Achieving Near-Linear Training Scalability for Pinterest’s Foundation Models
[
Pinterest Engineering Blog
](https://medium.com/pinterest-engineering?source=post_page---publication_nav-4c5a5f6279b6-14d4f59fe6f6---------------------------------------)
[

](https://medium.com/pinterest-engineering?source=post_page---post_publication_sidebar-4c5a5f6279b6-14d4f59fe6f6---------------------------------------)
Inventive engineers building the first visual discovery engine, 300 billion ideas and counting.
Sheng Huang | Software Engineer, AI Platform; Pong Eksombatchai | Machine Learning Engineer, Applied Sciences; Saurabh Vishwas Joshi | Software Engineer, AI Platform; Gaurav Arora | Software Engineer, AI Platform; Karthik Anantha Padmanabhan | Engineering Director, AI Platform
At Pinterest, foundation models power recommendations for over 600 million monthly active users. Our latest Foundation Model (ACM RecSys 2025) pre-trains on two years of user activity data and is deployed into Home feed and Related Pins ranking, the platform’s two most important recommendation systems. Multi-node distributed training is the key to unlocking the next level of that capacity.¹
But when we first attempted multi-node training, adding a second machine made training 5x slower, producing a scaling factor of roughly 0.2x. Enabling AWS Elastic Fabric Adapter (EFA) for OS-bypass networking fixed the networking layer and recovered a viable baseline, but scaling was still poor: 1.13x at 2 nodes and 1.21x at 4 nodes. Three extra nodes, 3x more GPUs, 3x more cost, yet only 21% more throughput.
This post describes how we took 2-node scaling from 1.13x to 2.0x and 4-node scaling from 1.21x to 3.9x (97.5% of ideal), then extended to 8 nodes at 7.5x. The larger models this unlocked have driven significant engagement gains across Pinterest’s recommendation surfaces.
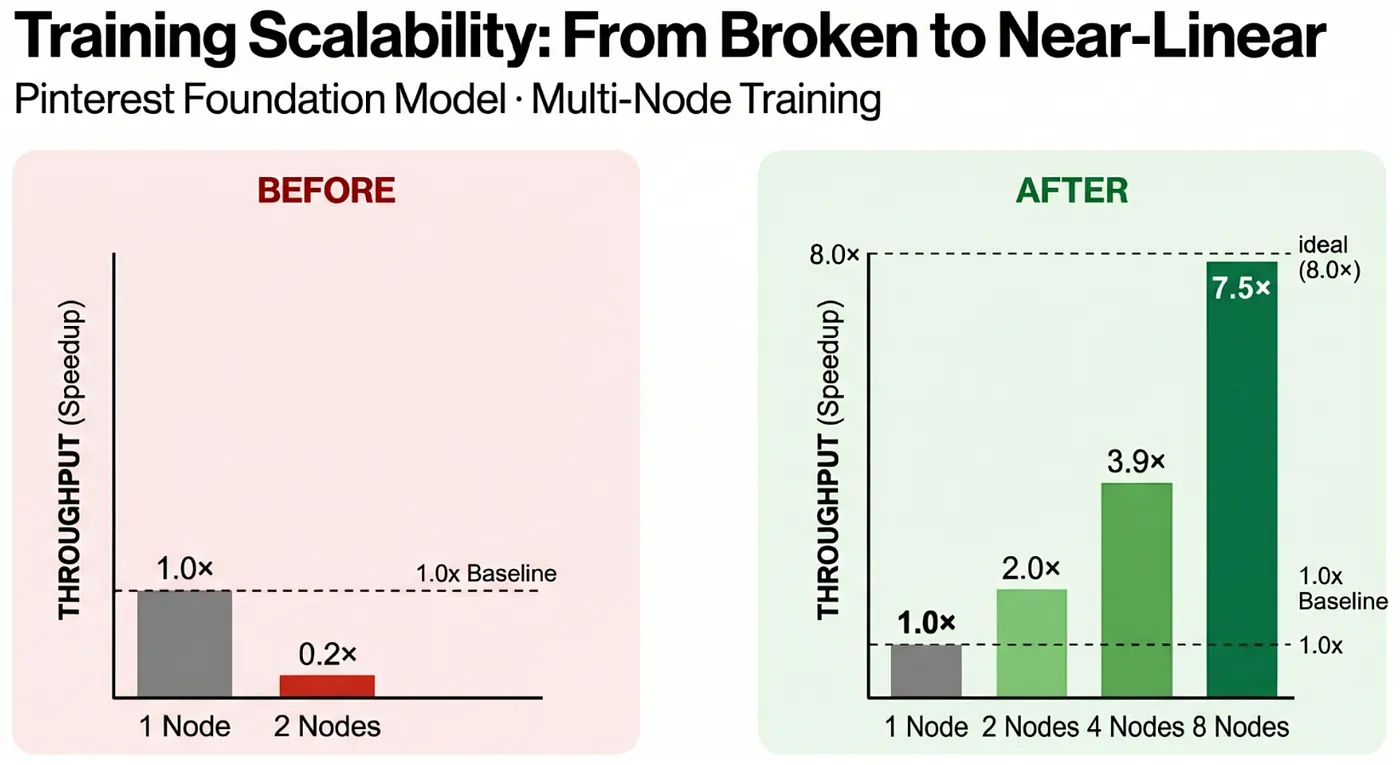
Figure 1: Training scalability before and after optimization. Left: before EFA and optimization, adding a second node degraded throughput to 0.2x of single-node. Right: after optimization, scaling is near-linear across 2, 4, and 8 nodes, with 8-node reaching 7.5x (93.75% of ideal).
