Applying the Micro Batching Pattern to Data Transfer
If you have worked on data-rich software systems, chances are you have worked with a distributed architecture where one part of your system needs access to data owned by another part of the system. Whether that architecture is a modern distributed microservices architecture or a set of stand-alone applications looking to exchange data, you will have one party owning that data (let’s call it the producer) and another party needing that data (let’s call it the consumer).
How should your consumers obtain the data of your producers, while striking the right balance between latency and consistency?
One option, of course, would be to run real-time queries against the source system for maximum consistency. Blocking patterns like this mostly work well for small datasets but incur latency for larger result sets, especially when your data comes in the wrong representation or requires transformation.
Another option is to proactively stream data from your producers into a central hub (or data lake) for consumers to consume from. Here the challenges are in synchronization of read/write rates between producers and consumers, delivery guarantees by the data hub, and the sheer volume of data.
While an event streaming system like Kafka is certainly the ideal option for real-time integration, it introduces complexities and comes at a cost that the business has to absorb. Not all use cases require the low latency event driven integration and don’t stand to gain anything from the additional investment. An eventually consistent replica is sufficient for many use cases in CRM or ecommerce, especially for back office facing domains like catalog management, inventory management, or order processing.
What I want to discuss in my blog today is a lower cost option that applies the same idea of pub/sub based eventing systems, but on datasets. The dataset can itself be the result of a query or an aggregated event stream. We control the size of the dataset either by size (i.e. number of records or bytes) or by time elapsed between data sets.
If the dataset is sufficient to describe the full current state of the producer, I will call it a snapshot*.* A delta, on the other hand, is a dataset that contains only the changes since the last snapshot was taken. The producer can control the frequency of the delta file production and in fact build them incrementally small — a technique called micro batching.
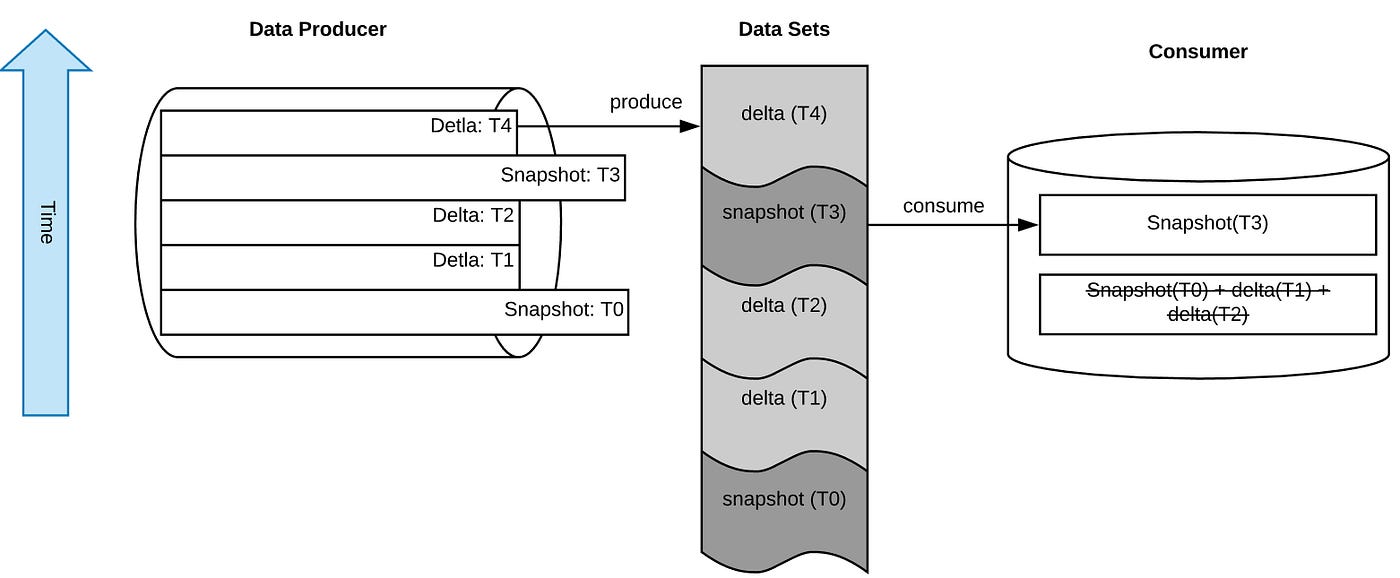
Snapshots are ideal for the consumer to reset itself (e.g. if applying the delta causes inconsistencies or the consumer is simply not able to keep up with the rate of delta files being produced by the producer). That way, the consumer can opt to skip delta files and simply consume the latest snapshot to reset itself. The frequency of the snapshot production itself can be controlled either by the producer or the consumer.
