Lyft’s Feature Store: Architecture, Optimization, and Evolution
[
Lyft Engineering
](https://eng.lyft.com/?source=post_page---publication_nav-25cd379abb8-7835f8962b99---------------------------------------)
[

](https://eng.lyft.com/?source=post_page---post_publication_sidebar-25cd379abb8-7835f8962b99---------------------------------------)
Stories from Lyft Engineering.
Introduction and Core Purpose
Lyft’s Feature Store stands as a core infrastructural pillar within its Data Platform organization, designed to optimize the management and deployment of Machine Learning (ML) features at massive scale. Its primary objective is to centralize feature engineering efforts, guaranteeing uniformity across diverse models and workflows that perform important data-driven decision making across the entire rideshare stack. By streamlining the entire lifecycle — from feature creation and storage to low-latency access and high-throughput processing — it facilitates effective offline and online model training and inference.
This post will provide a refreshed look (since 5 years ago) at the architectural evolution, practical applications, performance tuning, and significant improvements in developer experience we’ve performed over the past few years to improve efficiency, scalability, performance, and user accessibility. Ultimately, we aim to illustrate how the Feature Store empowers Lyft engineers to develop highly effective service components and ML models, a capability that is becoming vital for emerging AI and Large Language Model (LLM) applications.
Defining Our Audience and Impact
Before diving into the system’s architecture, it’s essential to understand the importance and breadth of our user base. Our product is mission-critical, serving diverse engineering functions across the company.
Feature Service impact goes far beyond just these examples.
Understanding this subset of varied high-impact use cases (just five of 60+) is key to appreciating the necessary robustness and flexibility of the Feature Store design.
