Scaling PayPal’s AI Capabilities with PayPal Cosmos.AI Platform
By Jun Yang, Zhenyin Yang, and Srinivasan Manoharan, based on the AI/ML modernization journey taken by the PayPal Cosmos.AI Platform team in the past three years.

Source: Dall-E 3
AI is a transformative technology that PayPal has been investing in as a company for over a decade. Across the enterprise, we leverage AI/ML responsibly to address a wide range of use cases — from fraud detection; improving operational efficiencies; providing personalized service and offers to customers; meeting regulatory obligations, and many more things.
To accelerate PayPal’s innovation and deliver incredible value to our customers through technology, we are working to put the innovative power of artificial intelligence into the hands of more employees across different disciplines and accelerate time-to-market for building and deploying AI/ML powered applications, in service of our customers and in alignment with our Responsible AI principles. The blog below details a key internal platform that is helping us do this: PayPal Cosmos.AI Platform.
**AI/ML Platform: The Enterprise Approach
**Over the years, many engineering systems and tools have been developed to facilitate this practice at PayPal, addressing various needs and demands individually as they emerged. Several years ago, as we began to expand AI/ML across all core business domains, it became increasingly evident that the prevailing approach of having a collection of bespoke tools, often built and operated in their own silos, would not meet the needs for large scale AI/ML adoptions across the enterprise.
Conceived around 2020, PayPal Cosmos.AI Platform aims at providing end-to-end Machine Learning Development Lifecycle (MLDLC) needs across the enterprise by modernizing and scaling AI/ML development, deployment and operation, with streamlined end-to-end Machine Learning operations (MLOps) capabilities and experiences, making it faster, easier, and more cost effective to enable businesses through AI/ML solutions.
Since its official GA in mid-2022, Cosmos.AI has been gradually adopted by business domains across the company and became the de-facto AI/ML platform for the enterprise. Every day, thousands of data scientists, analysts, and developers hop to Cosmos.AI Workbench (Notebooks) and other research environments to develop machine learning and other data science solutions. In production, hundreds of deployed ML models serve tens of billions of inferencing requests, real-time and batch, on-premises and in the cloud on daily basis, supporting a wide range of business needs across the company.
In this blog, we provide a comprehensive view of the PayPal Cosmos.AI platform, starting retrospectively with the conscious decisions made at its conception, the rationales behind them, followed by an overview of its high-level architecture and a more detailed breakdown of its major components with their respective functionality through the lens of end-to-end MLOps. We then showcase how we have enabled Generative AI (Gen AI) application development on the platform, before concluding the blog with future works on the platform.
**The Guiding Principles
**When we first started conceiving what an enterprise-level AI/ML platform could be for the company, we took our time to establish a set of guiding principles based on our on-the-ground experiences gained from many years of practices of MLDLC. These principles remain steadfast to this day.
Responsible AI
PayPal remains committed to using AI technology in a responsible manner, consistent with legal and regulatory requirements and guidance and our overall risk management framework. Our approach to AI use is guided by our five core Responsible AI principles and our Responsible AI Steering Committee, consisting of cross-functional representatives who oversee AI development, deployment, governance, and monitoring.
PayPal Cosmos.AI reflects our commitment to Responsible AI in a number of ways, including minimizing inherited undesirable biases through data governance processes and training data management, enhancing interpretability through explainable AI, ensuring reproducibility with simulation, and having human-in-the-loop reviews whenever necessary.
Streamlined end-to-end MLDLC on one unified platform
The concept of a platform as a one-stop shop covering the entire MLDLC was pioneered by AWS SageMaker and later adopted by all major public cloud providers such as Azure Machine Learning and GCP Vertex AI. We believe this approach inherently provides the advantages of a consistent, coherent, and connected set of capabilities and user experiences compared to the ‘bespoke tools’ approach where tools are created independently, driven by ad hoc demands. The latter can lead to proliferation of overlapping or duplicative capabilities, resulting in frustrating confusing user experiences and high maintenance costs.
