Handling Flaky Tests at Scale: Auto Detection & Suppression
At Slack, the goal of the Mobile Developer Experience Team (DevXp) is to empower developers to ship code with confidence while enjoying a pleasant and productive engineering experience. We use metrics and surveys to measure productivity and developer experience, such as developer sentiment, CI stability, time to merge (TTM), and test failure rate.
The DevXp team has continuously invested in test infrastructure and CI improvements, but one of the biggest impediments to our progress is the high — and ever increasing — rate of test failures due to flaky tests. Before we automatically handled flaky tests, the main branch stability was hovering around a 20% pass rate. When looking closely into the 80% of failing builds we found:
- 57% failed due to test job failures consisting of flaky and failing automated tests
- 13% failed due to developer errors, CI issues, or test infra issues
- 10% failed due to merge conflicts
After replacing the manual approach of handling test failures with an automated flaky test suppression system, we were able to drop test job failures from 57% to less than 5%.
This post describes the path we have taken to minimize the number of flaky tests through an approach of automated test failure detection and suppression. This is not a new problem that we are trying to solve; many companies have published articles on systems created for handling flaky tests. This article outlines how test flakiness is an increasing problem at scale and how we got it under control at Slack.
**At a larger scale… **
For the mobile codebases, we have 120+ developers creating 550+ pull requests (PRs) per week. There are 16,000+ automated tests on Android and 11,000+ automated tests on iOS with the testing pyramid consisting of E2E, Functional, and Unit tests. All tests run on each commit to a GitHub PR and on every PR merged to the main branch. Moreover, developers are responsible for writing and maintaining all the automated tests associated with their product group.
As we continued to scale we asked: Can we ensure that the experience of landing a change to the main branch is a reliable and performant one? We started by investing heavily in reliable tests. However, at a larger scale it’s impossible to keep flakiness from entering the system by relying on test authors to do the correct thing. In earlier days, we relied on the collective consciousness, i.e. developers realizing that a test is flaky and proactively investigating it. This worked on a small team (~10 devs), but at a larger scale there’s a bystander effect. Ultimately, developers want to merge the PR they are working on and not investigate an unrelated flaky test. Based on the survey of developers and DevXp triage members, each test failure takes about 28 minutes to manually triage. The unavoidable existence of flakiness in our system, high test job failures, and triage time warranted efforts into automation of flaky test handling.
Zooming in on flaky tests first
Let’s start with an analogy — fatal vs non-fatal errors in software. No software is without both fatal and non-fatal errors. Fatal errors affect the basic usage and create a frustrating user experience. Non-fatal errors also affect usage and reduce user experience but at a lesser scale. Developers might not take immediate action on non-fatal errors but it’s still a good idea to monitor them.
Similarly, flaky tests are an unavoidable reality for test sets at a large enough scale. Flaky tests compromise a fragile balance of workflow and quality. Bugs can hide under the disguise of a flaky test; a test loses its purpose if the developer just ignores the failure due to its flaky nature. Flaky tests also take up valuable resources when running them and increase execution cost ?— especially when CI relies on 3rd-party services such as AWS or Firebase Test Lab (FTL). Ultimately they reduce CI stability, increase TTM, reduce developer trust, and impact developer experience.
We categorized our flaky tests into two types:
-
Independent flaky tests: Tests which fail independently of running them in a single invocation or as part of the test set. These are somewhat easier to identify, debug, and resolve as running them in isolation can reproduce the failure.
-
Flaky tests due to systemic issues: These tests fail when run as part of the test set due to shared state or CI environment differences. As the test set or CI environment changes, the test behavior changes as well. This type of flaky test is more elusive in both detection and debugging.
Here is an example of developer sentiment toward flaky tests from our initial survey:
“As for CI, I have to thank the DevXp team for having so many types of tests that run. While I wish it would take less than 50% of its duration today, I think I would want to have less flakiness from the E2E and FTL instrumentation tests. Almost all my CI errors which require a device are a result of flaky tests.”
Our initial implementation was heavily motivated by getting a handle on tests that were flaky due to systemic issues. Now let’s zoom out and discuss our approach.
Manual triaging of flaky tests
Before we embarked on this journey, a developer would have to follow this manual process when a test job failed on a developer’s PR or the main branch.