The Feature Store Architecture: A Platform of Platforms
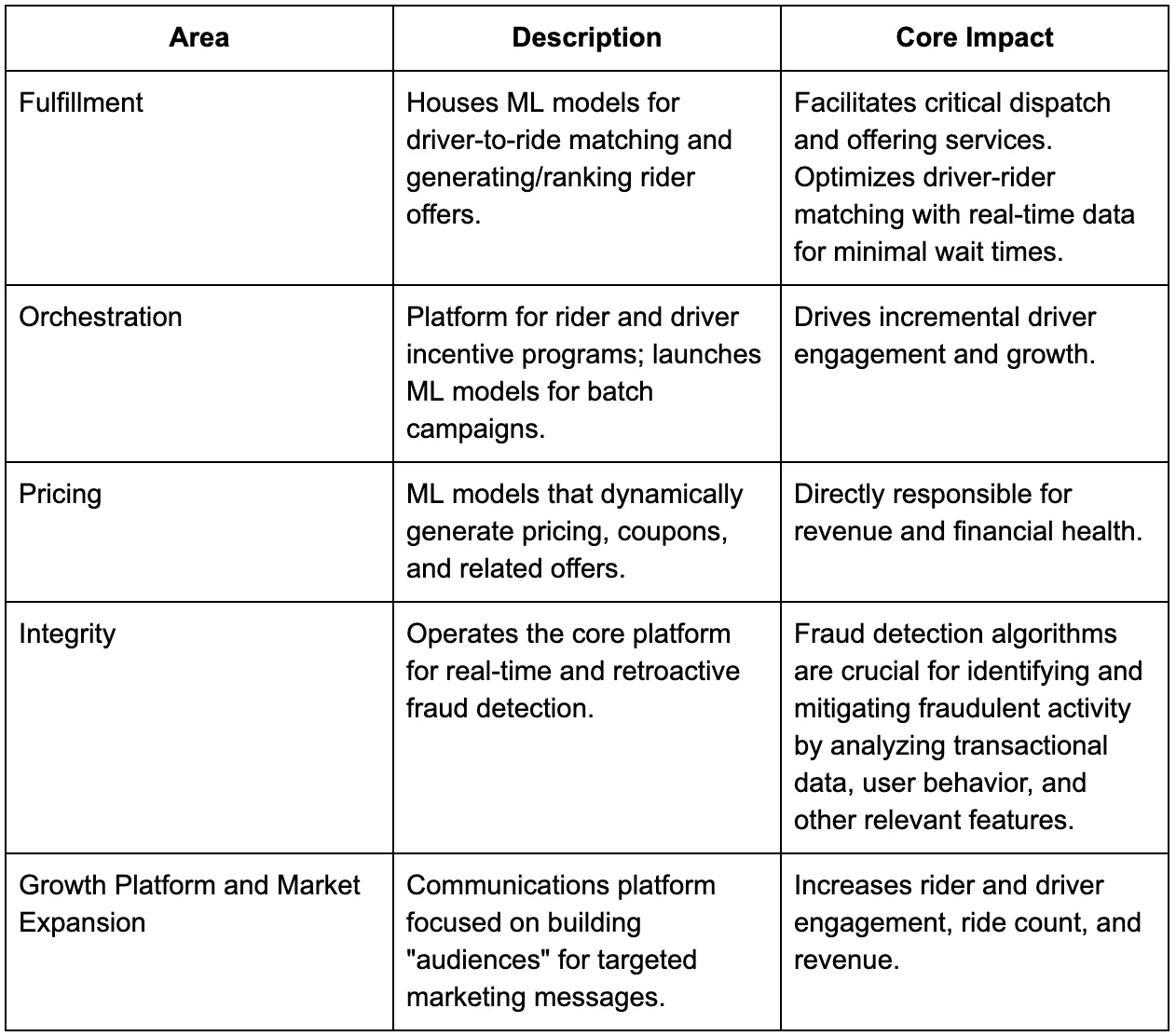
Our system is best described as a platform of platforms. While the full architecture diagram is complex, we can break it down into three digestible components: Batch, Online, and Streaming features.
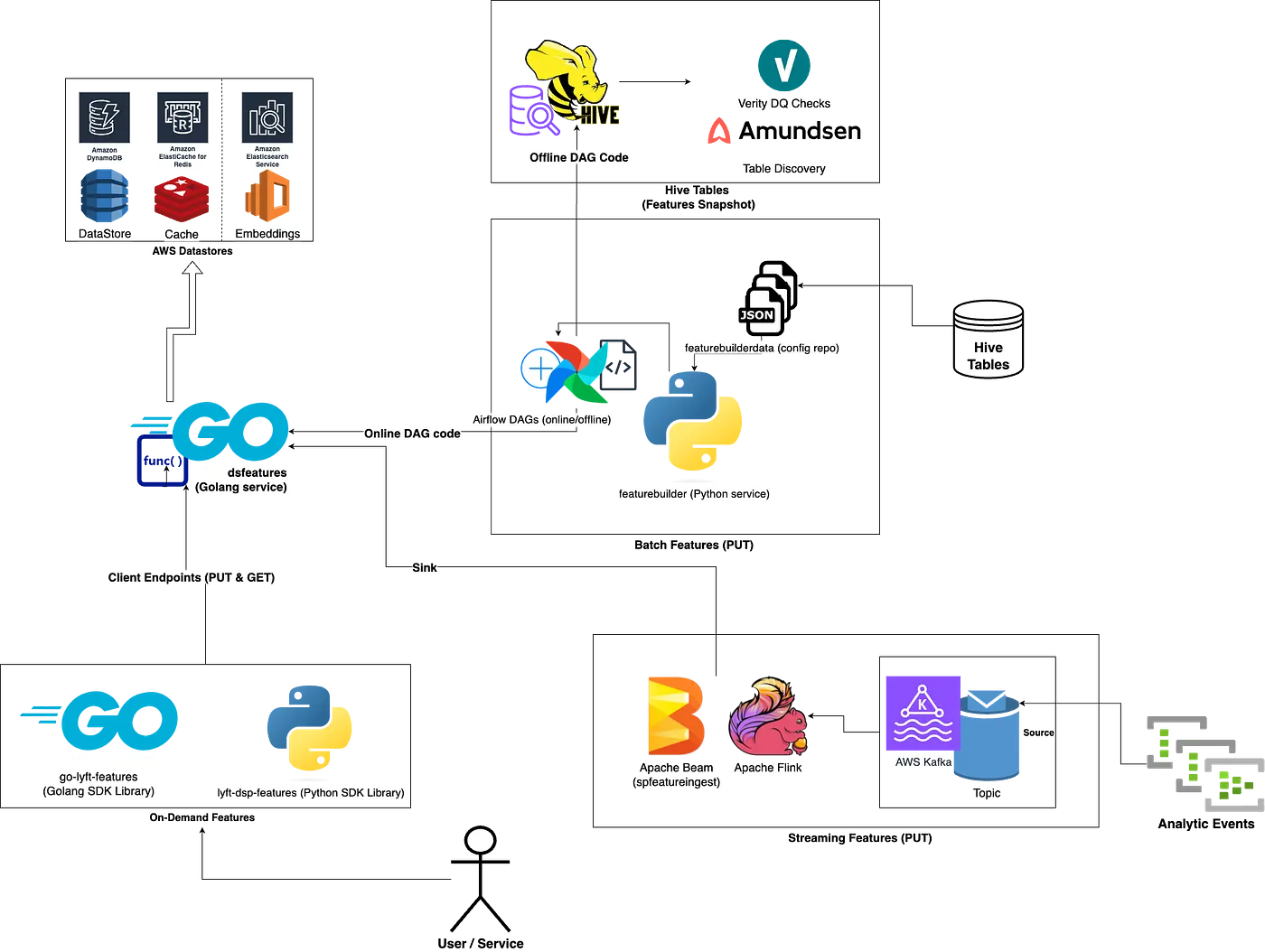
A “draw.io” architecture diagram of Lyft’s Feature Service.
Batch Feature Ingestion and Serving
Batch features are the most widely used family of features within our platform. These features are defined from existing Hive data tables and represent a set of standardized data points that are calculated and refreshed on a set cadence, typically on a daily basis.
The ingestion process begins when customers define features using a Spark SQL query and a simple JSON file representing the dedicated configuration metadata.
A Python cron service reads these configurations and automatically generates an Astronomer-hosted Airflow Directed Acyclic Graph (DAG). Crucially, these generated DAGs are production-ready out-of-the-box. They handle:
- Executing the Spark SQL query to compute the feature data
- Storing the feature data to both the offline and online data paths
- Running integrated data quality checks
- Compatibility for feature discovery
The executed DAG generates a dataframe and delivers the results to two distinct paths:
- Offline Data Path: The feature data is stored in Hive tables for historical data analysis and machine learning model training.
- Online Data Path: The processed features are translated and sent to our low-latency online serving layer for real-time inference.
The Online Serving Layer
Our online serving layer, referred to as dsfeatures (short for “data science features”), is central to our feature serving capability. It is an optimized wrapper over various AWS data stores, providing a reliable and ultra-low-latency retrieval mechanism for real-time serving.
The core structure of dsfeatures is:
- Backing Store: DynamoDB is utilized as the primary, persistent source for features. It uses various metadata fields as the primary key with a GSI for GDPR deletion efficiency.
- Performance Cache: A ValKey write-through LRU cache is deployed on top of DynamoDB to facilitate ultra-low-latency retrievals by storing the most frequently-accessed (meta)data with a generous TTL.
- Embeddings: An OpenSearch integration is utilized specifically for serving embedding features, which require specialized indexing and retrieval capabilities.
Customer Interaction and Data Retrieval
The dsfeatures service centralizes how both internal DAGs and external customers interact with the feature data. From a customer’s perspective, data retrieval and management are straightforward, facilitated by our dedicated Software Development Kits (SDKs): go-lyft-features (Golang) and lyft-dsp-features (Python).
Services utilize these SDKs to make API calls directly to the dsfeatures service. The most common retrieval methods are Get or BatchGet calls, which the service handles and returns the requested data in a developer-friendly format.
Crucially, the SDK libraries expose full CRUD (Create, Read, Update, Delete) operations. This capability allows system components, such as our internal Airflow DAGs, to read and write features, and even lets customers manage real-time features ad-hoc by directly invoking these API calls against our data stores.
The Streaming Pipeline
While batch features are essential, we also rely on streaming features to ensure data recency for low-latency applications and customer demands.
Our streaming pipeline follows a robust, multi-stage architecture to process features in real time.
- Ingestion: Streaming applications, developed primarily using Apache Flink, read analytic events from Kafka topics (or sometimes Kinesis streams).
- Transformation: The Flink applications perform necessary initial transformations on the data. This includes manual metadata creation and proper value formatting.
