How Pinterest Accelerates ML Feature Iterations via Effective Backfill
[

Authors: Kartik Kapur, Tech Lead, Sr Software Engineer | Matthew Jin, Sr Software Engineer | Qingxian Lai, Staff Software Engineer
Context
At Pinterest, our mission is to inspire users to curate a life they love. To achieve this, we rely on state-of-the-art Recommendation and Ads models trained on tens of petabytes of data over the span of many months of engagement logs. These models drive personalized recommendations, showing users content that resonates with their interests. These models show significantly better performance when trained on large datasets with events spanning over many months of events.
Our ML Models are trained on a wide range of features, including Pin, user, advertiser-level, and session-based features. Experimenting with these features is a common task, and the first step in this process is integrating new features into the training dataset.
The most straightforward method of incorporating features into the training dataset is through Forward Logging: adding the features into our serving logs and waiting for it to accumulate enough data for training.
However, this method presents several challenges:
- High Calendar Day Cost: Every iteration takes 3~6 months to be hydrated in the training dataset.
- High Development Time Cost: Introducing new features in logging touches multiple systems, including training and serving logic.
- Lack of isolation: Production and experimental features share the logging pipeline. In some cases, adding large experimental features can inadvertently cause data loss incidents.
- Resource wastage and instability: As experimental features are added directly to the production logs and training datasets, it makes the end-to-end data pipeline expensive.
Feature Backfill is an alternative to forward logging that is commonly used to address these challenges. Feature backfill involves counter-factually computing the historical feature values and joining it with production training data using offline batch processing. Feature backfill allows us to greatly cut down calendar day costs, enabling faster iteration and more efficient use of our engineering resources.
In this blog post, we’ll explore how we’ve created our Feature Backfill Solution, leveraging various techniques to reduce costs and iteration time by up to 90x¹.
Structure of Recommender / Ads Training Datasets
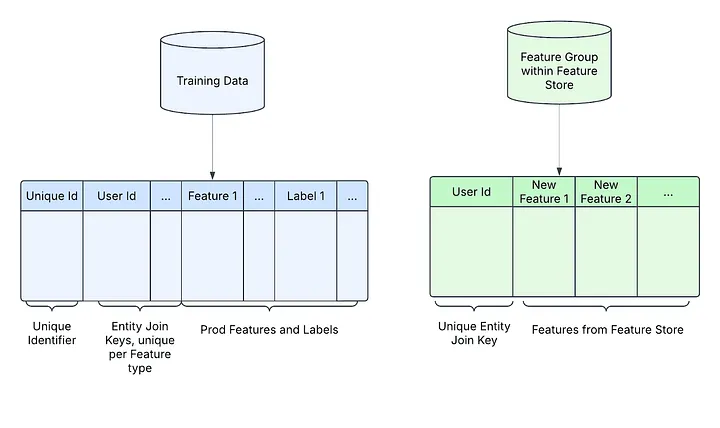
Below is a simplified representation of the datasets we are dealing with. Feature groups are collections of logically and physically related features in a Feature Store, designed to be produced, updated, and stored together. These groups are keyed by specific entity identifiers, such as advertiser IDs or user IDs. For the remainder of this blog post, we will specify user id as the entity key.
[2022–2024] Features Backfiller v1: Full Backfill per Feature Group
In 2022, we developed our initial backfill solution using Spark to materialize features within our training tables. This solution operates as a reusable Airflow DAG that is triggered by ML Engineers on Demand. Each Airflow DAG run contains multiple Spark jobs that each run the backfill application on the target training tables. The backfill application itself does the following work:
- Extracts feature groups from the Features Store (features are materialized in offline storage optimized for batch read), alongside the training dataset, aligning them by a common partitioning key (e.g. date).
- Joins the feature groups with the training dataset using entity keys (e.g. user id).
- Overwrites the same partitions in the training dataset with the new output.
The overall process then looks as follows:

The majority of computational effort occurs during the join stage, where both datasets are shuffled and partitioned for each feature group.
OnDemand Features
The backfill approach listed above works effectively when the feature is already stored in a feature store. However, if the feature is not yet materialized, engineers face the additional challenge of backfilling their features in the feature store before they can perform the training data backfill. This additional step can add up to three weeks of calendar time.
To remove this bottleneck, we introduced a concept of on demand features. Users express a feature in terms of a Spark transform and run the computation prior to joining the training table with their features without ever materializing the intermediary output. With this approach, engineers no longer have to wait for a full backfill to the feature store before proceeding with their iteration.
The transformation code that is utilized to backfill the feature becomes a part of the feature definition allowing for seamless integration and no user interface difference when initiating the backfill.

