Using Client-Side Map Data to Improve Real-Time Positioning
By Karina Goot, Tony Zhang, Burak Bostancioglu, Bobby Sudekum, Erik Kamp
Introduction
GPS signals are notoriously noisy and unreliable (figure 1). One of the primary challenges for the Mapping team at Lyft is to translate the noisy GPS signal from our driver and rider devices into accurate location tracking on the map. This helps power rider and driver matching, dispatch decisions, accurate ETA predictions, and much more! We call this process map matching.

Figure 1: example of noisy location data in a dense urban area and improvements after map matching
Map data helps the map matching process because it can reduce the space of locations to just the roads. For this reason, historically, we ran our map matching algorithms on the server-side to utilize the underlying map data.
For the past year, we have been building out an on-device localization system. Having localization capabilities on the client allows us to have more accurate sensor readings, reduce latency, localize drivers when they lose cell reception, and unlock new product use cases across the Lyft platform.
Unlike server-side localization systems, client localization is extremely constrained in both memory and latency requirements. As a result, we cannot efficiently utilize map data without impacting device memory (storing too much data will make the device run out of memory) or over-the-network cost (downloading maps while on cellular data is expensive).
These constraints drove us to design a system that supports map data in the client to unlock the location tracking accuracy gains of map data on-device without introducing unnecessary memory pressure.
Why is map data useful to have on-client?
It helps improve navigation:
- By understanding the road network and its features, we can improve our rerouting and off-route detection algorithms.
- Cell network availability is not guaranteed. With map data available on-device, we can localize and reroute drivers when they are offline (for example, in tunnels or rural areas).
It helps improve location tracking:
- Map matching on-device improves the freshness of localization models.
- Moving high-cost computation from server to client simplifies server-side architecture, reduces hosting costs, and lowers server-to-client latency.
- Direct access to high-frequency sensor data improves localization quality.
It helps build safety features for our drivers:
- Notifying drivers of unauthorized drop-off/pick-up areas based on curb features.
- Displaying speed limits.
- Showing map elements like traffic lights and stop signs.
Designing the system
We broke the project down into three main components.
- Lightweight map data generation
- Client platform networking layer on iOS and Android
- C++ core library
Lightweight map data generation
In order to figure out the map data format, generation, and serving, we divided the entire LyftMap into small chunks of S2Cells built on top of the S2Geometry library. The basic unit of LyftMap data is a MapElement which stores two types of data:
- Road metadata to build a road network graph.
- Segment sequences to infer turn restrictions and avoid illegal turns.
Each S2Cell is a compilation of MapElements for a region, where each cell has a unique numeric id. We partitioned the map into cells that span roughly 1x1km sections (figure 2).
Figure 2: S2 level 13 cells over the San Francisco region
When the client tries to download map data from the server, it will specify the cell_id + map_version. The server will return the map data serialized as S2CellElements.
We download the cells based on the current user location and dynamically build a road network graph in memory. With this design, we have a local graph built on the client providing the same core functionalities as a server-side graph.
Client platform networking layer (iOS and Android)
Next, we stood up a backend service, MapAttributes, that reads map elements data from DynamoDB based on an S2 geospatial index. GetElementesByCellID fetches serialized map elements from Dynamo, deserializes them, and filters on the requested element types. Finally, it converts them into S2CellElements objects to construct a response.
To improve reliability, reduce latency, and improve MapAttributes server hosting costs, we used a CloudFront CDN to cache the MapAttributes response. CloudFront will return the results from the edge server on a cache hit without calling the MapAttributes service. On a cache miss, Cloudfront forwards the request to MapAttributes via Envoy, and the response gets cached for future requests.
To keep the memory footprint constant, we only load cells near the current location. To compensate for data loading latency, we keep a buffer of nearby cells to have enough map data around the current location. As illustrated in figure 4, we find the corresponding cell for a given raw location, L, and call it S0. Next, we fetch all the neighboring cells of S0 and call them S1. Similarly, we compute the neighboring cells of _S1_s and call them S2. This way, for each location update, we generate 13 surrounding cells. As the user location changes, we recompute the list of cells.
