying chain execution within the blending layer.
Evolution of blending layer is exemplified by the graph below:
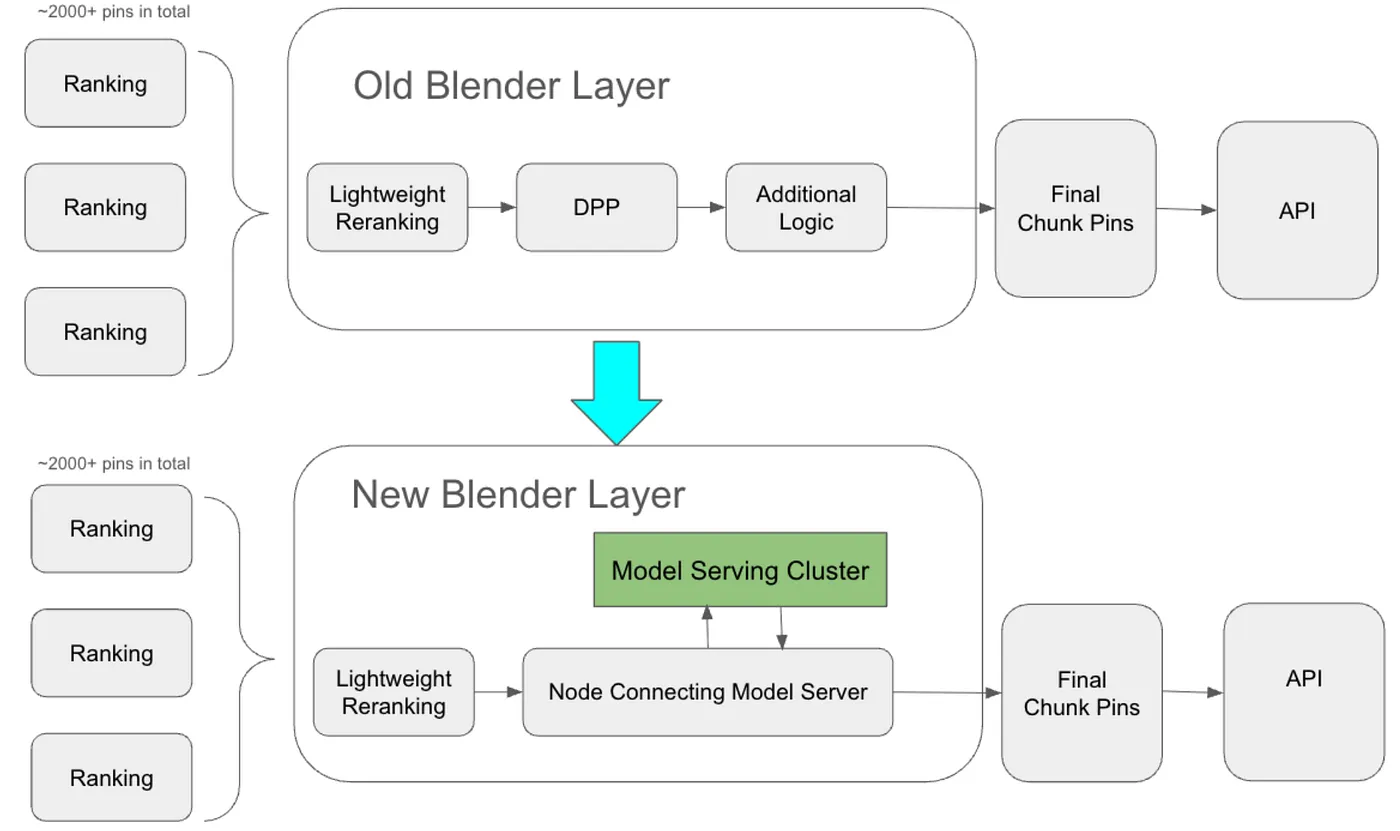
Figure 2. Homefeed Blender System Infrastructure Evolution.
Evolution of Diversity Signals
With DPP, our feed diversification stack relied primarily on categorical signals (taxonomy labels such as home decor, fashion, cooking, etc.) and on GraphSage as the primary mechanism for defining similarity between Pins.
In early 2025, we migrated our diversification process to a CPU-served SSD algorithm implemented in PyTorch. This made it easier to incorporate richer embedding representations when computing pairwise Pin similarity. SSD’s lower serving latency, relative to DPP, allows us to use a broader set of signals. Specifically, SSD uses the following embeddings to represent Pins and drive diversification:
Visual embeddings: capture visual redundancy and style similarity.
Text embeddings: capture overlap in titles and descriptions.
Graph embeddings (GraphSage): capture relatedness in the Pin graph, including co-engagement patterns and neighborhood similarity.
In Q2 2025, we added soft-spacing capabilities to address a business need: reducing clustered content exposure without relying on brittle, one-size-fits-all hard-spacing rules. As part of this work, we incorporated content quality signals that identify content requiring additional caution, allowing SSD to demote a candidate when similar content has appeared within a preceding window.
In Q3 2025, we upgraded SSD’s visual embedding to use PinCLIP image features [10]. PinCLIP provides a stronger multimodal visual representation, learned through image-text alignment with additional graph-aware objectives. Critically, this signal is also available in near real-time, which improves representation quality and, in turn, downstream similarity and diversification behavior, for recently ingested Pins.
More recently, in Q4 2025, we added a Semantic ID signal [11] to address a practical gap: while embeddings are excellent at capturing how close two Pins are, they do not always provide a stable, category-like notion of semantics that is useful for controlling diversity. Semantic IDs provide a hierarchical representation derived through coarse-to-fine discretization of content representations, enabling us to reason more explicitly about semantic overlap between items. In SSD, we discourage recommending too many Pins with high Semantic ID prefix overlap by applying a penalty term. This improves both perceived diversity and engagement by reducing repeated content clusters.
For future works, we are focusing on ensuring diversity across user specific interests and having a proper representation of the interests the user historically engaged with.

Figure 3: Diversity component timeline
On-going and Future Works
Currently, we have various different on-going works to optimize the final layer. This includes two major workstreams: 1) a unified generative post-ranking model that optimizes the final slate generation in an end-to-end manner 2) reinforcement learning based value model.. We will share more details in later blog posts.
Acknowledgement
We would like to thank all of our collaborators across Pinterest. Ruimin Zhu, Yaron Greif, Ludek Cigler, Jason Madeano, Alekhya, Jaewon Yang, Xianxing Zhang
**Reference:
**[1] Establishing a Large Scale Learned Retrieval System at Pinterest
[2] Advancements in Embedding-Based Retrieval at Pinterest Homefeed
[3] Pinterest Home Feed Unified Lightweight Scoring: A Two-tower Approach
[4] Rethinking Personalized Ranking at Pinterest: An End-to-End Approach
[5] TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
[6] Determinantal point processes for machine learning
[7] Practical Diversified Recommendations on YouTube with Determinantal Point Processes
[8] Inductive Representation Learning on Large Graphs
[9] Sliding Spectrum Decomposition for Diversified Recommendation
[10]: PinCLIP: Large-scale Foundational Multimodal Representation at Pinterest
[11] Recommender Systems with Generative Retrieval