Cross-Selling Optimization Using Deep Learning

Photo by https://unsplash.com/@cytonn_photography
PayPal’s Data Science team leverages big data to empower business decisions and deliver data-driven solutions to better serve our customer’s financial needs and drive business growth. In this article, we introduce a deep learning based framework that can be used to optimize actions for domain-specific objectives.
Introduction
Many impactful business problems need to be translated into corresponding machine learning tasks. For example, we must be able to recognize fraudulent credit card transactions to prevent loss for both our merchants and consumers. Credit card fraud detection is often translated to a classification task in machine learning.
Recommending the right financial products to the right customers is another important problem. One way to tackle product recommendation is by computing a propensity score (i.e. the likelihood of adopting a product for a user). Effective product recommendations and promotional strategies are often built based on product propensity scores. Propensity modeling, which determines the best product-customer pairs, is often translated into a classification task.
Classification
The goal of classification is to categorize data points into one of few buckets. For a binary classification problem, there are two buckets, often denoted by 0 or 1 (negative or positive). A trained model, or a classifier, generates a predicted score representing the likelihood of being a 1 (positive case). For example, in credit card fraud detection, each transaction will be categorized into 1 (fraudulent) or 0 (non-fraudulent). A classifier will generate a score for each transaction, and a score closer to 1 suggests higher risk for a transaction being fraudulent.
The model training phase is often guided by a specific loss function called binary cross-entropy so that an optimized classifier will give the minimum error defined as
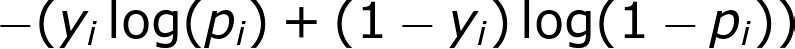
binary cross-entropy
where ? is the observation or label, either 0 or 1, ? is the model prediction. Intuitively, this error is minimized when the classifier generates a score closer to 1 if the ground truth is 1, and a score closer to 0 if the ground truth is 0.
One observation, by looking at the loss function, is that the classifier will do the same job in separating two cases, even if we swap the positive and negative cases. Nonetheless, classic classification models are often not well suited for all business problems. This is because the loss function for classic ML models is general-purpose instead of domain-specific.
Action Optimization
In many domain-specific problems, business stakeholders or model users will need to make actionable strategies to maximize different objectives (e.g. business metrics or KPIs). This motivates us to construct custom loss functions to address different domain-specific needs.
Take the product propensity model that is used for recommending PayPal’s financial products to merchant customers as an example. Due to resource constraints, only up to a certain portion of merchant customers can be contacted for product recommendations. Sales reps would rely on the results generated by the trained propensity model by looking at customers with the highest propensity scores to optimize objectives, like sales, with limited reach-outs.
The classic classification model can unquestionably get the job done — a well-trained classifier under default binary cross-entropy loss is optimized to separate customers with high propensity from those with low propensity. One obvious limitation of this approach is that the classifier under default loss function is unable to take into account the potential size of the deal which is an important consideration for sales. By incorporating a customized loss function that is more aligned with the business goal, we can have an even better business solution. One such customized loss function is:
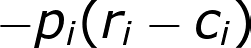
where, ? represents the sales, ? is the cost associated with product reach-out. ? is the output layer of a neural network, and it is a number between 0 and 1, where numbers closer to 1 suggest higher priority to reach out.
An example of deep neural network
Here’s one way to interpret this objective function — from a sales reps’ perspective, when deciding on whether to reach out (higher ?) or not to a given merchant for a certain product recommendation. If sales reps decides to reach out, there will be an associated cost (?) as well as potential sales (?). If sales reps decide not to pursue the deal, at least for now, then there will be no associated cost or any sales. However, even if they decide to reach out, the result could be either winning the deal or losing it (? = 0). Therefore, the customized function above reflects somewhat the expected payoff of reaching out to a merchant.
Unlike the default binary cross-entropy loss, this customized loss function naturally penalizes false negative with weight being proportional to the size of a deal — so that the classifier will learn to avoid a false negative (missing a potential deal), especially for those with potentially high sales. At the same time, it penalizes false positive with weight being proportional to the associated cost.
To study how incorporating this customized loss function will impact the business, we compared a feedforward deep learning model with this customized loss function with another feedforward deep learning model with default binary cross-entropy trained on the same underlying training data. We chose a deep learning model here because of the fact that it is very easy to train them with custom loss functions, unlike other model families where the loss function is intricately tied to the model training process. The two models were evaluated on the same test set — we saw an approximate 15% decrease in catch-rate (i.e. conversion rate), but an approximate 40% increase in sales metric defined by business stakeholders. This is due to the fact that two models are trained to optimize different objectives: model with default binary cross-entropy is trained to minimize the prediction error, hence shows a better performance in terms of catch-rate; while the model with customized loss function is trained to maximize sales (actual objective for stakeholders), hence gives a better performance under this metric.
Conclusion
In this article, we introduced a deep learning approach that can be used to optimize actions for domain-specific problems. We illustrated our approach using the product propensity modeling as an example and covered why models trained under customized loss function were better than the ones trained under the general-purpose binary cross-entropy loss. This approach can also be applied to credit card fraud detection problems when deciding on whether to decline a transaction due to fraud or not. In this case, an ideal customized loss function should penalize false positives at certain weight because legitimate transactions getting declined results in a bad user experience.
Broadly speaking, accurate prediction results are very important in business decision-making; however, there’s always a gap between predictions and actionable strategy, and this is why it is important to formulate the underlying AI / ML problem carefully while keeping the end business metrics in mind as much as possible.
Please subscribe to our blog if you are interested in hearing more.