Background
Training scalability measures whether adding more resources yields proportionally more throughput. Training efficiency measures how much throughput you extract from the same resources. This post focuses on scalability.
Our Foundation Ranking Model is embedding-heavy: approximately 99% of parameters reside in embedding tables, with the dense transformer layers accounting for the remainder. These tables exceed single-GPU memory, so we shard them across GPUs using TorchRec’s DistributedModelParallel. Each GPU holds a subset of tables, and during the forward pass, GPUs exchange embedding lookups via NCCL all-to-all operations.
This solves the memory problem but creates a new one: every forward pass generates All-to-All communication proportional to batch size and embedding dimension, and at multi-node scale, that communication cost dominates everything else.
Where We Started
Multi-node training at Pinterest was initially unusable. Without AWS Elastic Fabric Adapter (EFA), which provides OS-bypass networking for NCCL, adding a second 8-GPU node didn’t just fail to help. It made training 5x slower, a scaling factor of roughly 0.2x, pushing performance well below the single-node baseline.
Enabling EFA changed the picture. By bypassing the OS network stack for cross-node GPU communication, EFA delivered a 5x throughput improvement and made distributed training viable for the first time. But viable is not the same as efficient. Even with EFA in place, scaling remained poor:
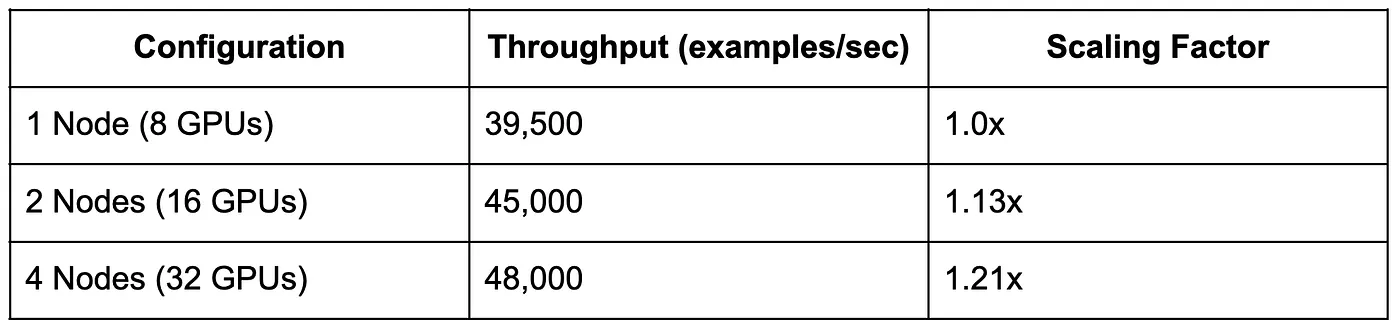
Three extra nodes, 3x more GPUs, 3x more cost, yet only 21% more throughput.
These numbers became our starting point. Everything that follows in this post builds from here.
