Graph Machine Learning at Airbnb
By: Devin Soni

Introduction
Many real-world machine learning problems can be framed as graph problems. On online platforms, users often share assets (e.g. photos) and interact with each other (e.g. messages, bookings, reviews). These connections between users naturally form edges that can be used to create a graph.
However, in many cases, machine learning practitioners do not leverage these connections when building machine learning models, and instead treat nodes (in this case, users) as completely independent entities. While this does simplify things, leaving out information around a node’s connections may reduce model performance by ignoring where this node is in the context of the overall graph.
In this blog post, we will explain the benefits of using graphs for machine learning, and show how leveraging graph information allows us to learn more about our users, in addition to building more contextual representations of them [4]. We will then cover specific graph machine learning methods, such as Graph Convolutional Networks, that are being used at Airbnb to improve upon existing machine learning models.
The motivating use-case for this work is to build machine learning models that protect our community from harm, but many of the points being made and systems being built are quite generic and could be applied to other tasks as well.
Challenges
When building trust & safety machine learning models around entities such as users or listings, we generally begin by reaching for features that directly describe the entity. For example, in the case of users, we may use features such as their location, account age, or number of bookings. However, these simple features do not adequately describe the user in the context of the overall Airbnb platform and their interactions with other users.
Consider the hypothetical scenario in which a new host joins Airbnb. A week into their hosting journey, we likely do not have a lot of information about them other than what they have directly told us. This could include their listing’s location or their phone number. These direct attributes given to us by the host are relatively surface level and do not necessarily help us understand their trustworthiness or reputation.
In this state, it is hard for Airbnb to provide this new host with the best possible experience since we do not know what their usage pattern of the platform will be. Lacking information, we might then make this new host go through a slower onboarding process or request a lot of information up-front. Understanding this user’s relationships to the rest of the platform is data we can leverage to provide them with an improved experience.
An illustration of the usefulness of graphs
While we do not have much direct information about the new host, what we can do is leverage their surroundings to try and learn more. One example of this is the connections that they have to other users.

We can first take a look at their one-hop neighborhood, or in other words, the set of users whom this host has a direct connection with. In this example, we can see that this new host shares a listing photo with an existing, tenured host. We can also see that the new host’s listing is in the same house as listings from three other hosts. With this additional knowledge, we now know more about the new host; they might be working with other hosts who have rooms in the same house. However, we can’t be completely sure how all of the connected hosts relate to each other without looking at more of the graph.

Let’s further expand our view and consider the two-hop neighborhood of the new host. This expands our view to users who are not necessarily directly connected to the new host. In this expanded network we now see that many of the hosts with listings in the location are connected to each other through a shared business name. It now becomes very likely that this new host is part of an existing group of hosts that rent out rooms in the same house, and has not yet updated their profile to reflect this.
Using the power of graphs, we were able to learn about a new host simply by inspecting their connections to other users within Airbnb. This additional knowledge extracted from the graph provides us with an improved glimpse into who our new host is. We are subsequently able to deliver an improved experience to this new host, all without requiring them to provide any more information to Airbnb.
Supplementing our models with graph information is one way to bootstrap our models. Using graphs, we can construct a detailed understanding of our users in scenarios where we have little historical data or observations pertaining to a user. While the semantic information we gain from the graph is often inferred and not directly told to us by the user, it can give us a strong baseline level of knowledge until we have more factual information about a user.
Graph Machine Learning
We have established that we want our machine learning models to be able to ingest graph information. The main challenge is figuring out how best to condense everything a graph can represent into a format that our models can use. Let’s dig into some of the options and explore the solution that we ultimately implemented.
One simple option is to calculate statistics about nodes and use them as numeric features. For example, we can calculate the number of users a user is connected to or how many listing photos they share with other hosts. These metrics are straightforward to calculate and give us a basic sense of the node’s role in the overall structure of the graph. These metrics are valuable but do not leverage the node’s features. As such, simple statistics cannot go beyond representing graph structure.
What we really want is to be able to produce an aggregation of a node’s neighborhood in the graph that captures both the node’s structural role in the graph and its node features. For example, we want to know more than how many users a user is connected to; we also want to understand the type of users they are connected to (e.g. their account tenure, or past booking counts) because that gives us more hints about the original user than simple edge counts.