A developer gets a notification that a required check is marked ❌ due to a failing job:
- Investigation begins and the developer finds the job failed ❌ due to a failing automated test
- The developer comes to the conclusion that the failing test is not relevant to code changes in the PR
- They attempt to retry the failing test job in hopes that the second attempt will yield a ✅ passing result and the flaky tests will have magically passed (often they continue this retry step more than once ? )
After unsuccessful rerun(s) attempts, a developer will reach out to the DevXp help channel. Individuals on a triage shift will further debug the failing test job:
- They check if other PRs or the main branch test jobs are failing due to the same test failure
- They find out how many reruns the developer already did and if at any point the test started passing
- They check the test history and see if it was recently modified
- They check if the test has the tendency to be a flaky test
- They try to identify the team who owns the test
- They suppress the test so the developer can move forward with their development flow and unblock their PR’s mergeability
- They create a Jira ticket with all the investigation details and assign the ticket to the responsible team
Our data showed that manually triaging and suppressing flaky tests led to better stability and reduced test jobs failure. So we decided to automate the process.
Let’s take a walk through our automation journey
Success wasn’t achieved overnight or in one go. We had to stumble through multiple trials before finding our ground. Let’s see how we started, where we struggled, and how we pivoted.
We kicked off “Project Cornflake” with the goal of automated detection and suppression of flaky tests.
First let’s get clarity between a flaky test and a failing test
- A failing test is a test that fails consistently across multiple reruns
- A flaky test is a test that eventually passes across reruns if the test reruns multiple times
First approach**:** Suppress results of flaky tests after a certain set threshold
We wanted to create a system that would detect flaky tests and calculate flakiness percentage based on the test history. If a test crosses the tolerable threshold then it will be removed from the results so that it’s suppressed from surfacing the test failure and thus failing the test jobs.
Test failure rate can vary based on different test types. For example, unit tests are less flaky than functional tests, which are less flaky compared to E2E tests. With that in mind, we decided to create a solution based on the test type and certain amount of failure tolerance for each test type.
Implementation
This was our high-level vision on CI for each test job failure:
- Parse the test results to identify failed test cases
- For each failed test case, pull the test case history from the backend against the main branch for the last N test runs (for example N = 50)
- Calculate the flakiness of each failed test: Failed Test Runs / N test runs
- If a test doesn’t have any history or enough history then it will automatically be considered a flaky test (i.e. we assume a test is flaky until it proves to us that it is stable)
- Remove flaky tests from test results that cross a specific flaky threshold
- Update the backend to indicate the test is flaky by setting is_flaky = true
- CI ingests modified xml test results file and the test job is marked green**

**
Impact
We observed an instant stability boost on both PR and the main branch test jobs since the project rollout. PR build stability went from 71% at the time of rollout to 88% the following week. The main branch build stability improved from 61% to 90% the following week.


Drawbacks of this approach
While this approach worked well during the initial rollout, we started seeing more and more drawbacks, which made job failure investigation more difficult. The biggest drawback that made us roll back our implementation was: Failing tests were leaking into the main branch.
Drawback # 1: Flaky test turned into a failing test and leaked into the main branch.
Let’s walk through the following scenario:
- Developer A writes a brand new valid test and merges into the main branch.
- However, since the test doesn’t have enough history built in the backend, we will classify it as a flaky test and remove it from the test results, marking the job successful.
At this point, on the main branch the test is actually broken but it keeps running and being filtered out on CI from test results due to a lack of sufficient test history. At the same time the test fails locally which causes confusion for developers. Test jobs will start failing on CI once enough test history builds up and the tolerance threshold is exceeded. Now, a developer or a triage member will have to investigate the point of origin from when the test started failing, defeating the purpose of this project.
Drawback #2: Adding flaky test back to test pool.
Let’s walk through the following scenario:
- Developer A opens a PR to fix a flaky test. The fix doesn’t work and the test fails.
- In this case, the CI job should have failed without removing the test from the results.
- However, the system will look at the test history, find enough history to calculate flakiness % and remove the test from the results classifying it as a flaky test and passing the job.
- The developer looks at the job status and sees ✅ believing the test was fixed and closes the Jira ticket but in fact the test is still flaky.
Drawback #3: Dependence on backend.
- Local development: The source of truth about the test history lives on the backend, meaning the local developer experience diverges when running tests. Syncing the system to a local developer environment is a non-trivial amount of work.