Key Functionalities
To enhance the utility of this backfiller, we made several iterations to address critical aspects. Below are some key learnings from the backfiller v1.
Time Correctness Alignment Tuning: Proper alignment between feature group partitions and the training dataset is crucial. Misalignment can cause feature leakage (future events leaking into current partitions) or feature lagging (irrelevant features entering training data). Our backfillers provide various partition alignment strategies, allowing users to choose based on specific use cases.
Version Control and Rollback Support: Because backfilled data overwrites production data, it’s essential to protect the integrity of the training dataset. The backfilling process may introduce bugs or misconfigurations, and regenerating production data is often costly and time-consuming. We implemented partition-level version control and rollback tooling to recover data during incidents.
Standard Feature Statistics: Verifying backfill data quality is another critical requirement. By computing standard feature statistics based on feature types and generating reports, users can quickly assess feature quality before model training and evaluation.
Workflow Templates: Backfill is a standard data processing task, yet a common operation. We’ve built workflow templates to streamline backfill launching, reducing human error during configuration. Users simply provide feature groups and a backfill data range to trigger new backfill operations.

Utilizing S3 Persist: Backfill jobs are extraordinarily expensive and are very disk intensive due to the large amount of shuffles between multiple tables, as well as large quantities of cached data going to disk and long spark lineages. To alleviate the issues, we initially tried using native Spark Checkpointing²; however, we found this had inefficiencies for tabular data compared to reading and writing Parquet files, namely it became extremely difficult to prevent rate limits and read times ballooned since data was stored in heavily serialized java byte arrays with checkpoint. We then created our own “S3 checkpointing,” which writes the intermediate data to parquet with short retention. This helped solve our issues by pruning lineage completely and alleviated disk issues.
Challenges
While this backfiller provides features more quickly than the number of days being backfilled, several challenges remain:
- No Concurrent Backfills: Since each backfill writes data in place, multiple backfills cannot occur simultaneously on the same partition. This necessitates organizing a queue to manage the sequence of backfills.
- High Compute Cost: Backfills can be extremely expensive, with costs exceeding $X million in EC2 expenses. This is primarily due to significant data shuffling, upwards of 90 Tib per job, during joins, which imposes heavy demands on network and disk resources, leading to elevated compute costs and job instability.
- Manual Partition Management: The current versioning and rollback system requires manual partition management in the Hive table, precluding the use of Hive’s dynamic insertion functionality. This creates significant overhead during data commits. For instance, hourly partitioning requires 24 insertions per day’s backfill. Since feature sources are often daily-partitioned, these inefficiencies add unnecessary computation. Some datasets contain even more partitions, impairing job performance.
While these issues are not unique to feature backfill, the process is particularly vulnerable due to the complexity and volume involved. Feature backfilling often deals with large, intricate datasets, such as extensive user sequence features, which are particularly costly and resource-intensive to manage. For instance, four developers each backfilling a feature group into the training dataset over a 120-day range currently face a cumulative 140-day completion time — clearly suboptimal.
[2024–2025] Features Backfiller v2: Two-Stage Backfill
To address the challenges we encountered with our v1 backfiller, we developed a v2 version, adopting a two-stage backfill approach. This new method streamlines the process into two key stages.
Stage1: Feature Staging
In this first stage, the feature group is joined with the IDs of the main training table. The resulting data — consisting only of primary keys and features — is output to an intermediate Staging Table.
Stage2: Feature Promotion
In this stage, multiple intermediate staging tables are collectively joined into the main training table in a batch process.
Visually, Stage 1 looks as follows:

After multiple stage 1 backfills complete, we perform stage 2:

This two-stage approach has advantages in addressing the challenges faced previously:
- Stage 1 is designed for parallel execution. Multiple backfills for the same dataset can occur simultaneously without blocking each other, leading to enhanced collaboration and reduced wait times.
- Compared to the full backfill, the stage 1 operations are much more lightweight because they join only a subset of ID columns rather than the entire dataset. This minimizes data shuffling, reducing computational costs and time.
- Since Stage 2 operations are only done after many Stage 1s have completed, the cost of performing adding any single set of features goes down by a factor equal to the number of tables being promoted.
- By separating the intermediate table from the main production table, we mitigate the risk of inadvertently affecting production data. Feature statistics can be easily computed on this intermediate staging table, and only verified features proceed to the production dataset during Stage 2.
For the same example where engineers took 140 days to backfill their features, the new 2 step backfill approach took a total of 26 days — an overall 82% improvement.
Optimization: Enhanced Two-Stage Backfill with Iceberg Table Format
Another architectural change in the Backfiller v2 is switching the data warehouse engine from Hive to Iceberg. This shift brought several key benefits:
- Iceberg enables dynamic partition insertion functionalities, allowing us to commit multiple partitions within the span of a single data epoch. This significantly reduces the manual overhead of inserting into individual partitions, diminishing costs and resolving the major bottleneck during write. Previously, per-partition insertion would take 12 hours; dynamic partition insertion reduces this to just one hour — an impressive 12x improvement.
- We enhanced our version control and rollback support by leveraging Iceberg’s flexible snapshot management system. We implement this rollback support by cherrypicking data partitions from previous snapshots to overwrite the current snapshot. Since these operations are primarily metadata-only operations, they can be performed swiftly and efficiently, ensuring quick recovery and minimal downtime.
- The Iceberg format offers great support for table partitioning schemas, enabling the development of a bucketing partitioning strategy. This allows for efficient storage-partitioned joins, which significantly reduce shuffling during both Stage 1 and Stage 2 operations. Our observations indicate up to a 3x speed increase for backfills.
- By leveraging bucketing and local bucket sorting, data compression potential is unlocked. Tables’ sizes are compressed to as little as 25% of their original size, achieved through sorting and bucketing by UserId. This organization allows grouping of user-sequence features³ adjacent to each other, facilitating effective Delta Encoding⁴ for these sequences.
The Stage 1 process utilizing Iceberg looks as follows (Inputs contains multiple partitions and leverage dynamic partition insertion to overwrite the corresponding output):

The Stage 2 Feature Promotion Process then visually looks as follows (Used storage partition join to replace the full shuffle join):

Furthermore, to streamline the initiation of new backfills, the team has developed a dedicated backfiller UI, making the process straightforward and user-friendly.

[2025+] Training Time “Backfill” via Ray Bucket Join
How can we further enhance the backfiller experience? While we’ve already achieved considerable efficiency gains with the two-stage backfill approach and by leveraging Iceberg, the Stage 2 process still requires users to materialize the full training dataset before model training which can take multiple days for a large training window. Imagine if we could entirely bypass Stage 2 and proceed to train models directly using the intermediate staging tables produced in Stage 1. Achieving this would require a data loader capable of joining the training data with these staging tables on the fly. This led us to build the next generation training time backfill with Ray.

*(chart from previous Ray last mile data processing blog)
Ray is an open-source framework that excels in building distributed applications. It provides the flexibility to manage heterogeneous types of instances and distribute the workload in a resource-aware manner. Since 2023, Pinterest has been utilizing Ray to build our training platform (more details in our previous blogs posts: Last Mile Data Processing⁵, Ray Infrastructure at Pinterest⁶, Ray Batch Inference at Pinterest⁷) and leverage Ray’s data component aids in optimizing data loading speeds, enabling us to horizontally scale CPU resources for data loading workers and unlock various training-time data processing capabilities, such as joining staging tables with the training dataset. However, Ray’s data processing emphasizes a streaming execution paradigm, which is not well-suited for the typical data shuffling required by hash join workloads. This limitation was one of the motivations for adopting Iceberg in Backfiller v2 and implement bucketing partitioning on the training dataset. Bucketing partitioning allows the data to be partitioned by on a hash modulo operation on specified columns (e.g. request_id):
bucket(request_id, 16) → hash(request_id) % 16
With standardized bucketing across staging tables and training tables, we can effectively implement a map side bucket join inside Ray data loader workers.

