Efficiently traversing InnoDB B+Trees with the page directory
[This post refers to innodb_ruby version 0.8.8 as of February 3, 2014.]
In On learning InnoDB: A journey to the core, I introduced the innodb_diagrams project to document the InnoDB internals, which provides the diagrams used in this post. Later on in A quick introduction to innodb_ruby I walked through installation and a few quick demos of the innodb_space command-line tool.
The physical structure of InnoDB’s INDEX pages was described in The physical structure of InnoDB index pages, and the logical structure was described in B+Tree index structures in InnoDB, and the physical structure of records was described in The physical structure of records in InnoDB. Now we’ll look in detail at the “page directory” structure that has been seen several times already, but not yet described.
In this post, only COMPACT row format (for Barracuda table format) is considered.
The purpose of the page directory
As described in the posts mentioned above, all records in INDEX pages are linked together in a singly-linked list in ascending order. However, list traversal through a page with potentially several hundred records in it is very expensive: every record’s key must be compared, and this needs to be done at each level of the B+Tree until the record sought is found on a leaf page.
The page directory greatly optimizes this search by providing a fixed-width data structure with direct pointers to 1 of every 4-8 records, in order. Thus, it can be used for a traditional binary search of the records in each page, starting at the mid-point of the directory and progressively pruning the directory by half until only a single entry remains, and then linear-scanning from there. Since the directory is effectively an array, it can be traversed in either ascending or descending order, despite the records being linked in only ascending order.
The physical structure of the page directory
In The physical structure of InnoDB index pages, the page directory’s physical structure was briefly presented:

The structure is actually very simple. The number of slots (the page directory length) is specified in the first field of the INDEX header of the page. The page directory always contains an entry for the infimum and supremum system records (so the minimum size is 2 entries), and may contain 0 or more additional entries, one for each 4-8 system records. A record is said to “own” another record if it represents it in the page directory. Each entry in the page directory “owns” the records between the previous entry in the directory, up to and including itself. The count of records “owned” by each record is stored in the record header that precedes each record.
The page-directory-summary mode of innodb_space can be used to view the page directory contents, in this case for a completely empty table (with the same schema as the 1 million row table used in A quick introduction to innodb_ruby), showing the minimum possible page directory:
$ innodb_space -f t_page_directory.ibd -p 3 page-directory-summary slot offset type owned key 0 99 infimum 1
1 112 supremum 1
If we insert a single record, we can see that it gets owned by the record with a greater key than itself that has an entry in the page directory. In this case, supremum will own the record (as previously discussed, supremum represents a record higher than any possible key in the page):
$ innodb_space -f t_page_directory.ibd -p 3 page-directory-summary slot offset type owned key 0 99 infimum 1
1 112 supremum 2
The infimum record always owns only itself, since no record can have a lower key. The supremum record always owns itself, but has no minimum record ownership. Each additional entry in the page directory should own a minimum of 4 records (itself plus 3 others) and a maximum of 8 records (itself plus 7 others).
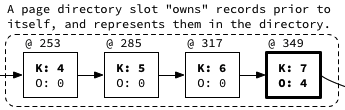
To illustrate, each record with an entry in the page directory (bolded) owns the records immediately prior to it in the singly-linked list (K = Key, O = Number of Records Owned):
Growth of the page directory
Once any page directory slot would exceed 8 records owned, the page directory is rebalanced to distribute the records into 4-record groups. If we insert 6 additional records into the table, supremum will now own a total of 8 records:
$ innodb_space -f t_page_directory.ibd -p 3 page-directory-summary slot offset type owned key 0 99 infimum 1
1 112 supremum 8
The next insert will cause a re-organization:
$ innodb_space -f t_page_directory.ibd -p 3 page-directory-summary slot offset type owned key 0 99 infimum 1
1 191 conventional 4
2 112 supremum 5