- Ingest Service: The feature payloads from customer applications are sunk to
spfeaturesingest— our “Streaming Platform feature ingest” Flink application. It handles the (de)serialization of the payloads and subsequent interaction withdsfeaturesvia WRITE API call(s) to ensure the features are processed in the right format, guaranteeing availability for online retrieval by other services.
Regardless of the ingestion method (batch, streaming, or on-demand), the Feature Store maintains uniform metadata and strongly consistent reads. This is crucial for ensuring feature accuracy and availability across all consuming applications and services.
Prioritizing User Experience and Feature Governance
Understanding our architecture is only half the picture; the user experience is central to maximizing productivity. Our Feature Store primarily serves two frequent personas: Software Engineers (who drive service activity) and ML Modelers (who design features and models). Since developers can often embody both roles or work in mixed teams, we’ve designed our system to simplify interaction for everyone.
Ease of Use and Quick Iteration
We learned early on that our core personas are particularly proficient in SQL and place a high value on quick iteration. To facilitate this, our design centers on:
- Performant SparkSQL as the preferred processing engine and language for batch feature queries.
- Simple JSON configuration files to define feature behavior/metadata.
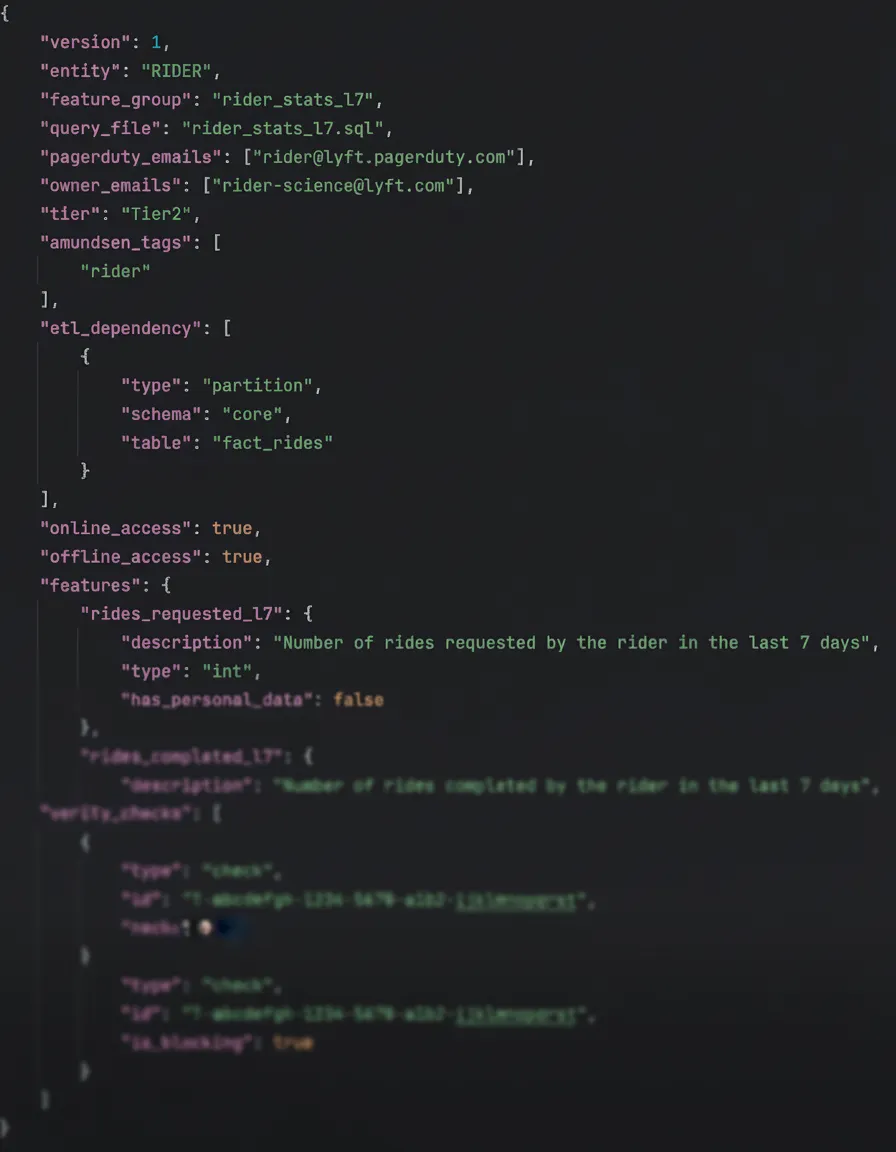
Example JSON configuration
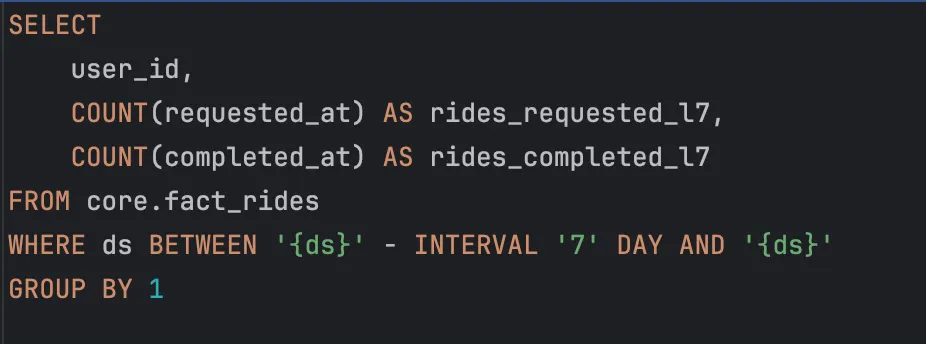
Example (simplified) SparkSQL query
This approach ensures that developers can focus on their primary responsibilities without technical intricacies getting in their way. The Feature Store presents this user-friendly interface and APIs that simplify interaction, minimizing the learning curve and facilitating rapid adoption. Engineers can readily register, update, and retrieve features using well-documented APIs and well-supported examples.
Feature Governance and Metadata