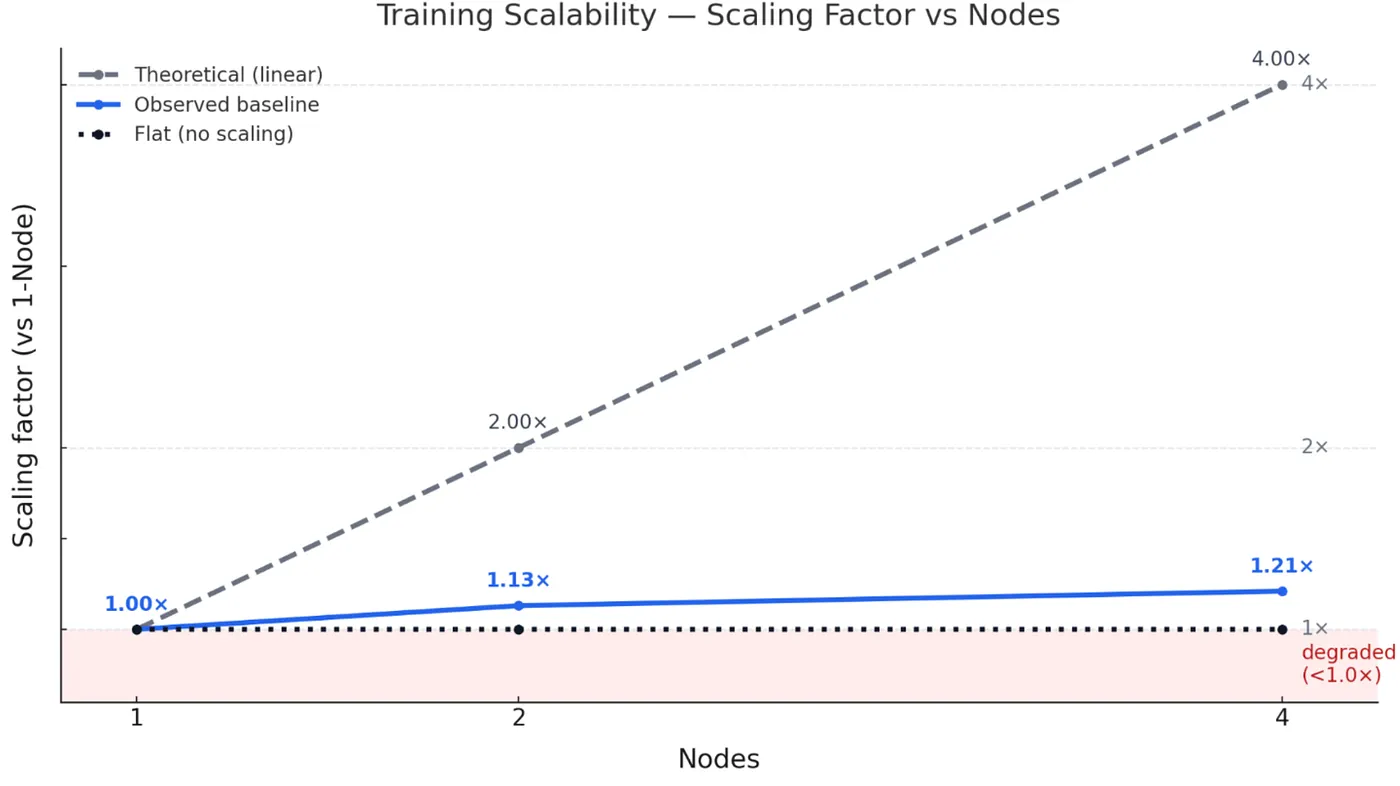
Figure 2: Baseline scaling factor vs. nodes. The blue line shows observed scaling with EFA enabled: 1.13x at 2 nodes and 1.21x at 4 nodes, nearly flat against the theoretical ideal (dashed). The red zone indicates degraded performance below single-node, where our pre-EFA results fell.
Diagnosis
We instrumented training with PyTorch Profiler and collected NCCL traces on single-node and two-node configurations. Rather than guessing, we let the data tell us where the problem was.
The two-node trace told the story immediately. The forward pass, which took ~410ms on a single node, ballooned to ~710ms on two nodes. That 73% increase came almost entirely from one place: NCCL communication for distributed embedding lookups. The trace showed large gaps where the GPU was idle, waiting for data to arrive from the other node.
GPU utilization read 97.7%, which sounds healthy. But SM efficiency was only 54.54%. The GPU was busy, just not doing useful work. It was spending its time waiting on the network.
The bottleneck was unambiguously distributed embedding collective communication. Every optimization that followed was guided by this finding.