Using a record describer with innodb_space can allow you to see the pointed-to record’s key for each entry in the directory, and I will use this describer for all future examples in this post:
$ innodb_space -f t_page_directory.ibd -r ./simple_t_describer.rb -d SimpleTDescriber -p 3 page-directory-summary slot offset type owned key 0 99 infimum 1
1 191 conventional 4 (i=4) 2 112 supremum 5
If a page is completely full, the page directory may look something like this one (now using the 1 million row table itself):
$ innodb_space -f t.ibd -r ./simple_t_describer.rb -d SimpleTDescriber -p 4 page-directory-summary
slot offset type owned key 0 99 infimum 1
1 7297 conventional 5 (i=5) 2 5999 conventional 4 (i=9) 3 1841 conventional 5 (i=14) 4 14623 conventional 8 (i=22) 5 3029 conventional 4 (i=26)73 851 conventional 7 (i=420) 74 3183 conventional 6 (i=426) 75 1577 conventional 5 (i=431) 76 5405 conventional 5 (i=436) 77 455 conventional 5 (i=441) 78 112 supremum 6
A logical view of the page directory
At a logical level, the page directory (and records) for a page with 24 records (with keys from 0 to 23) would look like this:
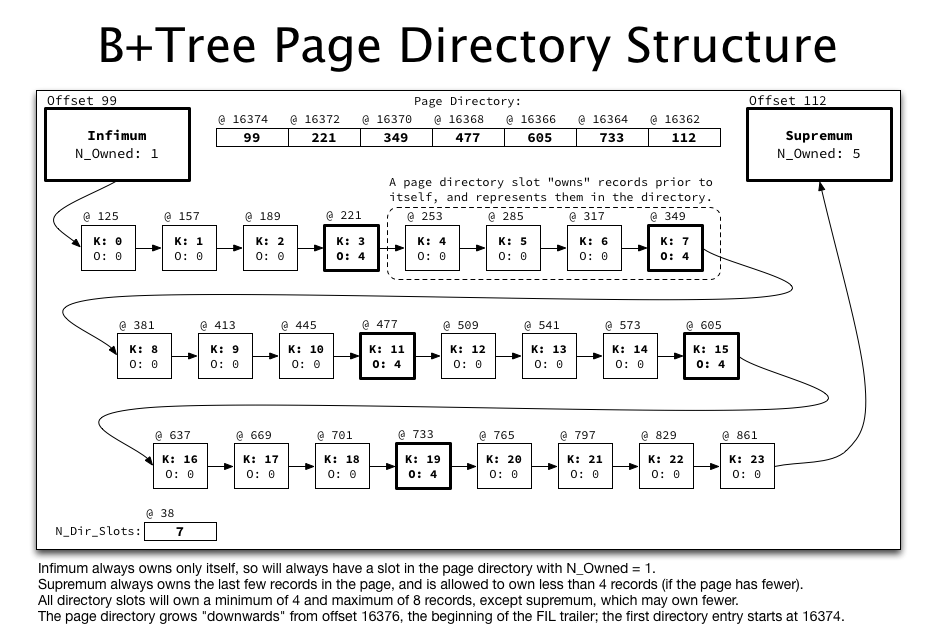
Take note that:
- Records are singly linked from infimum to supremum through all 24 user records, as previously discussed.
- Approximately each 4th record is entered into the page directory, represented in the illustration both by bolding that record and by noting its offset in the page directory array represented at the top of the illustration.
- The page directory is stored “backwards” in the page, so is reversed in this illustration compared to its ordering on disk.
Efficiently searching using the B+Tree and page directory
Without the page directory, a large number of records would need to be compared in order to find the record being sought. Demonstrating actual code is probably the best way to prove how efficient the B+Tree with page directory can be. Using innodb_ruby, it is possible to search an actual InnoDB index, although it doesn’t have a nice command-line interface for doing so yet. Instead, irb, the interactive Ruby shell can be used. (Note that this functionality in innodb_ruby is for illustrative and learning purposes only. It should not be considered for any serious use.)
An interactive shell can be set up similarly to the previous innodb_space commands’ configurations with:
$ irb -r rubygems -r innodb
irb> require "./simple_t_describer.rb" irb> space = Innodb::Space.new("t.ibd") irb> space.record_describer = SimpleTDescriber.new irb> index = space.index(3)
Since we’re interested mostly in exploring here, debug output should be enabled so that the various index traversal operations can be seen:
irb> index.debug = true
The innodb_ruby library provides two methods for searching within the B+Tree:
- index.linear_search(key) — Use only purely linear search on the singly-linked record lists to traverse the B+Tree. This is primarily intended as an inefficient counter-example to binary_search but is also useful to verify various algorithms (such as key comparison).
- index.binary_search(key) — Use binary search on the page directory and linear search as appropriate in order to search efficiently. This is intended to mimic (although not exactly) InnoDB’s algorithm for efficient search.
Note that the key parameter to each method is an array of fields forming the key of the index (either primary key or secondary key).
Linear search
First, we’ll reset the internal statistics (counters) that the index tracks for debugging purposes:
irb> index.reset_stats
Next, initiate a linear search for key “10000” in our 1 million row table:
irb> index.linear_search([10000])
linear_search: root=3, level=2, key=(10000) linear_search_from_cursor: page=3, level=2, start=(i=252) linear_search_from_cursor: page=3, level=2, current=(i=252) linear_search_from_cursor: page=36, level=1, start=(i=252) linear_search_from_cursor: page=36, level=1, current=(i=252) linear_search_from_cursor: page=36, level=1, current=(i=447)
linear_search_from_cursor: page=36, level=1, current=(i=8930) linear_search_from_cursor: page=36, level=1, current=(i=9381) linear_search_from_cursor: page=36, level=1, current=(i=9830) linear_search_from_cursor: page=424, level=0, start=(i=9830) linear_search_from_cursor: page=424, level=0, current=(i=9830) linear_search_from_cursor: page=424, level=0, current=(i=9831)
linear_search_from_cursor: page=424, level=0, current=(i=9998) linear_search_from_cursor: page=424, level=0, current=(i=9999) linear_search_from_cursor: page=424, level=0, current=(i=10000)
I omitted many lines, but the full output can be seen in linear_search.txt. The basic algorithm is:
- Start at the root page of the index.