Our configuration files include essential metadata such as ownership details, urgency tiering, run-to-run carryover/rollup logic, and explicit feature naming & data-typing. This metadata is crucial for more than just customer clarity; it is vital for our monitoring and observability systems, aiding in debugging and providing posterity of feature history (both metadata and values).
Get Rohan Varshney’s stories in your inbox
Join Medium for free to get updates from this writer.
To support robust feature management, the Feature Store incorporates versioning and lineage tracking capabilities, encapsulated in our metadata:
- Versioning allows developers to monitor changes to features over time, ensuring the use of correct versions for their models/services. If the SQL or expected feature behavior undergoes business logic changes, a version bump is expected.
- Lineage tracking offers crucial insights into the origin and transformation of features, enhancing both transparency and accountability across the platform.
Accelerating the Feature Engineering Workflow
To complement our simple SQL/JSON foundation, we’ve integrated with Kyte to accelerate the development lifecycle. This homegrown solution is central to Airflow local development at Lyft — more about Kyte can be learned here.
We provide a custom Command Line Interface (CLI) within the Kyte environment that significantly improves the feature prototyping experience, allowing users to:
- Perform feature validation against their configurations.
- Test SQL runs for immediate feedback and investigable results.
- Execute DAG runs in a local environment.
- Confidently backfill previous dates against their DAGs.
Feature Discoverability
Once features are generating data, discoverability is the next crucial step. Our generated DAGs automatically tag feature metadata within Amundsen, Lyft’s central data discovery platform. This integration allows users to easily search for existing features, a critical step in preventing the duplication of efforts and reducing wasted engineering work.