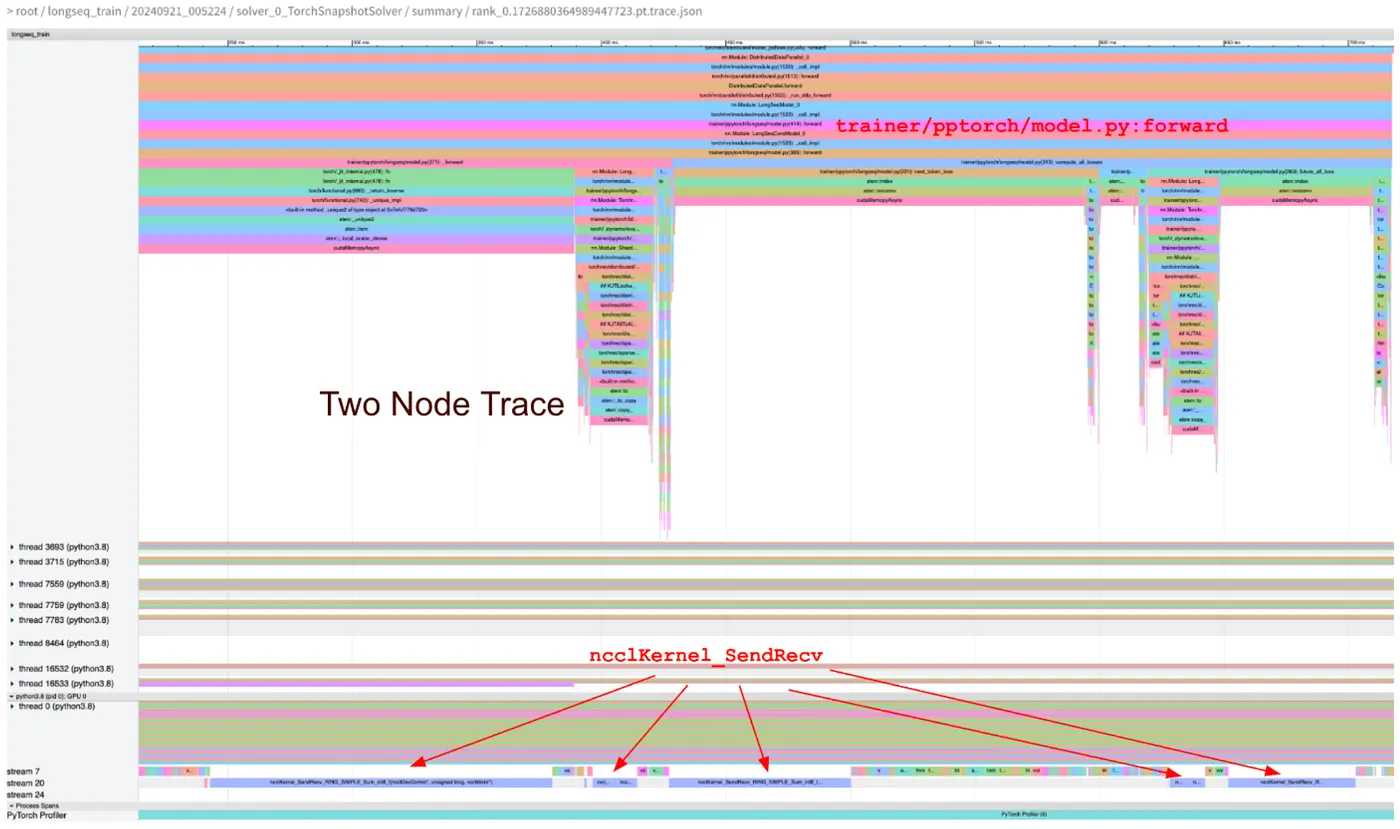
Figure 3: PyTorch Profiler trace for two-node training. The red arrows at the bottom highlight ncclKernel_SendRecv operations, the NCCL collectives responsible for distributing embedding lookups across nodes. The longest of these consumed nearly 20% of the entire forward pass.
Optimization Journey
With the diagnosis clear, we had a roadmap: reduce the volume and cost of distributed embedding communication, layer by layer. EFA had solved the networking foundation, giving us a viable baseline. Now we needed to make that baseline scale.
1. Quantized Communications (QComms)
If the problem is too much data flowing between nodes, the most direct fix is to send less. FBGEMM’s quantized communication library compresses embedding tensors from FP32 to FP8 as a wire format before every NCCL collective, in both the forward pass (all-to-all) and the backward pass (all-reduce), reducing payload size independently of compute precision. Integrated with TorchRec, this is a configuration change, not an architecture change.