The idea is simple: during training, data loader workers analyze the data distribution, bucketing information from both the training dataset and the staging table. Assuming both tables have the same bucketing schema, the data loader worker then selectively loads files from corresponding buckets across multiple tables, dynamically joining them into a single data block. This block is then sent to the trainer for processing or training. Although this method demands additional computational resources, Ray allows us to scale up CPU resources effectively, ensuring that training speed remains consistent and unaffected.
While adopting Ray and Iceberg offers substantial benefits, it’s important to acknowledge the technical complexities involved, which can be more challenging than they initially appear. For example, implementing bucketing and sorting can alter dataset distributions, and migrating the entire existing training stack to a new platform is a significant undertaking that could warrant an entire chapter in itself. Our teams are actively addressing these challenges. Stay tuned for future blog posts as we unveil more about this journey.
With the inclusion of in-trainer join functionality, we can streamline and speed up our feature testing process significantly. New feature experiments begin with a quick Stage 1 backfill using a dedicated UI. Once these features are verified, they can be directly used for model training in offline evaluations. If the features meet the evaluation criteria, users can proceed with the Stage 2 operation to promote them to the production dataset and initiate online experiments.

Summary
Our multi-year journey in enhancing Pinterest’s feature backfilling experience reflects a commitment to innovation and efficiency, transitioning from forward logging to a refined two-stage backfill process. Feature Backfiller v1 used Spark for full backfills, significantly reducing calendar day costs and accelerating feature iteration, though it also highlighted the need for further optimization. This led to Feature Backfiller v2, featuring a two-stage process that optimized parallel execution and minimized data shuffling, supported by the Iceberg table format for enhanced partition management and version control. These advancements resulted in a 90 times speed up in completion times and improved data compression by up to 75%. As we look ahead, our training-time “backfill” approach with Ray aims to further streamline processes by enabling on-the-fly data joins during model training, ensuring that our recommendation systems continue to deliver inspiring, personalized experiences efficiently.
Acknowledgements
This project represents a collaborative effort across many teams at Pinterest. We wish to acknowledge and thank them for their significant contributions to this workstream.
- ML Platform: Rubin Ferguson, Yi He, Matthew Almeida, Andrew Yu
- Ads ML Infrastructure: Chao Huang, Harshal Dahake, Xinyi Zhang, Haoyu He
- Core ML Infrastructure: Laksh Bhasin, Jiahuan Liu, Henry Feng, Alekhya Pyla, Dave Chen
- Big Data Platform: Ashish Singh, Pucheng Yang
- Analytics Platform: Surya Karri
- Leadership support: Se Won Jang, Joey Wang, Shun-ping Chiu, Colin Leatherbury, Archer Liu, Shu Zhang, David Liu
References
¹Pinterest Internal Data March 25, 2024
²Apache Software Foundation. “pyspark.sql.DataFrame.checkpoint.” Apache Spark Documentation, Version 3.5.0, 2024, https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.DataFrame.checkpoint.html
³Pinterest Engineering. “Large-Scale User Sequences at Pinterest.” Medium, 6 Sept. 2023, https://medium.com/pinterest-engineering/large-scale-user-sequences-at-pinterest-78a5075a3fe9
⁴Apache Parquet. “Delta Encoding (DELTA_BINARY_PACKED).” Parquet Documentation, 2024, https://parquet.apache.org/docs/file-format/data-pages/encodings/#delta-encoding-delta_binary_packed--5
⁵Pinterest Engineering. “Last-mile Data Processing with Ray.” Medium, 13 Oct. 2023, https://medium.com/pinterest-engineering/last-mile-data-processing-with-ray-629affbf34ff.
⁶Pinterest Engineering. “Ray infrastructure at Pinterest.” Medium, 19 Oct. 2023, https://medium.com/pinterest-engineering/ray-infrastructure-at-pinterest-0248efe4fd52.
⁷Pinterest Engineering. “Ray Batch Inference at Pinterest (Part 3).” Medium, 14 Mar. 2024, https://medium.com/pinterest-engineering/ray-batch-inference-at-pinterest-part-3-4faeb652e385.