Graph Convolutional Networks
To capture both graph structure and node features, we can use a type of graph neural network architecture called a graph convolutional network. Graph convolutional networks (GCN) are neural networks that generally take as input a matrix of node features in addition to an adjacency matrix of the graph and outputs a node-level output. This type of network architecture is preferred over simply concatenating pre-computed structural features with node features because it is able to jointly represent the two types of information, likely producing richer embeddings.
Graph convolutional networks consist of multiple layers. A single GCN layer aims to learn a representation of the node that aggregates information from its neighborhood (and in most cases, combines its neighborhood information with its own features). Using the example of our newly created host account, one GCN layer would be the host’s one-hop neighborhood. A second GCN layer representing the host’s two-hop neighborhood can be introduced to capture additional information. Since the output of GCN layer N is used to produce the representations used in GCN layer N+1, adding layers increases the span of the aggregation used to generate node representations [1].
Drawing from the example in the previous section, we would need a GCN with two layers in order to produce a graph embedding that captures the illustrated subgraph. We could go even deeper and expand further to third-order, fourth-order, and so on. In practice, however, a small number of layers (e.g. 2–4) is sufficient, as the connections beyond that point are likely to be very noisy and unlikely to be relevant to the original user.
Model architecture & training
Having decided to use GCNs, we must now consider how complex we want each layers’ method of aggregating neighboring nodes’ features to be. There are a wide variety of aggregation methods which can be used. These include mean pooling, sum pooling, as well as more complex aggregators involving attention mechanisms [5].
When it comes to trust & safety, we often work in adversarial problem domains where frequent model retraining is required due to concept drift. Limiting model complexity, and limiting the number of models that must be retrained is important for reducing maintenance complexity.
One might assume that GCNs with more complex, expressive aggregation functions are always better. This is not necessarily the case. In fact, several papers have shown that in many cases very simple graph convolutional networks are all that is needed for state-of-the-art performance in practical tasks [2, 3]. The Simplified GCN (SGC) architecture showed that we can achieve performance comparable to more complex aggregators using GCN layers that do not have trainable weights [2]. The Scalable Graph Inception Network (SIGN) architecture showed that, in general, we can precompute multiple aggregations without trainable weights, and use them in parallel as inputs into a downstream model [3]. SIGN and SGC are very related; SIGN provides a general framework for precomputing graph aggregations, and SGC provides the most straightforward aggregator to use within the SIGN framework.
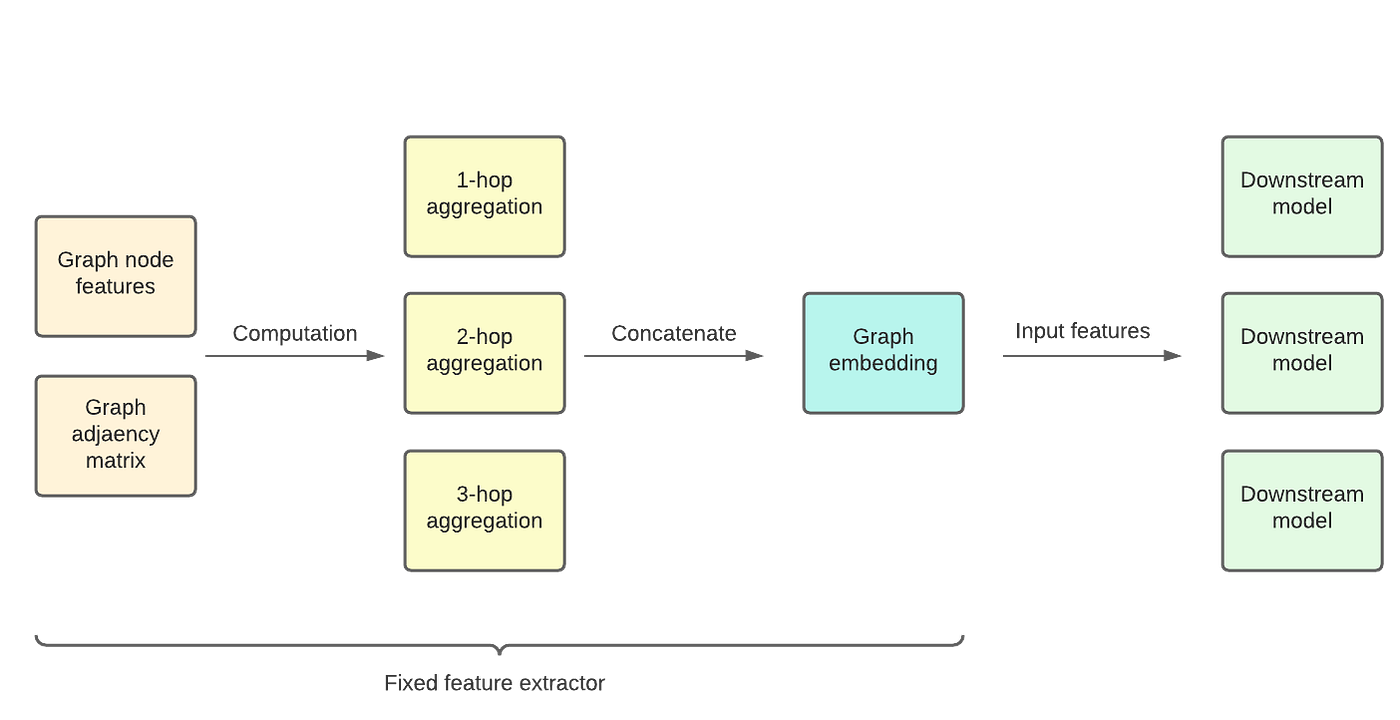
Using SIGN and SGC, the GCN is purely a fixed feature extractor that does not need to learn anything itself — it has no weights that must be tuned during training. In this setting we are able to fundamentally treat the GCN as a fixed mathematical formula applied to its inputs. This aspect is very convenient because we do not need to worry about supervised training or pre-training of the GCN itself.