The effect was immediate. The single largest NCCL SendRecv operation dropped by over 75%. That one operation alone had been consuming nearly 20% of the forward pass. With QComms, the scaling factor jumped from 1.13x to 1.57x at 2 nodes and from 1.21x to 2.3x at 4 nodes.
We ran full training jobs to verify that FP8 quantization of communication payloads did not hurt model quality. Training loss converged to equivalent values for both configurations.
Sending less data helped enormously. But it also revealed the next bottleneck.
2. Balanced Sharding
With communication volume reduced, we could now see that some GPUs were finishing their work well before others. With table-wise sharding, each embedding table lives on a single GPU, and if the tables are unevenly distributed, the slowest GPU becomes the bottleneck for the entire training step.
The fix was straightforward: match the number of hash partitions to the number of GPUs, so every device gets a roughly equal slice of the embedding workload. The effect was modest at 2 nodes (+5.3%) but substantial at 4 nodes (+15.2%), which makes intuitive sense: more devices means more room for imbalance, and more to gain from evening things out. This optimization was validated in benchmarks; in production, the serving-side embedding configuration constrained independent adoption, but the insight directly informed subsequent design choices.
With communication volume reduced and the importance of load balance established, we started asking a different question: could we reshape the payload itself?
3. Bandwidth-Aware Embedding Optimization
By this point, a pattern had become clear from our profiling: the bottleneck was communication bandwidth, not embedding capacity. The model didn’t need more parameters; it needed to move fewer bytes per collective operation.
This insight led to a reshape. By halving the embedding dimension and doubling the row count, total capacity stays identical. But every All-to-All operation now ships half the data. Scaling factors climbed to 1.78x (2N) and 2.8x (4N). Beyond the throughput gain, this experiment crystallized the core insight: for our model, the scaling bottleneck was bytes on the wire, not parameters in memory. That realization led us directly to rethinking the communication topology itself.
4. 2D Parallel (AllReduce Optimized)
Everything so far had reduced how much data moved through the pipe. 2D Parallel changed where the pipe goes.
Get Pinterest Engineering’s stories in your inbox
Join Medium for free to get updates from this writer.
Standard model parallelism shards embedding tables across every GPU in the cluster. As you scale to more nodes, every embedding lookup has to communicate across the full cluster, including the slow inter-node links. 2D Parallel takes a different approach: instead of sharding across all GPUs, it divides them into groups, typically one per node. Within each group, tables are sharded across GPUs as usual. Across groups, each group holds a complete replica of the model. This way, the expensive embedding communication stays local to each node, and only lightweight synchronization crosses the network.
Our first topology was already a meaningful improvement. Communication operations began executing concurrently, and the overlap alone dropped effective wall time from 25.68ms to 16.98ms. Scaling factors reached 1.90x at 2 nodes and 3.6x at 4 nodes.
Close to linear. But our profiling data was telling us something: we had the topology backwards.
5. 2D Parallel (All-to-All Optimized)
All-to-all dominated the communication profile. With 99% of parameters in embedding tables, the forward pass is essentially a massive distributed lookup: every GPU needs embeddings that live on other GPUs, generating all-to-all traffic proportional to batch size and embedding dimension across every table.
So why were we putting the expensive operation on the slow inter-node link?
We flipped the topology. Each node now runs its own complete set of sharded tables, keeping All-to-All entirely within the node where it benefits from fast intra-node interconnect. Replicas sync across nodes via AllReduce, the cheaper operation. All-to-all latency, which started at 78ms before any optimization, reached 13ms. An 83% total reduction. The result: 2.0x scaling at 2 nodes and 3.9x at 4 nodes, 97.5% of theoretical ideal.
