AutoAgent: first open source library for self-optimizing agents
today we're releasing AutoAgent, an open source library for autonomously improving an agent on any domain.
AutoAgent hit both the #1 on SpreadsheetBench (96.5%) and the #1 GPT-5 score on TerminalBench (55.1%) after optimizing for 24+ hours
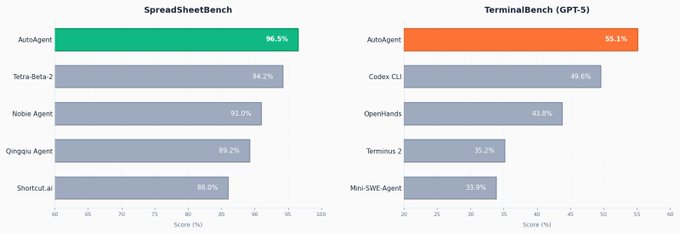
every other entry on those leaderboards was hand-engineered. ours wasn't.
agents have been bottlenecked by harness engineering, yet we're still doing primitive grid search: tweak, eval, read error traces, repeat
this is the first concrete evidence that an agent can autonomously beat manual harness tuning on production benchmarks.
code is available here
here's what it does
point AutoAgent at a task domain with evals. a meta-agent experiments on a task agent's harness: tweaking prompts, adding tools, refining orchestration until performance climbs.
the setup is minimal by design:
- the task agent starts with just a bash tool
- program.md gives the meta-agent its research direction
- agent.py is the task agent
- a Harbor adapter connects to your benchmark
the meta-agent then spins up 1000s of parallel sandboxes to improve the task agent. 24 hours later it has domain-specific tooling, verification loops, and orchestration logic. all discovered autonomously
the loop:
1. edit the agent's harness 2. run it on tasks 3. measure performance 4. read failure traces 5. keep improvements, revert failures 6. repeat
why this works: seeing like an agent
we discovered agents are better at understanding agents than we are
the Claude Code team wrote about "seeing like an agent", putting yourself in the mind of the model, designing tools shaped to its abilities
Feb 28
we project our own intuitions onto systems that reason differently. we're bad at empathizing with models
AutoAgent operationalizes this. the meta-agent reads the task agent's reasoning traces and already has implicit understanding of itself. its own limitations, tendencies. so when it sees the task agent lost direction at step 14, it understands the failure mode as part of its worldview and corrects it
we call this 'model empathy'
practical consequence: Claude meta-agent + Claude task agent outperformed Claude meta-agent + GPT task agent. same-model pairings win because the meta-agent writes harnesses the inner model actually understands. it shares the same weights and knows exactly how that model reasons
as agents surpass 99th percentile human performance, our intuitions about good harness design become the wrong prior. like AlphaZero, they should discover from first principles
emergent behaviors we didn't program
- spot checking: ran isolated tasks for small edits instead of full suite. dramatically sped up iteration, saved compute
- forced verification loops: built deterministic self-checks and formatting validators. budgeted extra turns for self-correction with main budget for the task & bonus turns for verifying and correcting output
- writing tests: steered the task agent to build its own unit tests and checks for each task
- progressive disclosure: dumped long contexts to files when results overflowed
- orchestration logic: built task-specific subagents and handoffs when the domain required it
results
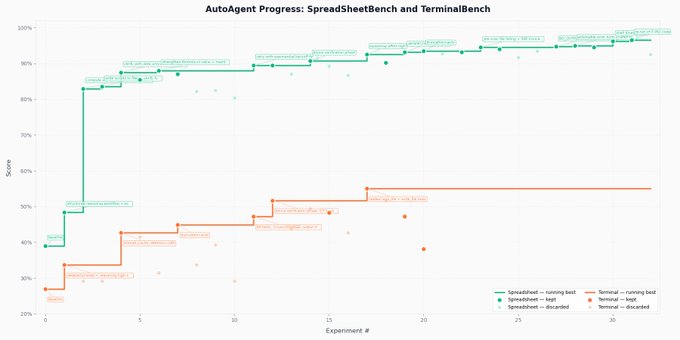
AutoAgent hit 96.5% on SpreadsheetBench and 55.1% on TerminalBench. both were the highest scores in the leaderboard. the agent iterated autonomously across 24+ hours, analyzing its own failure traces and improving
what we learned
- splitting helps. we tried one agent improving itself. didn't work. being good at a domain and being good at improving at that domain are different capabilities. the meta/task split lets each specialize
- traces are everything. when we only gave scores without trajectories, improvement rate dropped hard. understanding why something improved matters as much as knowing that it improved. traces give the meta-agent interpretability over the task agent's reasoning—that's what makes targeted edits possible
- agents overfit. the meta-agent gets lazy, inserting rubric-specific prompting so the task agent can game metrics. we constrain this by forcing self-reflection: "if this exact task disappeared, would this still be a worthwhile harness improvement?"
- meta-agent quality matters. harness edits are often inspired by the meta-agent's own tooling. a poorly designed meta-agent produces poor task agents. Codex doesn't work well as a meta-agent—it ignores instructions to never stop improving (observed in autoresearch too), and the resulting task agent gives up too early
why this matters
the hard part of building agents: every domain needs a different harness, and harness engineering requires someone who deeply understands both the domain and how models behave
AutoAgent collapses that. domain experts just define what success looks like. the meta-agent figures out the harness
companies don't have one workflow to automate, they have hundreds. each needs a different harness.
no team can hand-tune hundreds of harnesses. a meta-agent can
this is infrastructure for agent fleets: continuously spinning up, optimizing, and maintaining task-specific agents across entire organizations
what's next
we built AutoAgent internally but decided to open source it: https://github.com/kevinrgu/autoagent
describe a spec, point it at evals, let it climb. everyone should be able to do this
self-improving agents are still in their infancy. next frontier: harnesses that dynamically assemble the right tools and context just-in-time for any task
we're releasing a product around this soon. early access in comments