- If the backend goes down, CI test jobs come to a screeching halt. Test jobs will fail with “Unable to perform flaky test calculation.” This results in developers not being able to merge their PRs, or the main job unable to update the backend.
Key learnings from the first approach
- Simply filtering out flaky test results is not the best approach as we are just hiding test failures from impacting the overall main build stability. This approach makes flaky test investigation difficult since there is not enough information on when the test state changed.
- Instead of handling test failure detection and suppression at both the PR and the main branch level, it is better to suppress tests only on the main branch. That way developers can simply pull the latest main branch to prevent flaky test failures on their PR.
With that, we decided to go with suppressing execution of flaky tests instead of suppressing results of flaky tests. A single failure will result in the test being disabled (regardless of reruns) and each feature team will need to assign resources to investigate the true nature of test failure to fix it accordingly.
Second approach: Suppress execution of flaky tests
We divided the handling of test failures into 3 key parts:
- Test Detection: Identify the test failure and differentiate between flaky tests and failing tests
- Test Suppression: Create a Jira ticket, open a PR to suppress the test, auto-approve the PR, and then merge the PR
- Slack Notifications: Notify the DevXp team when a PR is created and merged
Success Metric
- Increase the main branch jobs passing to 95% and reduce test job failure rate to below 5%
Requirements
- All test runs on the main branch must pass because they went through PR checks
- Support for all test types: E2E, Functional, and Unit tests
- Flexibility to auto-detect and suppress failing and flaky tests separately
- Should not suppress backend/API failures, test crashes, or infra failures
- Support test suppression for both mobile platforms: iOS and Android
- Create test ownership mapping to map tests to respective feature teams
- Assign a Jira ticket to the team that owns the test
- Attach test result failure details to the Jira ticket for ease of investigation
- Exclude specific tests in case a team opts out of disabling them
- Flexibility to auto or manual merge a PR resulting from test suppression
- Send weekly alerts to each team’s channel to communicate a summary of suppressed tests

Implementation
****Detection:
"""
Get list of flaky or failing tests, excluding backend/API failures, test crash, and infra failures as they are unrelated to test logic
"""
def get_test_failures_from_raw_results(): test_failures = [] result_files = get_list_of_test_result_files_from_ci() for result_file in result_files: for test in result_file: if (test.status == "failure" or test.status == "flakyFailure") and not test.is_infra_incident and not test.is_crash and not test.is_api_failure: test_failures.append(test) return test_failures
****Disable test, create Jira and PR:
"""
- Create a Jira ticket if one doesn't exist
- Create and checkout branch
- Disable test
- Commit and push changes
- Open PR with description, auto approve it, and add it to MergeQueue
"""
def disable_test_with_jira_and_pr_creation(test_failures): for test_name in test_failures: owner_team, jira_project_id = get_team_owner_and_jira_project() jira_ticket = find_or_create_jira_ticket(jira_project_id) branch_name = create_and_checkout_git_branch() disable_test(test_name, jira_ticket) commit_and_push_changes(branch_name) pr = open_pr_and_assign_reviewer(jira_ticket, branch_name) approve_pr_and_merge(pr)
****Disable test based on platform:
"""
Modify the test file to disable test based on platform: iOS or Android
"""
def disable_test(test_name, jira_ticket): test_file_path = get_file_path_for_test(test_name) with in_place.InPlace(test_file_path) as test_file: for line_num, line in enumerate(test_file, 1): test_found = re.search(test_name + "`?\(", line, re.MULTILINE) if test_found: if self.platform == "ios": disable_ios_test() elif self.platform == "android": disable_android_test() test_file.write(line) """
This function disables a test by renaming it and adds a Jira ticket to the comment
Example input: func testShouldShowInvite() {
Example output: // https://jira.com/PROJ-123 func disabled_testShouldShowInvite() {
"""
def disable_ios_test(jira_ticket): ... """
This function disables a test by renaming it and adds a Jira ticket to the comment
Example input: fun testShouldShowInvite() {
Example output: @Ignore('https://jira.com/PROJ-123') fun testShouldShowInvite() {
"""
def disable_android_test(jira_ticket): ...
Notification:
Impact
After our implementation, let’s see how we did on success metrics.