Detailed throughput and scaling numbers for each technique:
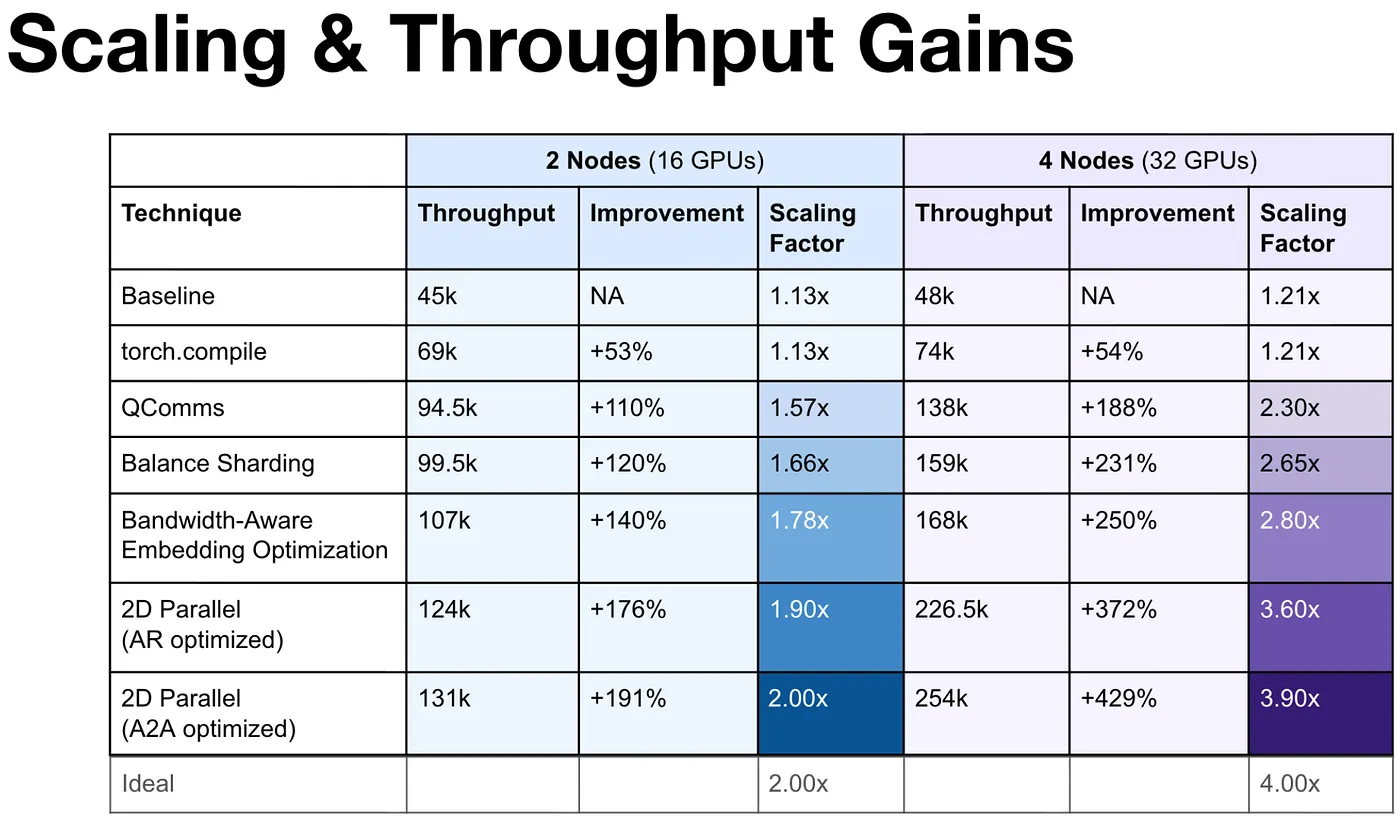
Figure 4: Cumulative throughput and scaling gains. Each row adds one optimization on top of the previous.
The final scaling factors: 2.0x at 2 nodes, 3.9x at 4 nodes. With all five optimizations in place, we extended to 8 nodes (64 GPUs) and measured a 7.5x scaling factor with 490k examples/sec throughput, 93.75% of theoretical ideal. The optimization stack that got us to near-linear at 4 nodes continued to hold at 8. Separately, we applied torch.compile to the forward pass and loss computation for a 55% single-node throughput gain through kernel fusion, complementing the multi-node scaling stack.