Model serving
When serving a graph neural network, the main considerations are around freshness of the data and how to obtain the inputs for the model in a production setting. Our primary concern is the trade-offs related to data freshness. The decision between real-time or batch methods has an impact on how up to date the information is.
Real-time methods can provide downstream models with the most up-to-date information. This increased freshness does, however, require more effort to serve the embeddings. In addition, it often relies on a downsampled version of the graph to handle nodes with many edges, such as in the GraphSAGE algorithm [4].
Offline batch methods are able to calculate all node embeddings at once. This provides a distinct advantage over real-time methods by reducing implementation complexity. Unfortunately, the tradeoff does come at a cost. We will not necessarily be able to serve the most recent node embedding as we will only be able to leverage information present in the last run of the pipeline.
Chosen solution
Given all the tradeoffs and our requirements, we ultimately decided to use a periodic offline pipeline which leverages the SIGN method for our initial implementation. The easy maintenance of batch pipelines and relative simplicity of SIGN allows us to optimize for learning instead of performance initially.
Despite the fact that many of our trust & safety models are run online in real-time, we decided to start with an offline graph model. Features are computed using a snapshot of the graph and node features. When fetching these features online, the downstream model simply looks up the previous run’s output from our feature store, rather than having to compute the embedding in real-time. The alternative of a real-time graph embedding solution would involve a significant amount of additional implementation complexity.
Benefits Realized
With the batch pipeline implemented, we can now have access to new information as features in downstream models. Our existing feature sets did not capture this information and it has resulted in significant gains in our models. Components of the embedding are often among the top 10 features in downstream models based on feature importance computed using the SHAP approach.
These positive results encourage further investment in the area of graph embeddings and graph signals, and we plan to explore other types of graphs & graph edges. Investigating how to make our embedding more powerful either through improving the freshness of the data or using other algorithms has become a priority for us based on the success of augmenting our existing models with graph knowledge.
Conclusion
In this blog post, we showed how leveraging graph information can be broadly useful and discussed our approach to implementing graph machine learning. We ultimately decided to use a SIGN architecture that leverages a batch pipeline to calculate graph embeddings. These are subsequently fed into downstream models as features. Many of the new features have led to notable performance gains in the downstream models.
We hope that this information helps others understand how to leverage graph information to improve their models. Our various considerations provide insight into what one must be aware of when deciding to implement a graph machine learning system.
Graph machine learning is an exciting area of research in Airbnb, and this is only the beginning. If this type of work interests you, check out some of our related positions:
Senior Machine Learning Engineer
Senior Software Engineer, Trust
Acknowledgments
This project couldn’t have been done without the great work of many people and teams. We would like to thank:
- Owen Sconzo for working on this project and reviewing all of the code.
- The Trust Foundational Modeling team for providing the foundational data for graph modeling.
- Members of the Fraud & Abuse Working Group for supporting this project, reviewing this blog post, and providing suggestions.
References
[1] Semi-Supervised Classification with Graph Convolutional Networks.
[2] Simplifying Graph Convolutional Networks
[3] SIGN: Scalable Inception Graph Neural Networks
[4] Inductive Representation Learning on Large Graphs
****************
All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.