In the following sections I will describe the capabilities of the system that runs in production at Salesforce today.
Data and Metadata
One of the main principles we followed during development of the micro batching solution is the clear separation of data and metadata. Metadata is used to describe the properties of every snapshot and/or delta file and includes attributes like the type of data producer, the producer tenant ID, the kind of data file along with the file identity, production timestamp etc., and whether this is a snapshot file or a delta file with the sequence number and reference to the applicable snapshot.
The metadata layer is flexible and can take any custom attribute that a domain deems necessary to describe their files with. What we mean here by domain is a set of entities described in our functional domain model and can be any part of the system that manages data, such as the products and catalog service, the pricing service, or the order service. A tenant is the owner of its data across all domains in a multi-tenant architecture, and we identify the tenant with every dataset.
Here is an example metadata object for a tenant “goodstuff_01” looking to publish their catalog domain data for one of its stores. Exactly which store is described with custom attributes:.
# System attributes
PRODUCER_TYPE=ecommerce
PRODUCER_TENANT_ID=goodstuff_01
DATASET_DOMAIN=catalog
DATASET_TYPE=snapshot
DATASET_FORMAT_TYPE=plain-text
DATASET_FORMAT_VERSION=1.0
DATASET_IS_COMPRESSED=false
DATASET_IS_ENCRYPTED=false
# Custom attributes
CUSTOM:WEBSTORE=goodstuff.com
CUSTOM:DESCRIPTION=Product catalog of the GoodStuff eCommerce store
For the data itself, we simply provide a protected and isolated storage area for every producing tenant. If you use hierarchical data stores, you can group delta files and snapshots easily.
There is one client library that can be linked with the producer or consumer as a dependency. You assume a role of either data producer or data consumer with this client, or you can assume both roles combined. If your role is that of a consumer, there are options to long poll the metadata APIs for new records or register a call-back endpoint to get notified with a webhook. With an update from the metadata layer, you can then fetch the data file itself.
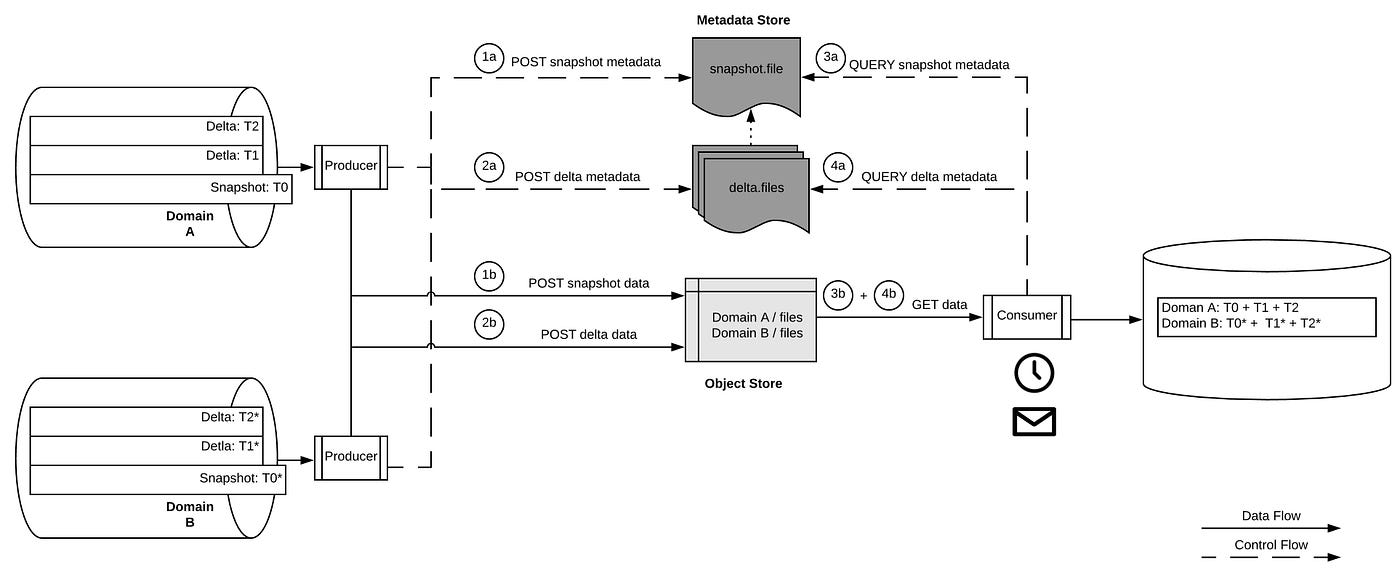
The diagram depicts a typical flow where producers (two in this case) deliver their data to a consumer. First, the producers describe the details of their respective snapshot or delta files into the metadata store (1a + 2a). Next, they deliver the actual data file into the object store for consumption (1b + 2b). Both these actions are combined into a single API endpoint implemented with the producer library. Given that a single endpoint results in two actions (metadata post and data upload), we build resiliency and fault tolerance into the producer to provide transactional guarantees. A transaction is considered complete only after the data files have been uploaded to the object store. At that point we mark the metadata record as visible to the consumer with a reference to the data object.