Cosmos.AI aims to provide streamlined user experiences supporting all phase of MLDLC, including data wrangling, feature engineering, training data management, model training, tuning and evaluation, model testing & CICD, model deployment & serving, explainability and drift detection, model integration with domain products, as well as other cross-cutting MLOps concerns such as system and analytical logging, monitoring & alerting, workflow automation, security and governance, workspace & resource management, all in one unified platform, catered for PayPal’s specific context and scenarios for MLDLC.
Best-of-breed with abstraction & extensibility
The AI/ML industry evolves extremely fast with new technologies emerging almost daily, and quantum leaps happen every now and then (just think about the debut of ChatGPT). How do we ensure the platform we build can stay current with the industry?
On Cosmos.AI, we decoupled platform capabilities from their actual embodiments. For example, distributed training as a capability can be implemented using an in-house built framework on Spark clusters on-premise, and as Vertex AI custom training jobs leveraging GCP. This best-of-breed approach with abstraction allows us to independently evolve components of our platform to leverage the most optimal technologies or solutions at each phase of MLDLC, be it in-house built, opensource adopted, or vendor provided. Abstractions have also been created among major components of the platform, for example, the Model Repo API ensures the compatibility of Model Repo with its upstream process (model development) and downstream process (model deployment), regardless of the underneath technology solution we choose for the component (e.g. MLFlow).
This approach lends itself well to greater extensibility of the platform. As shown in a later section, we were able to build a Gen AI horizontal platform on top of Cosmos.AI rather quickly, by extending capabilities in several phase of the MLDLC catered for Large Languages Models (LLM), including LLM fine-tuning, adapter hosting, LLM deployment, etc. and other LLMOps functionality.
In addition, this approach also mitigates potential vendor and/or technology lock-in, making the platform more future-proof given the constant changes of technology landscape and company policies.
Multi-tenancy from ground up
Multi-tenancy is essential to enterprise platforms such as Cosmos.AI. It creates the necessary boundaries among different scrum/working teams, so that they have the maximum autonomy over the projects or use cases they own, without being overloaded with information they don’t need, as we observed in the previous generation of tools. It also enables guardrails for fine-grained access control and permission management, so teams can work safely and at their own pace without stepping on each other’s toes, and maintain data protections.
Multi-tenancy is a prerequisite for self-service, another key principle embraced by the PayPal Cosmos.AI platform as discussed next.
Self-service with governance
We observed that when it comes to productionizing ML solutions developed by data scientists, dedicated engineering support is often needed to handle the operational aspects of the lifecycle. This poses a constraint for scaling AI/ML across the enterprise.
We firmly believe that the ability of self-service is key to the success of PayPal Cosmos.AI as an enterprise AI/ML platform, and we adhere to this principle throughout the platform from its foundational constructs, to user experiences, as we will discuss in later sections.
Seamless integration with enterprise ecosystems
At this point one might ask why we chose to build Cosmos.AI platform instead of adopting a vendor solution such as SageMaker or Vertex AI as is. For one, as we recognized through our evaluations, one-size-fits-all cookie cutter solutions did not, and most likely will not, meet all the functional requirements from a wide spectrum of use cases in a large enterprise — some of which are highly proprietary and advanced, and customizations can only go so far. In addition, requests for new features or enhancements to external vendors are highly unpredictable.
But the more fundamental challenges are the mandates for this platform to seamlessly integrate with the company’s ecosystems and policies, such as data security, data governance and other regulatory compliances for fintech companies like PayPal. From engineering perspectives, the platform needs to be an integral part of existing companywide ecosystems and infrastructures, such as centralized auth & auth and credential management, role-based permission management, data center operations, change process, central logging, monitoring and alerting, and so on.
Multi-cloud and hybrid-cloud support
PayPal encompasses a multitude of business domains and adjacencies, each of which may require the deployment of applications and systems in diverse environments. Recognizing this intricate landscape, Cosmos.AI is designed to be both multi-cloud and hybrid cloud, ensuring robust support across these varied environments.
There are many factors to consider when we productionize customer use cases on Cosmos.AI, including:
- Data affinity: customer solutions need to be deployed close to their data sources as much as possible to avoid data movements and security risks.
- Application affinity: customer application dependencies, downstream and upstream, on-Prem or cloud.