Improved the main branch stability to 96%: From 19.82% on July 27, 2020 to 96% on Feb 22, 2021. Areas negatively affecting stability were 3rd-party services and merge conflicts.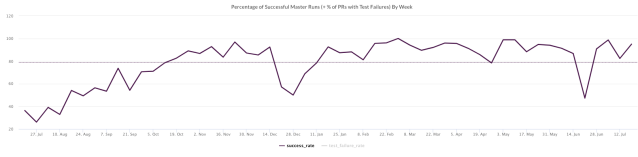
Reduced test job failure to 3.85%: From 56.76% on July 27, 2020 to 3.85% on Feb 22, 2021. Areas affected negatively were 3rd-party services, infra downtime, and CI.
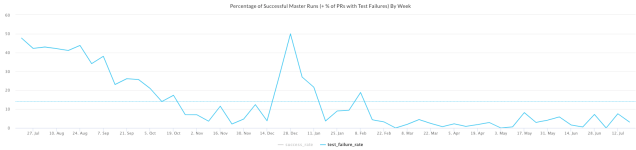
Saved 553 hrs of triage time: Manual triaging of flaky tests takes ~ 28 mins/PR. With automation, we have created 693 PRs for Android and 492 PRs for iOS resulting in a total saving of 553 hrs (or 23 days of developer time) so far.
Improved developer sentiment: Here is a quote from a developer:
“I feel iOS CI is much more stable and fast than before. Thank you for all the hard work! It improves our productivity by far. Really appreciated!”
Improved developer confidence: We reached out to our developers to get feedback and it’s clear from survey results that confidence has increased in a positive direction.
-
74% say that #proj-cornflake has a positive impact on main branch stability
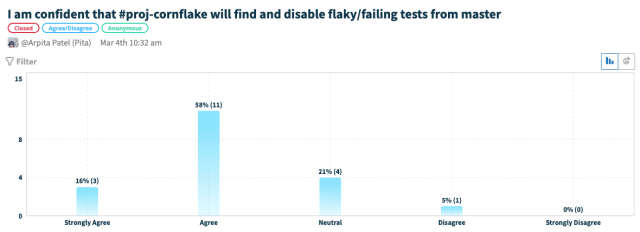
-
64% say that #proj-cornflake has reduced reruns on PR
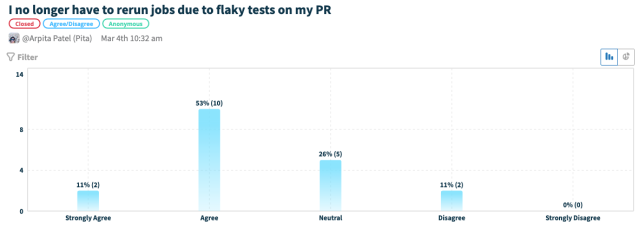
? It’s been almost a year since V2 rollout, and the auto-detection and suppression system is still going strong with little to no maintenance cost ?
Is there more to the story?
Of course. During our developer user experience interview, we asked the following question: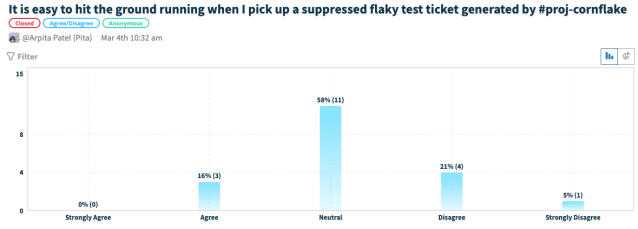
Summary: 26% say that it was not easy to hit the ground running and 58% were neutral on the experience.
After a few months of rolling out the project, many tests have been suppressed, and developers are having a bit of a hard time re-enabling tests since a test failure can be out of date, difficult to reproduce, or the feature has evolved.
In the next phase of the project, we made our system even smarter and added support to automatically enable tests while trying to satisfy the following criteria from developer feedback:
- Send test suppression notifications in real time to respective feature teams
- Rerun suppressed tests regularly in quarantine to ensure that it doesn’t affect the main branch builds. If they are no longer flaky then they can automatically be re-enabled and merged to the main branch
- Make the process of fixing suppressed tests as easy and fast as possible
Closing note
Flaky tests have always been in the codebase and will always be there. Our goal is to identify them as fast and as comprehensively as possible. Since they do exist, we should learn how to deal with them without affecting developer productivity, experience, and confidence in our team’s goals.
Stay tuned for part two: “Handling flaky tests at scale: auto re-enabling tests.”
If you find this interesting and like solving similar problems, come join us! https://slack.com/careers