The consumer finally receives the updates from the metadata store (either through notification or by query) for new snapshot files (3a) or new delta files (4a) to consume from the object store (3b + 4b).
System Synchronization
The architecture I have shown thus far makes one strong assumption: all data posted to the object store is immediately “live” and available in production. In reality, however, many systems have data lifecycle phases where data moves from development → staging → production environments. Wouldn’t it be great if we could replicate the data set from the pre-production environment and then set it “live” with a simple trigger event? With the addition of event handling on top of our metadata store we can do exactly that. This small addition elevates our data replication solution to a system synchronization solution.
To illustrate this, let us consider an ecommerce platform with multiple functional domains; for example, a product and a search domain. A merchant may load a product catalog into the staging environment of this ecommerce platform (marked yellow in the diagram) and then continue to work on the product catalog until a point when they want to promote the catalog to their production environment. They post the data and metadata to the object and metadata store respectively (1a + 1b) and mark the data ready for consumption (1c).
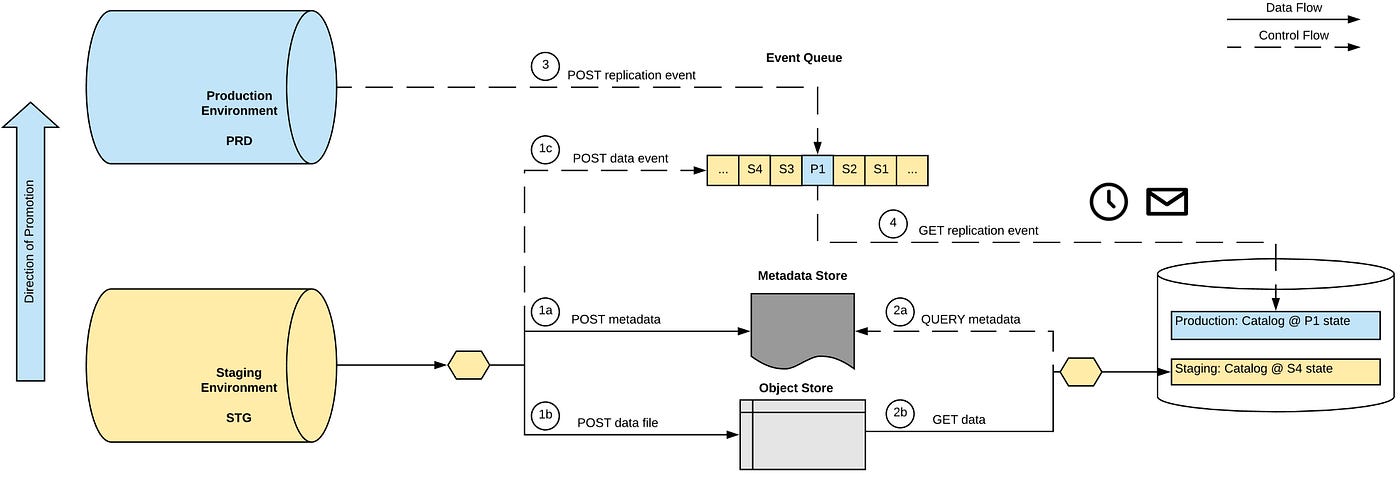
The consuming domain here is the search and discovery engine, one that has to index the product catalog but only make those products that have actually been promoted to the production environment already searchable on the storefront. The search system consumes the product catalog (2a + 2b) but keeps the product index offline for the time being. When the product catalog is actually being pushed to production, a single metadata event (3) is posted to the event queue. Consuming that event (4), the search system now updates the state of the already-indexed product catalog to activate it. Meanwhile, the product catalog can keep changing in the staging environment, which the search system consumes for the next index build.
CQRS for on-demand data delivery
Taking the idea of an event queue to one more level, we can actually build system synchronization where the consumer requests the data they want the producer to respond with next. CQRS (Command Query Responsibility Segregation) is a pattern that can be applied here.

What looks like a task queue in the diagram is really just a metadata object without any associated data, created by the target system to communicate its requests to the data producers (1). The producers are configured as consumers in this case and get notified on new data requests (2). Notification here can be realized webhook style, long poll APIs, or even time based queries triggered by the data owning domain.