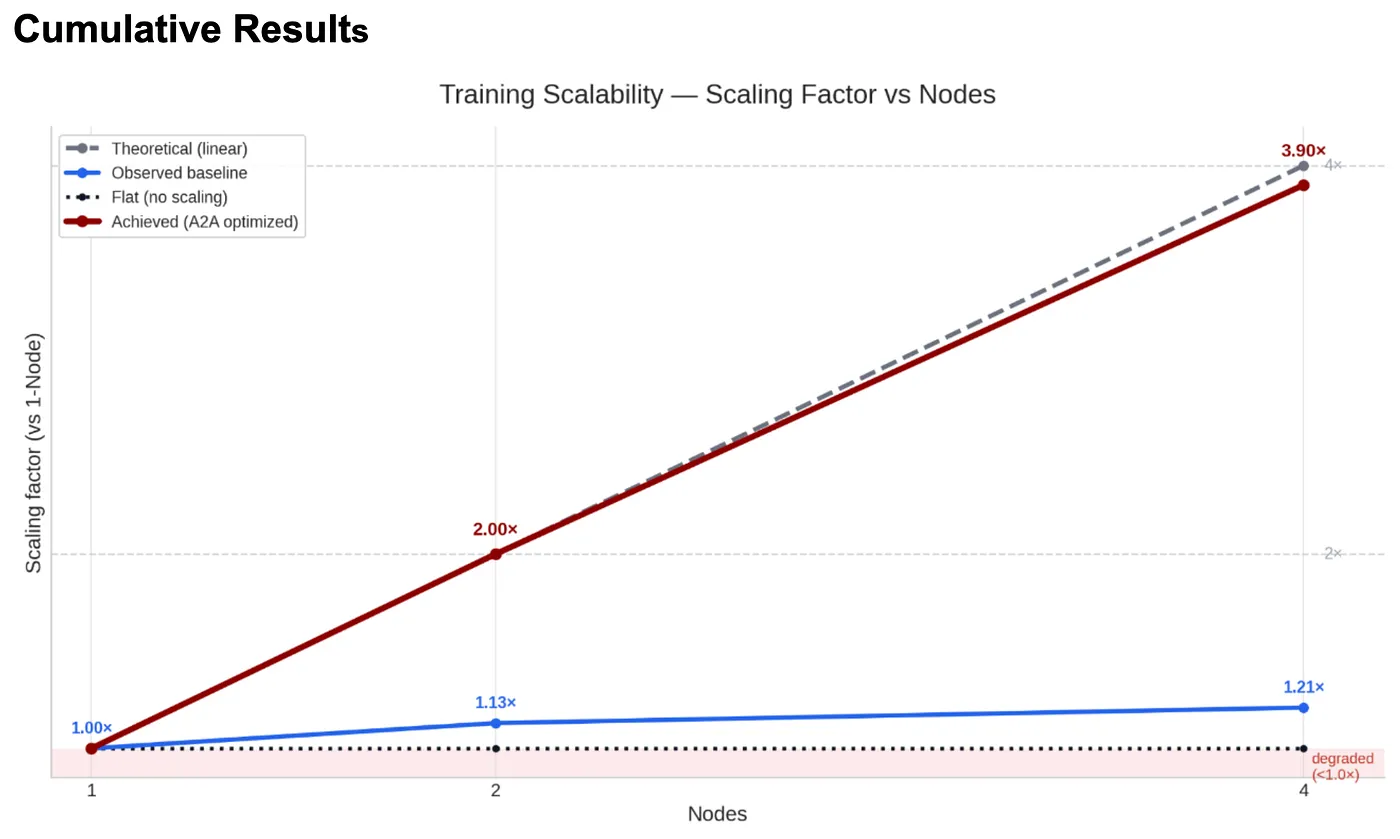
Figure 5: Scaling factor vs. nodes before and after optimization.
The transformation is clear. At 2 nodes, scaling improved from 1.13x to 2.0x. At 4 nodes, from 1.21x to 3.9x, reaching 97.5% of theoretical ideal. With the full optimization stack in place, we further extended to 8 nodes (64 GPUs) and measured a 7.5x scaling factor with 490k examples/sec throughput, 93.75% of ideal. All scaling factors are relative to the optimized single-node baseline. Measuring the full journey from pre-EFA to fully optimized, 2-node throughput improved 13x.
All results in this post were measured on p4d instances with A100 GPUs. The optimizations are hardware-agnostic by design: 2D parallelism confines embedding All-to-All to intra-node NVLink, eliminating cross-node All-to-All, and quantized communication reduces payload. Because these techniques remove cross-node traffic structurally rather than relying on faster interconnects, they transfer directly to newer hardware generations.
Production Impact
Multi-node training unlocked the ability to train significantly larger models, both deeper and wider, than what was previously possible on a single node. These larger models enabled new optimization strategies such as teacher-student distillation, where a high-capacity teacher model trained across multiple nodes transfers its knowledge to a more efficient student model for serving.
The resulting models delivered statistically significant engagement gains across Pinterest’s highest-traffic recommendation surfaces, including Homefeed and Related Pins. Faster training also shortened experimentation cycles: what previously required weeks could now be validated in a fraction of the time.
Training Infrastructure
Achieving near-linear scaling required more than algorithmic optimization. The underlying training framework needed significant investment as well.