- SLA: fulfill requirements on latency, throughput, availability, disaster recovery (DR), etc.
- Cost: deploy workloads of different natures in the right environment for optimal cost-effectiveness. For example, research workloads requiring repetitive on-and-off, trial-and-error attempts may be more economically done on-Prem, while productionized workloads can leverage the scalability and elasticity provided by cloud more efficiently.
The coverage provided by Cosmos.AI over various environments allows us to productionize customer use cases with the right balance among these factors.
**The Foundations
**We developed various constructs and frameworks within PayPal Cosmos.AI that are fundamental to the platform. Leveraging these foundational elements, we successfully constructed the Cosmos.AI platform, aligning with the guiding principles set forth.
Project-based experience
A fundamental construct within the Cosmos.AI platform is the AI Project. It serves as the cornerstone for enabling multi-tenancy, access control, resource management, cost tracking, and streamlining the end-to-end MLDLC process.
From a user interface and user experience (UIUX) perspective, it empowers users to operate within their dedicated workspaces, with role-based access controls seamlessly integrated with PayPal’s IAM system. Beneath each AI Project, resources are managed in isolation, encompassing storage, compute, and data. Artifacts imported and produced during the MLDLC journey, such as training datasets, experiments, models, endpoints, deployments, monitoring, and more, are all contained within their respective AI Projects. This design fosters genuine multi-tenancy and facilitates self-service. Project owners and members can independently work within their projects, including deployment, without concern for interfering with others (subject to predefined platform-level governance within Cosmos.AI). This approach enhances the scalability of ML solution development while reducing time to market.
Dynamic resource allocation and management
We built a framework capable of dynamically allocating and managing computing resources on Cosmos.AI for model deployment and serving. At its core is a sophisticated Kubernetes CRD (Custom Resources Definition) and Operator that creates model deployments, including advanced deployments as discusses later, as well as manages the orchestration, scaling, networking, tracing and logging, of pods and model services. This is a pivotal capability on Cosmos.AI platform, enabling self-service MLOps to productionize ML solutions with ease. Coupled with multi-tenancy and governance, this allows domain teams to develop, experiment, and go production with their ML solutions at their own pace, all within their allocated resource quota and proper governance policies set forth by the platform. This paradigm offers MLDLC at scale and greatly shortens their time-to-market (TTM).
Workflow automation with pipelines
Workflow automation is another framework foundational to the Cosmos.AI platform. It consists of several parts: an experience for users to compose pipelines using building blocks provided by the platform, such as data access, processing and movement, training, inferencing, or any custom logic loaded from container Artifactory. Resulted pipelines can be scheduled, or triggered by another system — for example, a detection of model drift by monitoring system can automatically trigger model refresh pipeline — training data generation, model training, evaluation, and deployment.
User experiences through UI, API & SDK
Cosmos.AI created user experiences for customers across the entire spectrum of ML expertise, exposed mainly through two channels: the Cosmos.AI Hub, a web-based application with intuitive, interactive and coherent UI guides users of different levels going through all phases of MLDLC, leveraging advanced techniques such as drag-and-drop visual composers for pipelines and inferencing graphs, for example. For advanced uses preferring programatical access to the platform, they can choose to work on Cosmos.AI Workbench, a custom user experience built on top of Jupyter Notebook with accesses to platform capabilities through Cosmos.AI API & SDK, in addition to the UI. Cosmos.AI Hub and Workbench play critical roles in delivering the user experiences enabling streamlined, end-to-end MLDLC with self-service.
**The Architecture
**The diagram below provides a high-level layered view of PayPal Cosmos.AI platform architecture.

**The MLOps Focus
**PayPal Cosmos.AI has been built with a strong focus on MLOps, particularly on the model development, deployment, serving and integration with business flows. In this section, we delve into the next level details on key components in Cosmos.AI that makes it stand out from a MLOps perspective.
Model development: training dataset management, training & tuning
For any model development lifecycle, dataset management is a critical part of the lifecycle. PayPal Cosmos.AI supports preparation of training datasets integration with feature store and manage these datasets along with sanity checks and key metrics while seamlessly integrating with training frameworks and experiment tracking. Along with training datasets, it also helps manage and keep a system of record for other datasets crucial for advanced features like explainer, evaluation, drift detection and batch inferencing cases.
