Scaling Nextdoor’s Datastores: Part 5
In this final installment of the Scaling Nextdoor’s Datastores blog series, we detail how the Core-Services team at Nextdoor solved cache consistency challenges as part of a holistic approach to improve our database and cache scalability and usability.
In Part 4: Keeping the cache consistent, we highlighted a class of consistency issues arising from racing cache writes and introduced an approach for forward cache versioning as a mechanism to avoid inconsistencies. The cache is able to decide which write to persist and which to reject because it is aware of the version of data it currently has. However, this is only a partial solution because it assumes writers will always succeed in communicating with the cache in a timely manner, if at all.
Missed Writes
Let’s consider the scenario where Writers A and B both performed an update to the same row in the database and have not yet updated the cache. Writer A holds Version 1 and Writer B holds Version 2. What happens if Writer B with Value 2 fails to talk with the cache?

Writer B fails to write to the cache.
In this case the result is that the cache becomes inconsistent and we can’t rely on the writers to provide that consistency. A process must exist outside of this interaction to fix-up the cache when Version 2 is written to the database but fails to be written to the cache.
Change Data Stream
To solve this problem we tap into a common feature provided by most modern databases, a Change Data Capture (CDC) Stream. A CDC Stream is a mechanism to subscribe to row level changes in a database.
The change stream contains a row’s previous column values along with the new values. Here’s a visual example of the change stream when the last_name field gets updated in the database.
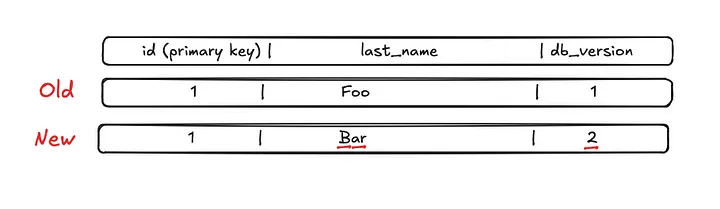
For visual clarity the changed values have been underlined in red.
Reconciler
Since the database is the source of truth and the CDC Stream emits all changes, a consumer of this stream can clean up any consistency issues in the cache. In our system we call this process reconciliation and it’s performed by the ”Reconciler.”

The reconciler is responsible for converting CDC change information into input for the del_if_version call to the cache. The arguments for the del_if_version are the version and cache key.
As discussed in part 4, del_if_version performs conditional deletion of data in the cache (as evaluated by the cache itself) if the supplied version is less than the provided version.
Author’s Note: Having both old and new column values is particularly important when your cache key is comprised of row values or if you have secondary cache keys for unique column values.
For the above example the del_if_version function call would have parameters version=2 and key=lastnames:1. The key parameter is made up of two parts, the table name (lastnames) and the primary key for the specific record (row 1).
Reconciling Missed Cache Writes
Having covered the building blocks, let’s reconsider the case of a missed write. In the below diagram we show that the Reconciler is able to delete Version 1 from the cache in the event Writer B does not succeed in updating the cache with Version 2.

Author’s Note: Astute readers will point out that we could have avoided this issue if the database change stream was used to update the cache. The caveat to this approach is that if you want to keep a look-aside cache design, you then must maintain two different methods of serialization (from ORM objects and from the raw change stream) in sync.
Missed Write During Cache Fill
Thus far we’ve only discussed writers doing database updates and then updating the cache. However, anytime a reader checks the cache and gets a miss, the reader must populate the cache after fetching from the database.
The last scenario to consider is what happens when a reader is populating the cache due to a cache miss while a writer is performing a write? Depending on the timing of the sequence of steps the cache may become inconsistent. Consider the following:
- Due to a cache miss the Reader reads Version 1 from the database
- The Writer reads Version 1 from the database, performs business logic, and writes Version 2 to the database
- The Writer fails to write Version 2 to the cache
- The Reconciler receives Version 2 and deletes Version 1 from the cache
- After some time the Reader re-populates Version 1 in the cache
The end state is the cache has Version 1 and is now inconsistent with the database.