- Linear search from infimum until finding an individual record with the highest key that does not exceed the search key. If the current page is a leaf page, return the record. If the current page is a non-leaf page, load the child page this record points to, and return to step 2.
We can check the stats that were collected:
irb> pp index.stats
{:linear_search=>1, :linear_search_from_cursor=>3, :linear_search_from_cursor_record_scans=>196, :compare_key=>589, :compare_key_field_comparison=>589}
So this has compared 589 records’ keys in order to find the key we were looking for. Not very efficient at all.
Binary search
Again, reset the stats:
irb> index.reset_stats
This time initiate a binary search using the page directory:
irb> index.binary_search([10000])
binary_search: root=3, level=2, key=(10000) binary_search_by_directory: page=3, level=2, dir.size=1, dir[0]=() linear_search_from_cursor: page=3, level=2, start=(i=252) linear_search_from_cursor: page=3, level=2, current=(i=252) binary_search_by_directory: page=36, level=1, dir.size=166, dir[82]=(i=258175) binary_search_by_directory: page=36, level=1, dir.size=82, dir[40]=(i=122623) binary_search_by_directory: page=36, level=1, dir.size=40, dir[19]=(i=52742) binary_search_by_directory: page=36, level=1, dir.size=19, dir[9]=(i=20930) binary_search_by_directory: page=36, level=1, dir.size=9, dir[4]=(i=8930) binary_search_by_directory: page=36, level=1, dir.size=5, dir[2]=(i=12759) binary_search_by_directory: page=36, level=1, dir.size=2, dir[0]=(i=8930) linear_search_from_cursor: page=36, level=1, start=(i=8930) linear_search_from_cursor: page=36, level=1, current=(i=8930) linear_search_from_cursor: page=36, level=1, current=(i=9381) linear_search_from_cursor: page=36, level=1, current=(i=9830) binary_search_by_directory: page=424, level=0, dir.size=81, dir[40]=(i=10059) binary_search_by_directory: page=424, level=0, dir.size=40, dir[19]=(i=9938) binary_search_by_directory: page=424, level=0, dir.size=21, dir[10]=(i=9997) binary_search_by_directory: page=424, level=0, dir.size=11, dir[5]=(i=10025) binary_search_by_directory: page=424, level=0, dir.size=5, dir[2]=(i=10006) binary_search_by_directory: page=424, level=0, dir.size=2, dir[0]=(i=9997) linear_search_from_cursor: page=424, level=0, start=(i=9997) linear_search_from_cursor: page=424, level=0, current=(i=9997) linear_search_from_cursor: page=424, level=0, current=(i=9998) linear_search_from_cursor: page=424, level=0, current=(i=9999) linear_search_from_cursor: page=424, level=0, current=(i=10000)
That is the complete output. The algorithm here is only subtly different:
- Start at the root page of the index.
- Binary search using the page directory (repeatedly splitting the directory in half based on whether the current record is greater than or less than the search key) until a record is found via the page directory with the highest key that does not exceed the search key.
- Linear search from that record until finding an individual record with the highest key that does not exceed the search key. If the current page is a leaf page, return the record. If the current page is a non-leaf page, load the child page this record points to, and return to step 2.
In the above output you can see the directory size being repeatedly halved (dir.size), and the compared key (dir[x]) getting repeatedly nearer to the search key in the typical binary search pattern. In between binary searches you can see short linear searches once the nearest page directory entry is found (up to a maximum of 8 records).
The stats collected during the search also look a lot different:
irb> pp index.stats
{:binary_search=>1, :binary_search_by_directory=>14, :linear_search_from_cursor=>3, :linear_search_from_cursor_record_scans=>8, :compare_key=>40, :compare_key_field_comparison=>40, :binary_search_by_directory_recurse_left=>8, :binary_search_by_directory_recurse_right=>3, :binary_search_by_directory_linear_search=>2}
Especially notice that the compare_key operation is done only 40 times, compared to 589 times in the linear search. In terms of record comparisons, the binary search was 14x more efficient than linear search (and this will vary quite a bit; depending on the exact value searched to could be 40x better).