The producing domain then delivers data back to the metadata and object stores (3a + 3b), along with an event to the response queue (3c) indicating to the consumer that the data is available. The target system in turn subscribes to those results (4a) and can update itself with the produced data (4b + 4c).
Micro batching
Now that I discussed how to replicate datasets, how to replicate datasets eagerly, and how to replicate datasets on demand, I want to look at one more optimization technique: micro batching.
“Micro batching is a technique where incoming data to be moved is grouped into small batches to achieve some of the performance advantages of batch processing, without increasing the latency for each data element too much. Micro batching is typically applied in systems where the frequency and distribution of data arrival is variable. The system will grab whatever incoming data has been received in a time window and will process it in a batch. The process is executed repeatedly.” [1]
Many streaming systems, such as the Spark Streaming RDDs, actually use micro batch processing to achieve scalability. In our case, we want to approach the problem from the other end to achieve better latency by breaking our large batch requests into incrementally small micro batch requests.
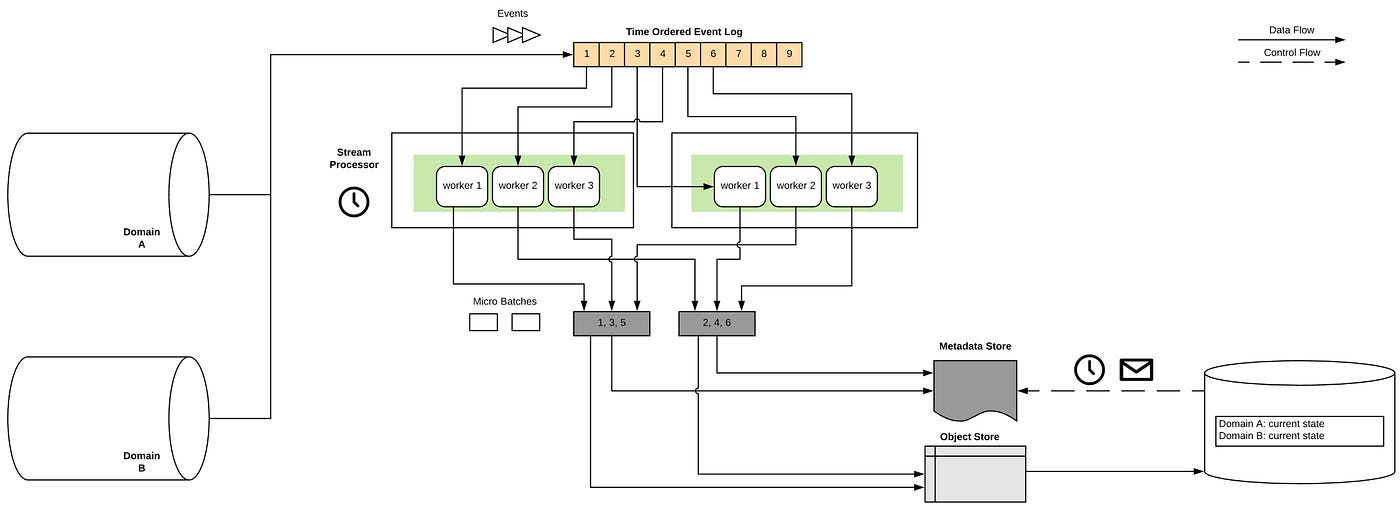
Instead of synchronizing our target system by delivering snapshot and delta files, we now configure our producers to deliver every record change as event onto a time ordered event log. The “batching” itself is being done by parallel stream processors that aggregate the stream into incrementally small delta files and post them into the object store along with a metadata record to the metadata store. The consumer continues to consume the micro batch at its own read rate, albeit in much smaller increments as configured by the system.
The configured size (in time or space) along with the number of concurrent stream processing nodes controls the latency we can achieve for our eventually consistent replicas.
Conclusion
There are many approaches to building high scale/low latency integrations for data-rich systems. This blog introduced one purpose-built solution we leverage in our ecommerce offering here at Salesforce. It uses datasets and applies key principles familiar to data integration technologies, including
- snapshot and delta file separation as used in replication
- data and metadata separation as used in ETL
- micro batching as used in stream processing
We use our implementation to produce eventually consistent replicas, to synchronize multiple domain services, and to distribute data across the compute environments.
As with everything in technology, no one solution meets all needs. Our de-coupling of producer from consumer means no delivery guarantees and some guesswork when it comes to expiring both data and metadata. At the same time, we don’t apply any filter predicates and err on the side of over-delivering data on the producer side. All required data transformation adds additional latency and should ideally be pushed down into the producer domain, as close to the data as possible.
