How a Mock LLM Service Cut $500K in AI Benchmarking Costs, Boosted Developer Productivity
By Sandeep Bansal and Seetharaman Gudetee.
In our Engineering Energizers Q&A series, we spotlight the engineering minds driving innovation across Salesforce. Today’s edition features Sandeep Bansal, a senior software engineer from the AI Cloud Platform Engineering team, whose internal LLM mock service validates performance, reliability, and cost efficiency at scale — supporting production-readiness benchmarks beyond 24,000 requests per minute while significantly reducing LLM model costs during benchmarking.
Explore how the team saved more than $500K annually in token-based costs by replacing live LLM dependencies with a controllable simulation layer, enforced deterministic latency to accelerate performance validation, and enabled rapid scale and failover benchmarking by simulating high-volume traffic and controlled outages without relying on external provider infrastructure.
Our mission is to help engineering teams move faster while reducing the cost and uncertainty of developing and ensuring performance and scale for AI-powered systems. As Salesforce’s AI platform expanded, teams increasingly needed to benchmark performance, scalability, and reliability under production-like conditions. However, running those benchmark directly against live LLM providers introduced cost pressure, variability, and external dependencies that slowed iteration.
Users can add their desired mock response or status code for a given unique key. It also allows to configure static or dynamic latency to simulate variable OpenAI latency and benchmark AI services behavior under various latency conditions.
During a given performance benchmark run, user can pass the unique key header to LLMG request to OpenAI mock response mock. This can be controlled by passing different values of the header and benchmark various user scenarios.
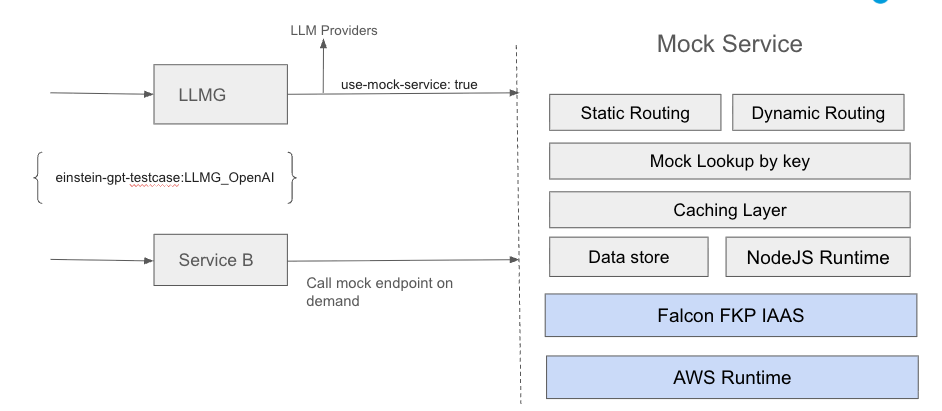
Mock service design and flow.

Mock design JSON.
The mock service removes these constraints, offering a controllable, software-driven way to simulate LLM behavior during development and performance benchmarks. Instead of relying on third-party endpoints, engineers can benchmark internal services, validate regressions, and exercise failure scenarios using consistent, repeatable responses without incurring external usage costs.
By operating the mock service as a shared platform capability, the team enables engineers to focus on improving system behavior rather than managing coordination overhead or reconciling noisy results. The outcome is a faster, more predictable development loop with clearer cost, latency, and reliability signals.
Benchmark AI services against live LLM providers directly linked costs to experimentation. Performance benchmarks, regression suites, and load benchmarks often consumed tokens for hours or days, regardless of actionable results. Consumption-based pricing meant every iteration incurred real spend, even when external variability invalidated results. Increased benchmark executions frequency quickly compounded these costs. Weekly regression runs and repeated validations pushed monthly spending into hundreds of thousands of dollars, creating tension between coverage and budget control.
The mock service altered this dynamic by intercepting load traffic before it reached external providers. Simulating LLM responses internally eliminated token consumption for most development and benchmarking workflows. Based on observed usage, this reduced annual AI spend more than $500k last year. This allowed teams to increase experimentation without financial friction, keeping benchmark decisions driven by engineering rigor rather than cost.
Benchmarking internal AI services requires stable baselines. Live LLM providers, however, exhibit latency fluctuations that directly propagate into performance results. These fluctuations obscure the impact of internal code changes.
Multiple external factors cause these fluctuations, including:
- Shared provider infrastructure serving multiple tenants
- Regional traffic spikes outside platform control
- Provider-side changes that altered response timing without notice
This variability made drawing confident conclusions from benchmarks difficult. It also increased the risk of misinterpreting regressions or improvements.
The mock service addressed this by running within the same network boundary as the AI services under load. It returns deterministic responses with explicitly configured latency. By eliminating external network hops and LLM provider variability, the service produced stable, repeatable timing characteristics. This allowed teams to isolate internal performance changes and evaluate optimizations with confidence.