Reconciling Missed Write During Cache Fill
The solution to this consistency problem is conceptually simple. The Reconciler must lag behind such that Step 4 in the above diagram happens after Step 5. However, a problem arises in that until the reconciler deletes the stale version in the cache, the cache remains inconsistent.
For our desired consistency level we wanted to have the Reconciler fix-up the most commonly occurring issues as quickly as possible. In practice missing writes are extremely uncommon for us.
A simple solution to this problem is having two reconcilers. One instance is reading the change stream and applying fixes to the cache in near real time while another one is always a fixed amount of time behind performing any final mopping up. In our case this delay was slightly higher than our web request timeout.
Author’s Note: There are a handful of other scenarios where a cache inconsistency may occur, but those are fairly complex to articulate. We encourage readers to think through the cases of incomplete and out of order steps. Readers will find that the two-pass reconcilation handles those cases.
Reconciliation Pipeline Implementation
The discussion about reconciliation has, until now, been theoretical, without addressing the key implementation details and design goals. One functional requirement was to guarantee that users have a cohesive experience, such as seeing their own writes reflected after a page refresh. This meant that reconciliation needed to happen in near real time to provide a seamless experience in the event of a missed cache write.
The choice to use row versions for conditional deletion of cache keys has a subtle but important consequence: changes do not need to be processed in order. This conscious design choice meant that we could horizontally scale our processing in order to satisfy low latency reconciliation.
The Reconciler, which we have only discussed conceptually until now, is actually made up of three different pieces.

Pg-bifrost
Pg-bifrost, an open-source tool previously developed by our team, consumes the PostgreSQL WAL Replication log (CDC Stream) and republishes it for use in other applications. It was built with low latency republishing in mind.
Apache Kafka
Kafka was selected as our persistent message bus for the WAL change stream from the database due to its low latency, persistence guarantees, and well-supported consumer and producer APIs. As Nextdoor was already utilizing Kafka, it was a natural choice for our team.
Reconciler
The reconciler is simply a GoLang based Kafka consumer that reads the WAL change stream and executes Redis del_if_version calls. The two-pass reconciliation, discussed earlier, was implemented using a time wheel to maintain a fixed offset while remaining relatively straightforward.
Putting It All Together
This series began by exploring typical relational database scalability issues and the questions teams must consider when addressing them. Part 2 presented an approach to improve read replica usage with semi-intelligent routing. Part 3 discussed the importance of serializing cached data and its impact on scalability. Part 4 outlined a cache consistency strategy using row versions and conditional upserts. The final installment, Part 5, highlighted consistency issues and profiled a reconciliation system to maintain database-cache consistency.
This multifaceted strategy solved the following scalability challenges for our datstores:
- Reduced the load on our primary PostgresSQL databases
- Ensured that only forward versions of database rows were cached for a limited time
- Prevented thundering herds to the cache and databases when database schemas changed
- Made better use of read replicas, which enable effective horizontal scalability for RDBMS
Future Work
This project was a stepping stone on our database scalability journey. Keen readers likely noticed that our caching system is limited to retrieving items by their primary key or unique attributes. This is due to the fact that key-value storage in a cache is best suited for these types of lookups, and they are essentially an extension of unique database indexes.
The next step in our database scalability journey is to enable the storage of lists within the cache. This enhancement will allow us to efficiently handle common database queries, such as “Give me a list of people in a neighborhood”.
Parting Thoughts From the Authors
Slava Markeyev: Technologies like no-SQL and new-SQL are often thought of as magic pill solutions to scalability challenges. While they have many advantages over traditional RDBMS solutions, a datastore can fundamentally only be as scalable as the schema and query patterns allow it to be. Changing those two after the fact is akin to rebuilding the engine while the plane is in the air. Doing so is certainly possible — heck, we tried it — but that is a story for another day.
My parting thought for readers is SQL databases when used in conjunction with secondary indexes like Redis/Valkey for caching and ElasticSearch for search will get you pretty far if you let them.
Tushar Singla: While doing architecture interviews, the need often arises to consider how to scale the database to support 100M or even 1B+ users. A common strategy is to “scale out” or add “caching.” Typically, mentioning those concepts are enough to communicate understanding of these horizontally scaling techniques and the interview moves on. However, only after building out this system in real life at scale can one appreciate the intricacies, complexities, and myriad of edge cases that must be handled in order to serve the users appropriately.
Next time when you mention these techniques during the interview, take some time to consider what it might look like to actually finish the implementation.
Ronak Shah: Scaling a datastore presents unique challenges, and there is no one-size-fits-all solution. Finding the right approach for your system requires thoughtful discussion and a rigorous design process. Although our work was complex and challenging, it was also a truly rewarding experience to be part of.
P.S. Having robust observability tools and a solid unit testing framework can save countless engineering hours spent debugging cache consistency issues.