Cosmos.AI provides a very rich set of open source and proprietary model training frameworks like TensorFlow, PyTorch , Hugging Face, DGL, and so on, supporting many deep learning algorithms and graph training algorithms. It also provides a very easy way to run these massive training jobs locally or in distributed manner with use cases datasets in the scale of 200 million samples with 1,500 features in various modes like map reduce, Spark and Kubernetes, abstracting the underlying infrastructure and complexity from the data scientists and helping them to effortlessly switch with mere configuration changes. It also provides various templates of commonly used advanced deep learning modules like Logistic regression, DNN, Wide & Deep, Deep FM, DCN, PNN, NFM, AFM, xDeepFM, networks & training algorithms supporting a variety fraud, personalization, recommendations and NLP use cases. Cosmos.AI also provides seamless integration into cloud provider offerings for model training with ease and high security standards.
Model repo: experiment & model registry
Cosmos.AI provides an advanced and comprehensive framework for capturing all aspects of the model training process, emphasizing reproducibility, traceability, and the meticulous linking of training and evaluation datasets to the model. This encompasses the inclusion of training code, hyperparameters, and configuration details, along with the thorough recording of all model performance metrics. The platform facilitates seamless collaboration among data scientists by allowing them to share their experiments with team members, enabling others to reproduce identical experiments.
In addition to robust experiment tracking, the model repository stands as a pivotal component within the platform. It houses the physical artifacts of the model and incorporates essential metadata required for inferencing. Crucially, every model is intricately linked to its corresponding experiment, ensuring a comprehensive lineage for all critical entities throughout the entire machine learning lifecycle.
Model Deployment
Cosmos.AI supports several model deployments approaches catered for PayPal’s hybrid cloud environments. However, our discussion is confined to the predominant Kubernetes-based approach, with the expectation that other methods will gradually phase out and converge towards this mainstream approach in the near future.
At the core of the model deployment component is a custom-built Deployment CRD (Custom Resource Definition) and Deployment Operator on Kubernetes. They work together to allocate resources like CPU, GPU, memory, storage, ingress etc. from underlying infrastructure and create a DAG (Directed Acyclic Graph) based deployment with orchestrations among models, pre/post processors, logger & tracer, or any containerized custom logics (e.g. Gen AI components as discussed in a later section) based on the deployment specification generated by Cosmos.AI from user inputs through the deployment workflow.
This is an extremely powerful capability on Cosmos.AI platform, enabling simple and advanced model deployment schemes such as Inferencing Graph, Canary, Shadow, A/B testing, MAB testing, and so on. It is a key enabler for self-service, as technically a user can just pick one or more registered models from the model repo, specify a few parameters, and have a model endpoint running ready to service inferencing requests in a few clicks — all through a guided, UI based flow by herself.
However, in reality, it is necessary to build governance and security measures into the process. For example, we integrated with company-wide change process so that every action is trackable, and with operation command center to observe site wide events such as moratorium.
Model inferencing
Model inferencing capabilities on Cosmos.AI fall into two categories: batch and real-time.
Cosmos.AI offers batch inferencing on two infrastructure flavors: Spark native and Kubernetes, available both on-premises and cloud environments. These solutions are highly scalable and cost efficient, making them extensively utilized in use cases like offline model score generation, feature engineering, model simulation and evaluation, and so on. Typically, these processes are integrated as steps within workflows managed by workflow management services such as the Cosmos.AI pipeline.
Real-time inferencing on Cosmos.AI is implemented through various technology stacks, supporting all combinations of model aspects in the company: Java and Python runtime; PayPal proprietary and industry standard; conventional ML, Deep Learning, and LLM. On our mainstream Kubernetes based platform, we support complex DAG based model inferencing, GPU optimization such as GPU fragmentation, and multi-GPU for LLM serving, adaptive / predictive batching and other advanced model serving techniques.
