Next-Level Personalization: How 16k+ Lifelong User Actions Supercharge Pinterest’s Recommendations
[

Xue Xia | Machine Learning Engineer, Home Feed Ranking; Saurabh Vishwas Joshi | Principal Engineer, ML Platform; Kousik Rajesh | Machine Learning Engineer, Applied Science; Kangnan Li | Machine Learning Engineer, Core ML Infrastructure; Yangyi Lu | Machine Learning Engineer, Home Feed Ranking; Nikil Pancha | (formerly) Machine Learning Engineer, Applied Science; Dhruvil Deven Badani | Engineering Manager, Home Feed Ranking; Jiajing Xu | Engineering Manager, Applied Science; Pong Eksombatchai | Principal Machine Learning Engineer, Applied Science

Background
The Pinterest home feed is crucial for Pinner engagement and discovery. Pins on the home feed are personalized using a two-stage process: initial retrieval of candidate pins based on user interests, followed by ranking with the home feed (Pinnability) model. This model — a neural network consuming various pin, context, and user signals — predicts personalized pin relevance to improve user experience. Its architecture is illustrated in the following figure.

In 2023, we published TransAct (arXiv), where we use transformers to model the Pinner’s last 100 actions in Pinnability. One shortcoming of that approach is that we are unable to model the user’s lifelong behavior on Pinterest.
Today, we will talk about solving that. We do this through TransActV2, which features three key innovations:
- Leveraging very long user sequences (160x compared to V1) to improve ranking predictions
- Integrating a Next Action Loss function for enhanced user action forecasting
- Employing scalable, low-latency deployment solutions tailored to handle the computational demands of extended user action sequences
Please reference our PDF on arXiv (link) for a thorough technical deep dive on TransActV2.
The Need for Lifelong Behavior Modeling
Why care about a user’s actions from weeks, months, or even years ago?
- Interests evolve: Someone who looks for gardening tips each spring and Halloween ideas each fall may not display those behaviors in their recent 100 actions.
- Personalization should be rich: Short action windows miss out on long-term, multi-seasonal, and less-frequent interests.
- High-scale challenges: Storing and processing long user histories for hundreds of millions of users is a massive engineering hurdle, leading most systems to compress, cache, or ignore older data.
TransActV2 addresses these fundamental challenges and unlocks a new frontier for lifelong, real-time personalization at Pinterest.
Modeling Lifelong User Sequences
TransActV2 introduces several technical advances:
- Ability to model up to 16,000 user actions: a 160x scale-up over previous systems.
- Integration of explicit action features: timestamp, action type (multi-hot encoded), action surface (home feed/search), and a 32-d PinSage embedding for content.
- Actions are stored losslessly using int8 quantization for compactness.
Formally, the lifelong (LL) sequence S_{LL} is defined for each user as a chronologically-ordered series of tokens, where each token contains the above features. To reduce storage, the PinSage vector e (32-dim float16) is quantized:
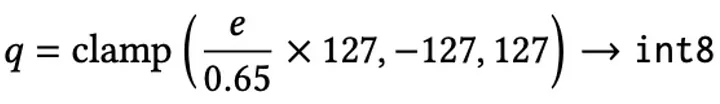
Nearest Neighbor (NN) Selection:
At ranking time, most user sequences are still far longer than any single pin’s context requires. TransActV2 solves this by only selecting the following for each candidate pin c:
- The most recent r actions
- The top K nearest neighbors from the lifelong, real-time, and impression sequences, based on dot-product similarity in PinSage embedding space
Mathematically:

Where NN(S,c) selects actions in S most similar to c, using PinSage embeddings EPinSage. The final user sequence fed to the model is:

_⊕ denotes concatenation; S_ʀᴛ _is the real-time sequence and s_ᵢₘₚ the impression sequence.

Fig 3: Transact V2 Architecture
The model is a multi-headed, point-wise multi-task network over a wide & deep stack:
The model is a multi-headed, point-wise multi-task network over a wide & deep stack:
- Representation layers: All features, including the sequence features, are first embedded appropriately:
- Action types and surfaces are embedded and summed.
- PinSage embeddings are concatenated (early fusion) with candidate pin embedding.
- Positional encoding is learned.
2. Transformer Encoder: Two-layer self-attention, one attention head per layer, model dimension 64, with feedforward 32-dim sublayers. Causal masking is enforced so the model cannot “peek ahead.”
3. Downstream Heads: Output tensor is pooled (max pooling + linear layer). Feature crossing and MLP layers create the outputs for various actions (e.g., click, repin, hide).
Next Action Loss (NAL): Enhancing Action Forecasting
Traditional Click-Through-Rate (CTR) models use cross-entropy loss:

Where H is the set of action heads. f(x)h is the predicted probability for head h.
TransActV2 introduces the Next Action Loss (NAL) as an auxiliary task. This challenges the model not just to predict probability of engagement, but — given today’s context and history — what will the user do next?
For the user representation at time step t [represented as u(t)], and the positive pin embedding at t+1 [represented as pu(t+1)], the NAL is:

Where ⟨⋅,⋅⟩ is inner product and nu are negative (non-engaged) samples. The loss is combined with the main ranking loss:

Negative Sampling:
Impression-based negative samples (pins shown but not engaged) are much more effective than random negative sampling, improving both repin accuracy and reducing inappropriate content recommendations. Offline, impression-based NAL improved top-3 hit rates by over 1% and reduced negative events by over 2%.
Industrial-Scale Engineering: Efficient Serving and Deployment

Handling lifelong sequences in production brings unique systems challenges:
Naive approach: O(NL) data movement for L=10,000+ sequence tokens and N candidate items per ranking request.
Solution:
- Nearest Neighbor feature logging: Only store NN features during training, and use O(1) instead of O(L) storage.
- On-device NN search at inference: Full sequence is read, but only the top relevant actions (as above) are broadcast to the model for each candidate pin.
- Custom OpenAI Triton kernels for serving.
Key Serving Optimizations:
Fused Transformer (SKUT):
- Single custom Triton kernel merges QKV projection, attention, layer norm, and feed-forward. With model dimension 64, all weights fit in 6 MB of GPU SRAM.
- Achieves 6.6x speedup over Flash Attention for small transformer layers; avoids repeated memory allocations and intermediate tensor copies.
Pinned Memory Arena:
- Thread-local, pre-allocated, and reusable; eliminates pageable-to-pinned overhead.
- Combined with request de-duplication, increases inference speed by up to 35%.
Request-level de-duplication:
- Only one copy of the user sequence is sent to the GPU per request; sparse tensor/offset format tells the model kernel how to split over N candidate items.
- 8x PCIe data transfer reduction.
Results:
Stacked together, these changes yielded 75–81% lower p99 model run latency at every batch size evaluated. End-to-end inference latency decreased by 103–338x (p50–p99) compared to baseline.
Real-World Impact: Massive Improvement at Pinterest Scale
At Pinterest’s scale with more than 570 million monthly active users (MAU)¹, even a fractional percent improvement translates to millions more meaningful engagements. Prior to TransActV2, offline and online lifts for home feed ranking models were typically incremental; most established deep learning recommenders see monthly gains on the order of 0.1 to 0.3%. The step change we saw provided by TransActV2 was exceptional.
By leveraging lifelong sequences and Next Action Loss with impression-based negatives, TransActV2 achieves the largest jumps in offline metrics ever recorded in our production pipeline. Compared to prior systems (TransAct V1 and production BST), TransActV2 (RT + LL + NALimp) achieves:
- +13.31% Top-3 Repin Hit is a more than 2x improvement over previous systems.
- –11.25% Top-3 Hide Hit reflects dramatic gains in surfacing less spammy, more relevant pins.
- These numbers are absolute improvements over strong, already well-calibrated baselines.
Online Results: Direct User Engagement
In a real-world A/B test on 1.5% of home feed traffic (representing millions of users):

- 6.35% Repin increase means many millions more ideas saved, shared, and tried.
- 12.8% fewer Hides signals less frustration and more value from the content shown.
- Increased diversity reduces the feeling of “echo chamber” and improves serendipitous discovery.
- +1.41% time spent signals improved session quality and stickiness.
To put this in perspective: previous model launches over the past two years typically achieved lifts around 0.2–1%. This means TransActV2’s gain is up to an order of magnitude larger.
Statistical Significance
All key metrics in both offline and online evaluation were found statistically significant (p < 0.01) and persistent over multiple test runs and surfaces.
Conclusion
TransActV2 sets a new benchmark for lifelong user sequence modeling in online industrial recommender systems:
- Full-sequence learning and retrieval unlocks rich long-term patterns and diversity.
- Next Action Loss empowers better sequence prediction and user journey modeling.
- Custom system optimizations make lifelong deep learning tractable at global scale, with sub-100ms latency.
This work represents a joint leap in deep learning, recommendation theory, and large-scale engineering. The future of home feed personalization is ever more dynamic, diverse, and rewarding for millions of Pinterest users.
¹ Pinterest analysis, global, Q1 2025