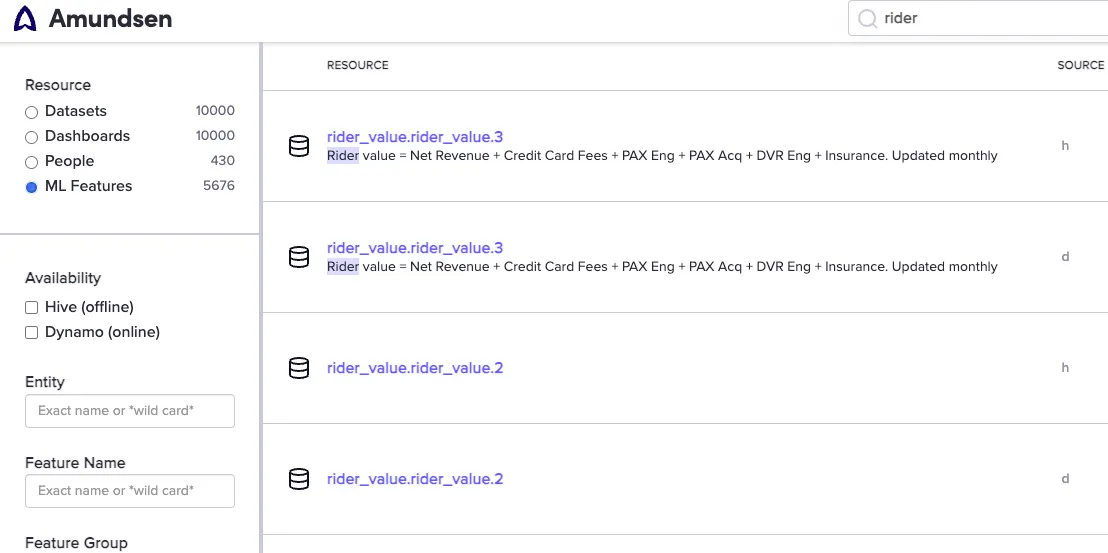
Example of Amundsen UI for ML features
By simplifying data discovery and feature engineering, we solidify the Feature Store’s crucial role in the ML Model Development lifecycle, ensuring a strong partnership with our Machine Learning Platform (MLP) team, which owns the remaining model-building steps.
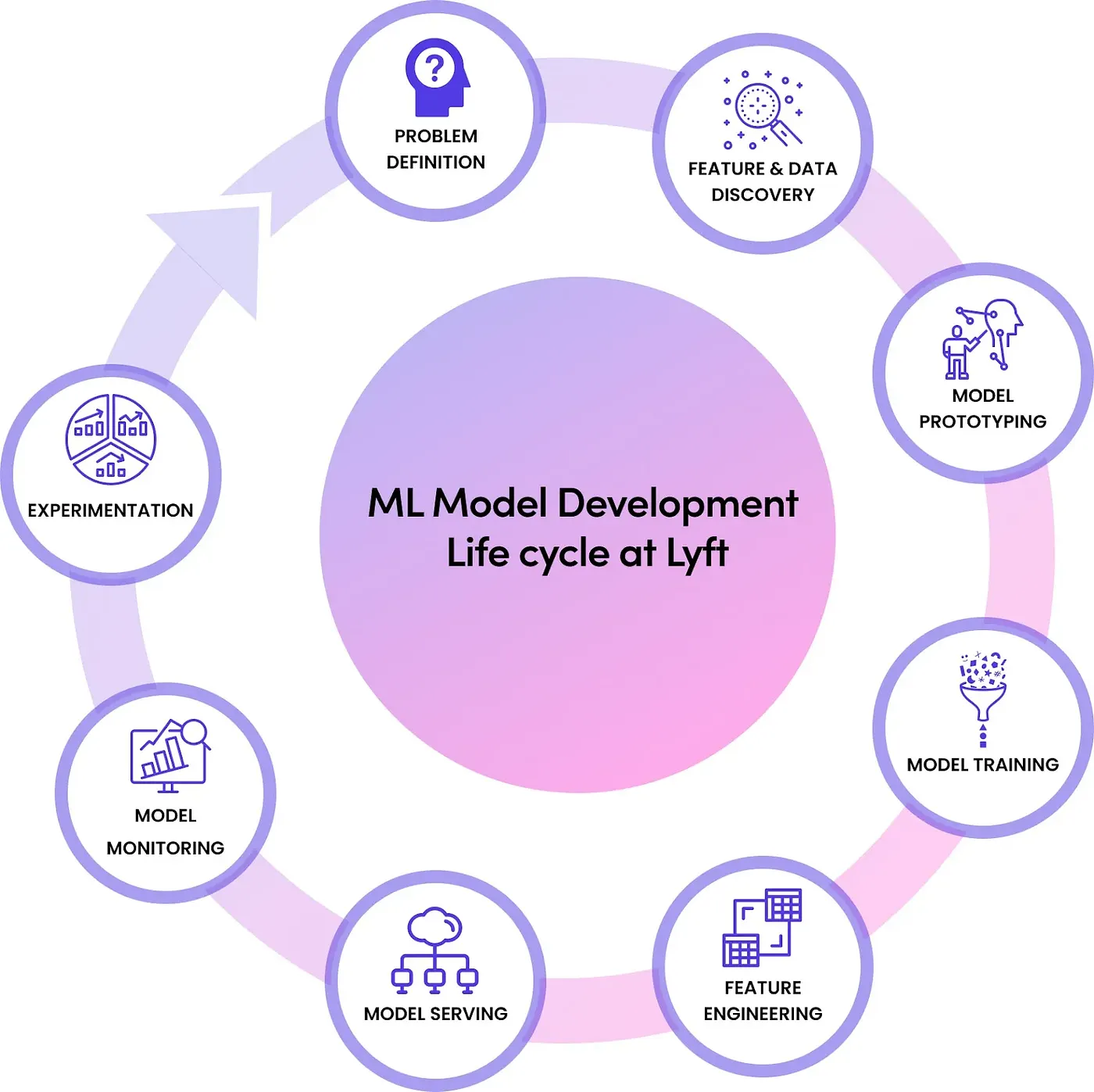
Image originally from Konstantin Gizdarski’s article, “ Building Real-time Machine Learning Foundations at Lyft .”
Platform Evolution and Prioritization
While our current setup is robust, it has evolved significantly. We made deliberate, strong steps to prioritize efficiency and improved customer experience over the last few years.
Streamlining for Core Success
- Orchestration Migration: We completed two migration hops, ultimately transitioning our core orchestration platform from in-house Flyte to fully-managed Astronomer (tradeoffs discussed here). This offloads ETL platform stability issues to external engineers while allowing our Orchestration team to invest in higher priority internal initiatives.
- Niche Support: In the spirit of the Pareto principle, we removed compatibility for alternative query engines like HiveQL and Redshift. This allowed us to reduce support for minor niche use cases and invest more deeply in our core use cases that drive the most value for Lyft.
- Staging Environment: We unlocked a reliable staging capability for our platform, boosting confidence in the release of urgent or sensitive features through easier prototyping and E2E testing in non-production environments.
- Standardizing Access: We developed the long-requested Golang SDK and an offline-data Python SDK. These normalize customer activity against our data, making it more monitorable, accessible, and understandable.
- Data Contracts: We are actively implementing the organization’s “Data Contracts” initiative, which enforces explicit expectations regarding feature freshness, ownership, and quality. This is crucial for maintaining trust as data generation scales rapidly.