Model integration: rule lifecycle, domain product integration
Rarely are model scores used in isolation to make decisions and drive business flows at PayPal. Instead, a Strategy Layer, typically comprised of rules — often numbering in the hundreds for a specific flow — is positioned on top. This layer synthesizes other ingredients at runtime, incorporating additional context or factors, with business rules applied as deemed necessary by the domain.
Cosmos.AI built a complete Decision Platform to support this need. At the core of its runtime is an in-house built lightweight Rule Engine capable of executing rules based on a Domain Specific Language (DSL), with end-to-end dependencies expressed as a DAG. User Defined Functions (UDF) as platform provided, built-once-use-many capabilities can be invoked anywhere in the execution flow. In design time, an interactive UI with drag-n-drop is used for developers to author rules with self-service and minimum coding. In addition, integrations with upstream domain products are facilitated by a UI based use case onboarding and API schema specification workflow. The entire rule lifecycle and use case management including authoring, testing, regression, deployment and monitoring are supported through the platform.
Explainability and drift detection
Explainability is supported on Cosmos.AI mainly through black-box models. Depending on the types, frameworks and input data formats of the models, a variety of algorithms, e.g., Tree SHAP, Integrated Gradients, Kernel SHAP, Anchors etc. are utilized to provide instance-specific explanations for predictions. We also built explainability into our end-to-end user experience where users can train explainers or surrogate models as well as main models, before deploying them together through a single deployment workflow.
Model drift detection is also supported on Cosmos.AI through monitoring and alerting of model metrics such as Population Stability Index (PSI) and KL Divergence. Integrated with automated model re-training pipeline on the platform, drift detection is used as an alerting and triggering mechanism to guard against model concept drifts in production.
**Gen AI Enablement
**Since Generative AI (Gen AI) has taken the world by storm with the groundbreaking debut of ChatGPT in late 2022, we embraced this transformative technology early on, by exploring, evaluating and onboarding various Gen AI technologies, particularly those centered around Large Language Models (LLM), anticipating a fresh wave of widespread Gen AI adoptions potentially reshaping every facet of customer experiences and applications throughout the company and the industry.
Thanks to the solid foundations we have in place for platform with its remarkable extensibility, we were able to develop a Gen AI horizontal platform on PayPal Cosmos.AI in the span of a few months, allowing PayPal to fully tap into this technology and rapidly scale Gen AI application development across the company, while reducing costs by minimizing duplicated efforts on Gen AI adoptions among different teams.
Below is an overview of the Gen AI capabilities we built on Cosmos.AI platform:
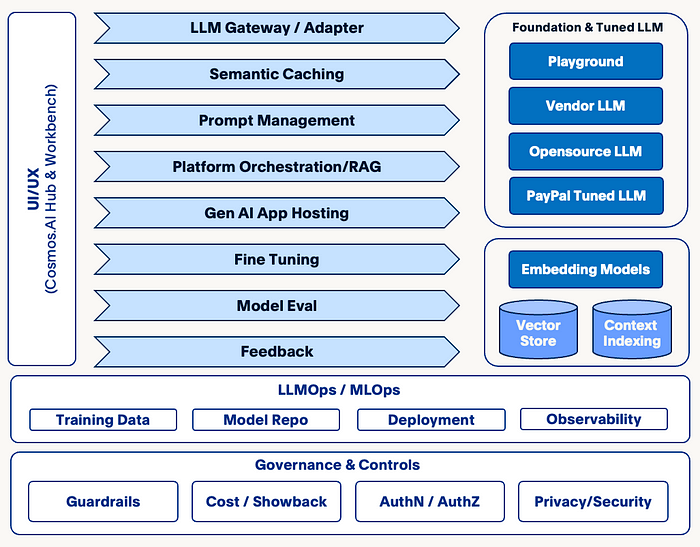
We augmented our training platforms allowing users to fine-tune opensource LLMs through custom Notebook kernels with PEFT frameworks such as LoRA/QLoRA integrated, and enabled fine-tuning of vendor hosted LLMs through API with security measures such as Data Loss Prevention (DLP) in place. We extend our model repo to effortlessly onboard opensource LLMs from public model gardens such as Hugging Face, with legal and licensing checks in the process. We also extend the model repo to host LLM Adapters as outputs from fine-tuning processes, deployable with their coupling foundation models.