Migrating from TorchSnapshot to Distributed Checkpoint (DCP). Pinterest’s training infrastructure had long relied on TorchSnapshot for model checkpointing, but upstream development has shifted to PyTorch’s native Distributed Checkpoint (DCP). DCP was essential for multi-node workflows: it supports load-time resharding across different world sizes, enabling flexible scaling patterns like pre-training on 2 nodes and fine-tuning on 1 or 4 nodes from the same checkpoint.
PyTorch upgrades. Over the course of this project, we progressed from PyTorch 2.1 through 2.5 to 2.6 with TorchRec 1.1. None of these upgrades were straightforward. Each involved debugging Triton version mismatches, NCCL build conflicts, and memory profiler crashes that only surfaced on multi-node runs. The lesson: major framework upgrades in production distributed training systems are a project in themselves, and the cost of falling behind compounds quickly.
Takeaways
Across the full optimization journey, improvements compounded at every layer:
- 7.5x scaling factor at 8 nodes (64 GPUs), 93.75% of ideal
- 3.9x scaling factor at 4 nodes, 97.5% of ideal
- 13x multi-node throughput end-to-end at 2 nodes (pre-EFA baseline to fully optimized)
- 5.3x throughput gain at 4 nodes versus EFA baseline
- 6x all-to-all latency reduction (78ms to 13ms)
- 75% NCCL communication reduction with quantized communications
- Statistically significant engagement gains on Homefeed and Related Pins
Three lessons stand out:
You can’t optimize what you don’t measure. Profiling single-node and two-node traces side by side immediately identified distributed embedding communication as the root cause. Every subsequent optimization followed from this diagnosis.
Optimizations compound. No single technique was sufficient. QComms alone reached 1.57x. Reaching 3.9x at 4 nodes and 7.5x at 8 nodes required addressing every layer of the communication stack: payload volume, payload shape, and parallel topology.
Communication dominates at scale. For embedding-heavy recommendation models, compute optimizations alone will never fix multi-node scaling. The communication layer must be addressed directly through quantization, topology, and payload reduction.
From One Project to a Playbook
These lessons have become a repeatable framework: profile the bottleneck, reduce bytes on the wire, reshape payloads to match bandwidth constraints, and redesign topology to keep expensive communication local. That framework is now being applied systematically across the foundation model family, including Homefeed, Related Pins, ads, and multi-node distillation workflows. The larger vision is to use scalability as a lever for more capable models at lower cost, building sustainable, high-value AI infrastructure across Pinterest.
This work bent our scaling curve from broken to near-linear, turning multi-node training into a practical path for larger Pinterest recommendation models.
¹ Pin Foundation Model, ACM RecSys 2025
Acknowledgements
This work reflects joint efforts across multiple teams at Pinterest. We would like to thank Bo Liu and Roger Wang for sponsoring this initiative. We would like to thank Chia-Wei Chen, Charles-A. Francisco, Shunyao Li, and the ML Training team (AI Platform); Chen Yang, Xihuan Zeng, Matthew Poska, Xiangyi Chen, Kousik Rajesh, and Yi-Ping Hsu (ATG); Matthew Lawhon, Abhinav Naikawadi (Homefeed); Hanyu Li (PinRec); Weiguo Ye (Ads); and Jenny Jiang and Eesha Shetty (Related Pins).
[

](https://medium.com/pinterest-engineering?source=post_page---post_publication_info--14d4f59fe6f6---------------------------------------)
[

](https://medium.com/pinterest-engineering?source=post_page---post_publication_info--14d4f59fe6f6---------------------------------------)Last published 12 hours ago
Inventive engineers building the first visual discovery engine, 300 billion ideas and counting.
[

](https://medium.com/@Pinterest_Engineering?source=post_page---post_author_info--14d4f59fe6f6---------------------------------------)
[

](https://medium.com/@Pinterest_Engineering?source=post_page---post_author_info--14d4f59fe6f6---------------------------------------)329 following
https://medium.com/pinterest-engineering | Inventive engineers building the first visual discovery engine https://careers.pinterest.com/
Responses (1)Write a response
[
What are your thoughts?
](https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2Fpinterest-engineering%2Fachieving-near-linear-training-scalability-for-pinterests-foundation-models-14d4f59fe6f6&source=---post_responses--14d4f59fe6f6---------------------respond_sidebar------------------)
Impressive journey! Very insightful read.
[
](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fvote%2Fp%2Fdf631315546e&operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40cw03656%2Fimpressive-journey-very-insightful-read-df631315546e&user=Cindy+Wu&userId=4e9379718756&source=---post_responses--df631315546e----0-----------------respond_sidebar------------------)
1