Investing in New Capabilities
- Streaming Abstraction: A
RealtimeMLPipelineinterface was designed for Flink applications, aiming to make generating streaming features a low-friction process and meeting growing internal demand. - Embedding Support: We integrated OpenSearch into the entire Feature Store stack to support embedding features, which has generated significant interest and new use cases.
- Staffing Investment: Significant new staffing is being dedicated to the Stream Compute team, reflecting the rising importance and complexity of this class of features. See Lyft Careers for open roles!
Optimization: Transparency and Lean Retrieval
With a platform of this size and importance, efficiency is in continuous battle against egregious bloat. Our recent optimization strategy focused on two core areas: transparency and reliability.
Data Generation: Transparency
For the generation pipeline, we focused on transparency. Improved monitoring against failed DAGs and tasks, coupled with strong ownership tracking, has made debugging faulty features significantly easier. This, in turn, has provided the confidence to actively deprecate unused or incorrectly used features, ensuring a healthier, more maintainable feature space for the platform team while saving resources for others (f.e. less wasted Spark compute & Astronomer task scheduling resources).
Data Retrieval: Reliability
Our customers’ primary requests for retrieval improvements centered on two metrics: better latencies and higher success rates. Given that AWS datastores are our main source of unpredictable transient failures and high P999 tail latencies (latency is generally not part of their SLAs), our strategy was to focus on being as lean as possible to make this less likely & disruptive:
- Cache Modernization: We upgraded our cache technology and version, adopting ValKey as the latest solution over ElastiCache.