The needs for LLMOps are accommodated nicely by extending existing MLOps capabilities on Cosmos.AI, including the ability to deploy LLMs with high parameter sizes across multiple GPU cards; LLM optimizations (including quantization) leveraging cutting edge frameworks and solutions for better resource utilization and higher throughput; streaming inferencing optimized for multi-step, chatbot-like applications; logging/monitoring to include more context such as prompts which are specific to LLM serving. Cost and showback for budgeting purposes are supported out-of-the-box through AI Projects on Cosmos.AI. Of course, we also developed a suite of new capabilities and infrastructure components to enable Gen AI as a transformative technology on our platform, including:
- Adopted a purposely built Vector DB from a leading opensource solution as the foundation for embedding and semantic based computations.
- A Retrieval-Augmented Generation (RAG) framework leveraging Vector DB (for indexing & retrieval) and Cosmos.AI pipelines (for context and knowledge ingestions), enabling a whole category of chatbot and knowledge bot use cases across the enterprise.
- Semantic Caching for LLM inferencing, also built on top of Vector DB, to cut down operational costs for vendor and self-hosted LLM endpoints and reduce inferencing latency at the same time.
- A Prompt Management framework to facilitate prompt engineering needs of our users, including template management, hinting, and evaluation.
- Platform Orchestration framework: the advent of Gen AI introduced a distinct need for complex orchestrations among components and workflows. For example, to enable in-context learning and minimize hallucination, a LLM inferencing flow may involve prompt management, embedding generation, context/knowledge retrieval, similarity-based search, semantic caching, and so on. The industry has come up with some popular frameworks such as LangChain, LlamaIndex aiming at streamlining such workflows, and Cosmos.AI has built an orchestration framework with in-house developed capabilities and opensource packages as a platform capability.
- LLM Evaluation supporting major industry benchmarking tools and metrics, as well as enabling custom PayPal internal datasets for domain / use case specific evaluations.
- Gen AI Application Hosting to bootstrap client applications on Cosmos.AI platform.
Utilizing the Gen AI horizontal platform as a foundation, we have enabled an ecosystem of internal agents for cosmos specializing in code, internal knowledge, model document creation and other MLDLC tasks using multi-agent and orchestration framework. This enables us to enhance productivity and efficiency for our data scientists and ML engineers by offering a Gen AI-powered experience on the Cosmos platform.
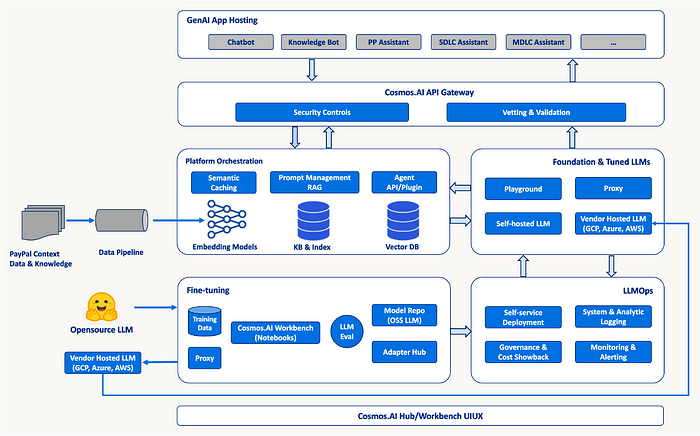
An architecture overview of Gen AI horizontal platform on Cosmos.AI is shown below:
**Future Work
**As we advance further on the journey of modernizing AI/ML at PayPal that commenced three years ago, we are currently envisioning the future landscape three years from today. Here are some initial considerations.
- Evolve from an AI/ML platform into an expansive ecosystem tailored for enterprise use, including datasets, features, models, rules, agents and APIs as core competencies.
- Transition from self-service/manual processes to autonomous workflows in SDLC/MDLC/Front Office/Back Office Operations, incorporating automation and leveraging multi-agent framework driven by Generative AI.
- Delve further into the realm of AI and incorporate elements such as data provenance, lineage, explainability, feedback loop, RLHF, and more, moving beyond the confines of AI/ML to AGI.