Fixing duplicate stories in Medium’s For You feed
A few months ago we started getting reports of stories appearing multiple times in the For You feed on Medium mobile apps. See for instance the screenshot below, in which the “Breaking News: Stuff actually costs a lot” story is listed twice:

Instrumentation showed that there were around 4K occurrences per day of duplicate stories on iOS and around 3K occurrences per day on Android. We also received reports of duplicate stories appearing in the For You feed in the web app. So we started investigating.
The For You feed under the hood
Before we dive into how we fixed the issue, let’s take a look at how the For You feed works under the hood.
Anatomy of a For You feed request
In order to retrieve the content of the For You feed, a client app — web, iOS, or Android — performs a request to Medium’s GraphQL API layer. GraphQL then forwards that request to the rex (recommendations) service, implemented in Go, which computes the feed content (with the help of other downstream services) and returns it to GraphQL. GraphQL then forwards the response to the client app. This is summarized in the diagram below (downstream services called by the rex service aren’t represented as they don’t really matter here):

Requests to retrieve the For You feed are also paginated, as the feed can contain hundreds of stories. When requesting a page, the client app specifies the maximum number of stories to retrieve and, optionally, the cursor returned in response to the request for the previous page. This cursor is used by the rex service as a way to identify where the next page begins.
So, conceptually, the request to retrieve the first page of the For You feed looks like this:
In addition to a list of the items in the page, the response to this first request specifies the cursor for the second page:
{
items: [...]
nextPage: {cursor: "10"}
}
The next request to retrieve the second page then passes this cursor information, as follows:
forYou({limit: 10, cursor: "10"}) {
}
And the response to this second request specifies the cursor for the third page, and so on:
{
items: [...]
nextPage: {cursor: "20"}
}
Generating and caching For You feed instances
Conceptually, the endpoint handling For You feed requests in the rex service is implemented like this (using Go-like pseudo-code):
f := FetchFromRedis(ctx, userID)
if !f { f := GenerateFeed(ctx, userID) StoreInRedis(ctx, userID, feed)}
return ExtractPage(f, paging)
When the For You feed is requested and no cached value is available, a new feed instance is generated by the rex service. By design, two generation operations for the same user will return two different feed instances; this ensures that you see different story recommendations when you open Medium and when you refresh the feed. Although these two feed instances will be different, they will usually contain at least some of the same stories (though in different positions in the feed).
Once a feed instance has been generated, it is then stored in a Redis cache owned by the rex service. At the time duplicate stories were reported, the key identifying the feed instance in the Redis cache was built using the following template: $userId:HOMEPAGE (this has changed since then, see below). A cached feed instance also has an associated time-to-live (TTL) value of 30 min (this also has changed since then, see below); after this TTL has been reached, Redis automatically evicts the feed instance from the cache.
Now that we understand the machinery behind the For You feed, let’s dive into the changes we brought to fix the bug.
Change #1: Fix premature cancellation of cache store operations
At the time the bug was reported, the rex service (implemented in Go) was delegating the storage of newly generated feed instances in the Redis cache to background goroutines, without waiting for these goroutines to complete. Or, at least, that’s what we thought the rex service was doing… Even though the code was run in a background coroutine as expected, it was using the request context, a context associated with the upstream request. One of the defining characteristics of a request context is that it is canceled as soon as the request completes. This implies that the code storing feed instances in Redis would sometimes be canceled in a nondeterministic way, potentially before the Redis cache had been updated, as illustrated below:

This ended being one of the root causes of duplicate stories. See for instance the sequence of events represented below:

When a client requests the first page of the For You feed and no feed instance is available in the cache, the rex service, as described above, generates a new feed instance A, starts a background goroutine to store feed instance A in Redis, and returns the first page of feed instance A. If the request context is canceled before the background goroutine completes its work, feed instance A ends up not being stored in Redis. Later, when the client requests the second page of the For You feed, the rex service generates yet another new feed instance B (because there is no feed instance in the cache), then returns the second page of feed instance B. The client thus retrieves two pages from two distinct feed instances (A and B); as we’ve seen above, these two different feed instances might contain some of the same stories, though in different positions, which would sometimes result in the same story appearing in both pages.
The fix for this issue was rather simple: create a true background context and use this context, instead of the request context, to run the cache store operation in the background goroutine. This is illustrated below:

Side note: Using background goroutines to store feed instances in the cache can theoretically create race conditions when the second page of the feed is requested immediately after the first page has been returned. In practice though, the additional time costs incurred by returning the response all the way up to the client and by unmarshaling the response by the client make this an unlikely situation.
Change #2: Ensure cached feed instances are reused when available
As explained above, a cached feed instance is stored in Redis with a time-to-live (TTL) set to 30 min. Depending on usage patterns, this could easily result in the For You feed listing duplicate stories. Imagine a person opening Medium and starting to read stories in the first page of the For You feed. Imagine then that this person either takes more than 30 minutes to read all the stories in the first page, or is away from Medium for more than 30 minutes and then comes back to where they left. At some point the Medium app will request the second page of the For You feed. As more than 30 minutes have elapsed since the first page was requested, the feed instance that was used to return the first page has been evicted from the cache; thus the rex service generates a new feed instance and returns the second page of this new feed instance. Just as for the issue fixed by change #1, this would then sometimes result in the same story appearing in both the first and second pages. This is illustrated below:

We fixed this situation in two steps: first, rely on feed instance IDs across requests; second, update the TTL logic for cached For You feed instances.
Relying on feed instance IDs across requests
As we’ve seen earlier, clients requesting a page from the For You feed passed two parameters in the request: a limit (mandatory) and a cursor (optional); these two parameters define a view on the requested feed instance. There was however no notion of which feed instance was being requested. The rex service would always return a page from the current feed instance if there was one, or from a newly generated feed instance otherwise, in which case this feed instance would then become the new current feed instance.
In order to better support all usage patterns, we updated the request chain so that an ID uniquely identifying the feed instance was returned whenever a page from the For You feed was requested. We extended the format of the cursor parameter to include a feed instance ID; this way, a client app would (automatically, without actually knowing anything about feed instance IDs) pass the feed instance ID received in response to the request for page N when requesting page N+1. Conceptually, the cursor changed from a simple offset ("10") to a tuple made of a feed instance ID and an offset ({feedId: "1234", cursor: "10"}). And the rex service was also updated in order to take feed instance IDs into account when serving For You feed requests.
The cache logic was also updated accordingly. First, the keys used to reference feed instances in the Redis cache were updated to include the ID of the feed instance, with the following key template: $userId:HOMEPAGE:$feedId. This way, the rex service can check whether a given feed instance is available in the cache, and isn’t limited to retrieving the current feed instance. Second, whenever a new feed instance is generated, the key for the Redis entry for this feed instance is stored as the value for the Redis entry with the $userId:HOMEPAGE:current key. This provides an alias to the current feed instance, which the rex service uses when no feed instance ID is specified in the request.
With these changes, the logic for retrieving a For You feed page in the rex service became as follows:

With this new logic, when a feed instance ID is specified but the feed instance isn’t available in the cache (most probably because it has been evicted), a new feed instance is generated only if the request concerns the first page of the feed. Otherwise, an empty page is returned. This is the key change from the previous behavior; it ensures that clients always receive pages from the same feed instance which, in turn, ensures that any story appears at most once in the feed.
Note also that when no feed instance ID is specified in the request parameters, the rex service behaves in a way that is very similar to how it used to behave prior to the change: create a new feed instance and return it. This is needed for requests for the first page of the feed, which provide no cursor and thus no feed instance ID.
Update the TTL logic for cached For You feed instances
With the feed instance IDs changes described above in place, it was time to adjust the time-to-live values for cached feed instance IDs and for current feed instance aliases. We had two goals in mind:
- Use as long a TTL as possible for feed instance IDs, in order to allow users to go through their feed at their own pace.
- Set a short-ish TTL for aliases to current feed instances, in order to provide some freshness when a user reopens Medium after some time.
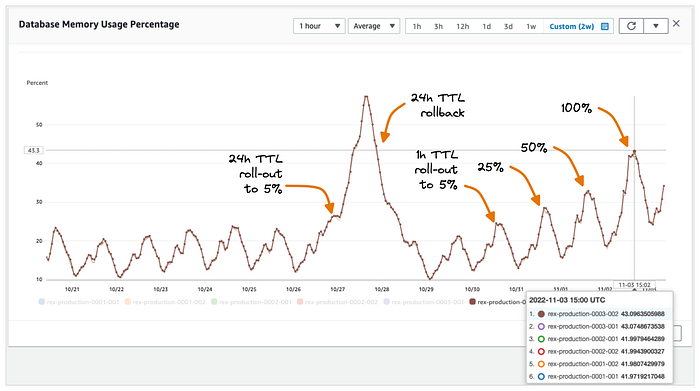
Our first attempt configured the TTL for feed instance IDs to 24 hours and the TTL for current feed instance aliases to 10 minutes. The For You feed is shown each time a logged-in user opens Medium (on web, iOS, and Android), which implies that a feed instance is cached in Redis for each active logged-in Medium user. Medium has quite a few active users, so we decided to tread carefully and activate the TTL changes for only 5% of the users. After about half a day, the memory usage for the Redis cluster looked like this:

Oops.
In just a few hours, memory usage of the Redis cluster doubled because of the 5% roll-out, with about half of the available memory being consumed! Obviously we would not be able to ramp up the TTL changes to 100% of our users without significantly increasing the amount of memory dedicated to the Redis cluster, which we deemed too costly compared to the benefits that would bring.
We decided to decrease the TTL for cached feed instances to 1 hour (instead of 24 hours). This seemed like an appropriate trade-off between availability of cached feed instances (doubling from the previous 30 minutes TTL) and memory usage of the Redis cluster. We first rolled out the change to 5% of our users, which resulted in a +4% increase in memory usage. The following days we ramped up the change to 25%, then 50%, and finally 100%. Max memory usage stabilized to about 45%, an acceptable +20% increase compared to memory usage prior to the changes. The graph below summarizes the roll-out phases and their impact on memory usage:
The outcome
Let’s recap:
- We fixed a concurrency issue in the rex service preventing some feed instances from being written to the cache. This issue resulted in multiple feed instances sometimes being returned for the same feed, and thus in some stories being listed multiple times within the same feed.
- We updated the cache logic in order to (a) allow multiple feed instances to be stored in the cache for the same user and (b) reference the last generated feed instance as the current one. With this new cache logic, the rex service is now able to ensure the same feed instance is used across page requests for one hour after the feed instance has been generated.
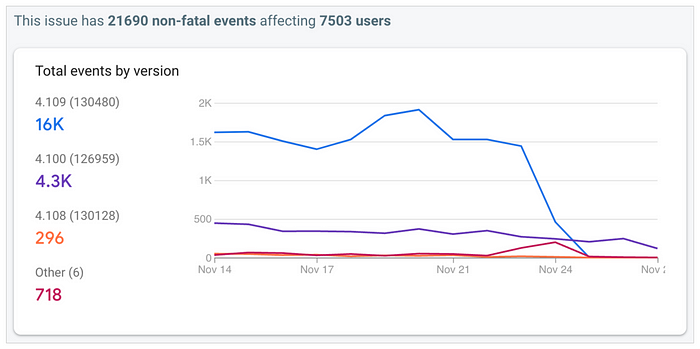
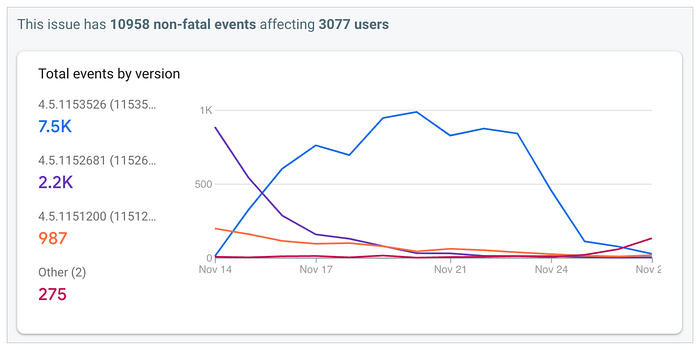
These changes have been deployed iteratively across a few weeks. The graphs below show the number of occurrences of duplicate stories per day on iOS and Android, grouped by app version, around the time of the last deployment:
iOS occurrences/day
Android occurrences/day
These graphs start at a time when some of the changes had already been deployed; these changes reduced the number of daily occurrences of duplicate stories from around 4K on iOS and 3K on Android to around 2K on iOS and 1K on Android. On November 24 the last change was deployed, in which the rex service returns an empty page instead of generating a new feed when a non-first page is requested on a feed instance ID that isn’t available anymore in the cache. After that the number of daily occurrences basically dropped to zero. And we haven’t received a report of a duplicate story in the For You feed since then.
Where to go next?
The changes made to fix the duplicate stories bug in the For You feed were successful and significantly improved the user experience. There is always room for improvement, though, and for further optimization to ensure that the For You feed continues to provide users with relevant and engaging content.
For instance, one limitation of the new caching logic is that if a user navigates back to the For You feed after the feed instance has been evicted from the cache, they will not get more stories past the ones they previously fetched (unless they refresh the whole feed). This could result in users missing out on potentially interesting content. One possible solution to this limitation is to implement a more robust caching strategy that would allow for more long-term storage of feed instances. However, this solution could come with a significant cost, as it would require scaling up memory for the Redis cache. As with any engineering problem, we would need to carefully consider the trade-offs before deciding on a solution.