- Payload Optimization: We removed unnecessary fields from the retrieval code path and the cache payload to reduce data transfer size and processing time.
- Rightsizing: We right-sized our EKS pods in
dsfeaturesto minimize the aggregate number of necessary Redis connections, which historically resulted in networking issues. - Policy Hardening: We improved retry and timeout policies both within customer services and our own SDKs to prevent premature network exits and degraded success rates.
- TTL Management: We increased the cache TTL (Time-To-Live) as much as possible for both feature values and the metadata used in retrieval decision-making, carefully balancing latency performance against storage cost.
Results: Unprecedented Growth and Performance
These focused adjustments and improvements led to remarkable trends across the platform.
- Latency Reduction: We cut the standard P95 latency experience during read operations by a full third. This had a tangible downstream effect, evidenced by increased customer SRs and a significant reduction in customer-support threads in our internal Slack channels, directly aiding on-call engineers.
- Batch Feature Growth: Our batch features, the largest family by volume, grew by over 12% year-over-year. This growth occurred despite our active feature deprecation efforts, suggesting a highly positive experience and deepening partnership from the teams that utilize our platform.
- Caller Growth: The number of distinct production service callers increased by almost 25% over the last year. Since each distinct caller represents a fundamentally unique use case — whether a separate service or a new facet within an existing one — it strongly validates the company’s increasing appetite for feature usage and the value it brings.
- Scale of Activity: Aggregate R/W activity on the platform increased by over a trillion in raw count, based on conservative extrapolation. This serves as a powerful reminder of the enormous and continuously growing scale at which our platform operates.
Considering the remarkable progress of the past year, the potential for future growth and impact is truly immense.
Conclusion
Lyft’s Feature Store is a testament to robust data infrastructure, propelling ML excellence and operational efficiency within the company. Its architecture effectively addresses the complexities inherent in managing and deploying ML features at scale. This strategic approach ensures Lyft remains at the forefront of data-driven decision-making.
More than just a data management tool, the Feature Store at Lyft serves as a vital catalyst for innovation and a key enabler of Lyft’s overarching mission: to serve & connect.
As the machine learning landscape continues its rapid evolution, the Feature Store will undoubtedly retain its critical role within Lyft’s data strategy, driving advancements and solidifying Lyft’s leadership in data-driven technology. We are truly excited to see what the future holds, and see how we can continue to serve & connect our customers.
Acknowledgements
I would like to thank Devon Mittow, Janice Lee, Yigal Kassel for all their direct contributions to the feature space. The charter’s achievements would not have been possible without them.
Further thanks to Maheep Myneni, Arda Kuyumcu, and Aniruddh Adkar for being incredible team members whose collaboration and support unlocked the confidence to embark on all these important projects & developments.
Finally, thanks to Prem Santosh Udaya Shankar, Rohit Menon, Arbaz Mirza, Konstantin Gizdarski, Yunhao Qing and Brian Balser whose technical and management support, past and present, led to this charter’s overall success and growth.
Further Reading
- Learn about our RTML architecture: Building Real-time Machine Learning Foundations at Lyft by Konstantin Gizdarski and Martin Liu
- Learn about a major RTML use case: Real-Time Spatial Temporal Forecasting @ Lyft by Rakesh Kumar and Josh Xi
- Learn about our ML platform architecture: LyftLearn Evolution: Rethinking ML Platform Architecture by Yaroslav Yatsiuk
Lyft is hiring! If you’re passionate about Infrastructure & Data Platform, visit Lyft Careers to see our openings.
Responses (1)Write a response
[
What are your thoughts?
](https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Feng.lyft.com%2Flyfts-feature-store-architecture-optimization-and-evolution-7835f8962b99&source=---post_responses--7835f8962b99---------------------respond_sidebar------------------)
Brilliant insights! Your writing style makes complex topics accessible.
[
](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fvote%2Fp%2Fc184732dbb6a&operation=register&redirect=https%3A%2F%2Fiknahar.medium.com%2Fbrilliant-insights-your-writing-style-makes-complex-topics-accessible-c184732dbb6a&user=Kamrun+Nahar&userId=df89b702f339&source=---post_responses--c184732dbb6a----0-----------------respond_sidebar------------------)