Latency variability directly impacted development velocity. When benchmark results fluctuated, teams often reran benchmarks multiple times to confirm whether changes were real or merely environmental noise. What should have required a small number of runs frequently doubled. This extended validation cycles and consumed additional compute and performance environment windows. This repetition slowed feedback loops and reduced confidence in the outcomes. Engineers spent more time validating results than iterating on improvements.
The mock service reduced the need for repeated executions by enforcing consistent response behavior. Deterministic latency and predictable outputs produced reliable signals with fewer runs. This shortened time-to-signal and allowed performance validation to keep pace with development rather than becoming a bottleneck.
Validating reliability features, such as failover, requires precise control over failure conditions. However, external providers cannot realistically be taken down on demand. Infrastructure-level simulations often required cross-team coordination and extended lead times, slowing iteration.
The mock service replaced that dependency with software-driven control. This enabled teams to simulate failure conditions, such as:
- 4xx responses for rate limits or authorization failures
- 5xx responses representing provider outages
- Latency spikes to baseline degraded-service behavior
These scenarios can be enabled, modified, or removed dynamically without redeployments or external approvals. As a result, benchmark cycles that previously took days due to coordination now complete within hours. This restores developer autonomy and accelerates iteration on reliability features.
Ahead of major launches, the AI platform must demonstrate readiness for significant traffic spikes. For Agentforce scenarios, this required validating tens of thousands of requests per minute under production-like conditions. This needed to happen without depending on third-party provider readiness or incurring excessive cost.
The mock service enabled large-scale internal traffic generation. This validated scale characteristics, such as:
- Sustained readiness at 16,000 requests per minute
- Burst testing beyond 24,000 requests per minute
- Horizontal scaling using only three mock service instances
Because the service was lightweight and horizontally scalable, it did not become a bottleneck during benchmarks. This allowed the team to focus on internal capacity limits and response handling. This resulted in faster and more confident production-readiness validation under launch pressure.
Validating failover behavior requires exercising worst-case scenarios without causing real downtime. However, triggering genuine outages in external LLM providers is neither practical nor responsible.
The OpenAI mock service was used to simulate real-world OpenAI (OAI) outage scenarios by returning configurable 5xx errors through a special header. This allowed us to force predictable failures in the primary OpenAI path and verify that the LLM Gateway’s circuit breaker transitioned correctly from “closed” to “fallback” mode.
Using this controlled failure injection, we benchmarked how quickly requests were detected as unhealthy, how many retries were attempted, and how efficiently traffic was rerouted to Azure OpenAI (AOAI). This approach let us measure failover latency, success rates, and stability under load without risking live OpenAI traffic, providing high confidence that the OpenAI-to-Azure fallback mechanism would behave correctly during real outages.
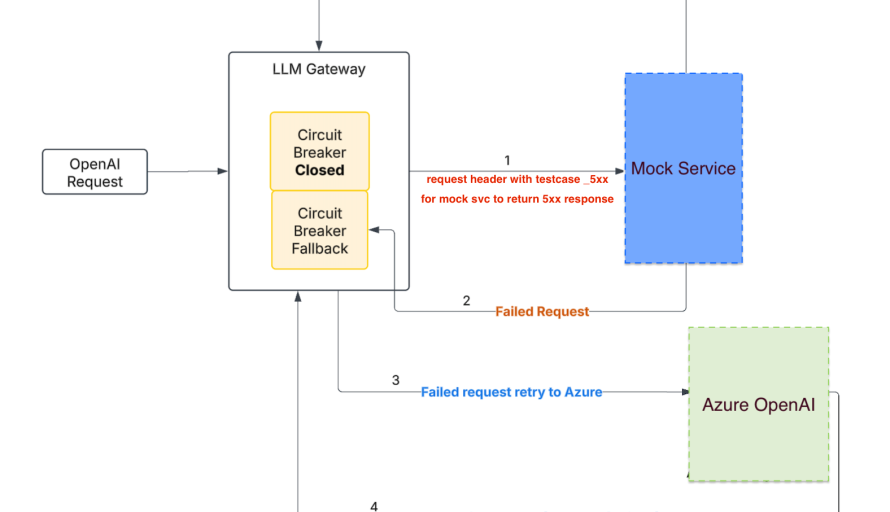
Mock service for OAI/AOAI vendor models.
The mock service enabled controlled failure injection. It simulated provider-specific error responses and latency patterns through configuration headers and parameters. Internal services could then exercise failover logic exactly as they would during a real incident.
Using this approach, the team validated seamless failover from OpenAI to Azure OpenAI ensuring high availability. This happened without disrupting production traffic or relying on real outages. Reliability features could be pushed repeatedly and deterministically. This increased confidence in failover behavior and strengthened the resiliency posture of AI services operating at scale.
The tool is now widely adopted across the Salesforce for AI Cloud feature benchmarking, enabling teams to mock OpenAI behaviors such as latency, responses, failover, image, and other multimodal scenarios — driving greater agility and overall cost savings. Interest in adopting the tool continues to grow across multiple teams.