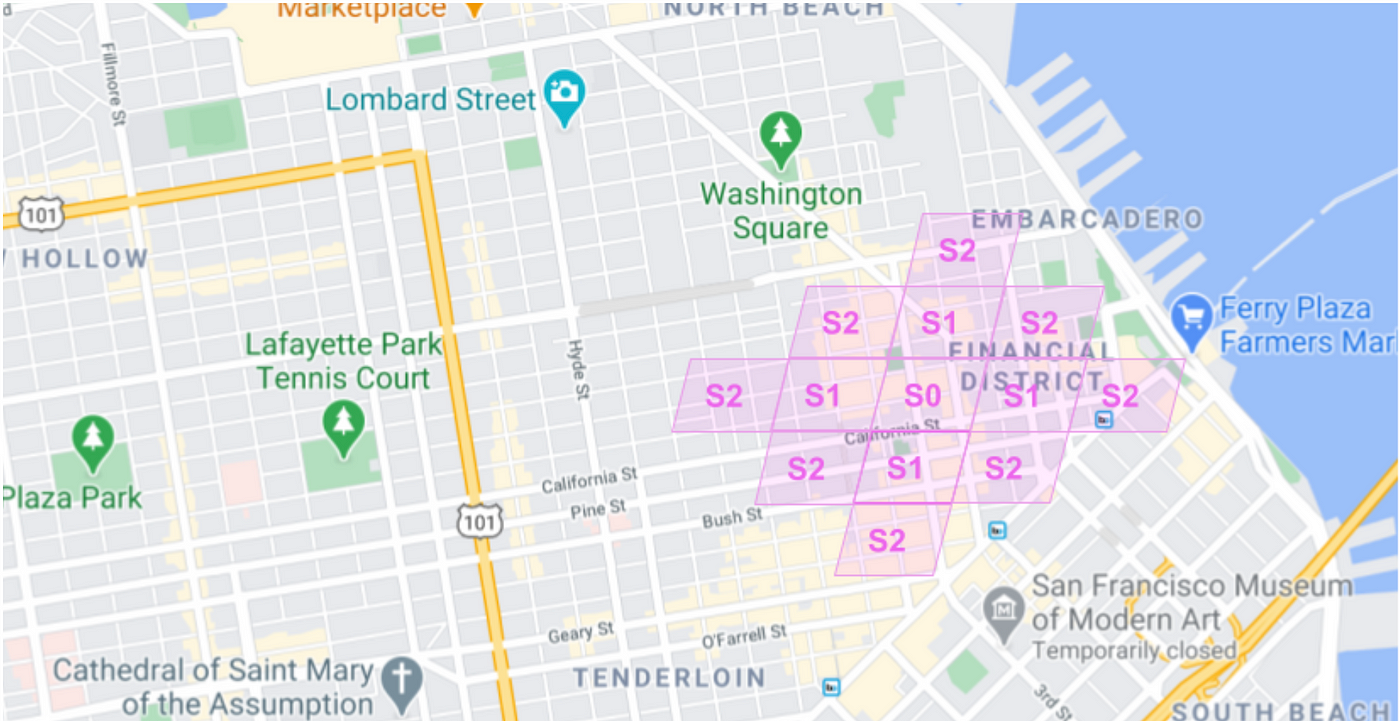
Figure 4: Computing level 0, 1, and 2 neighboring cells
Core library functionality
Once the client fetches the desired map cells from the server, it passes this information through an interface layer to a C++ localization library (figure 5).
We track the map data elements in a MapDataManager object, and after generating all 13 map data cells, we trigger a road network graph computation. This process happens async from the location updates that occur when new GPS readings come in from the device.
When the MapDataManager completes creating a RoadNetworkGraph, we pass a shared pointer to our LocationTracker, enabling the system to take advantage of various Map-Based Models for localization.
Figure 5: High-level overview of the Localization Library
With this design, as the user moves around the physical world, we can dynamically generate new RoadNetworkGraphs of their surroundings and update our LocationTracker when the next graph object is ready (figure 6).
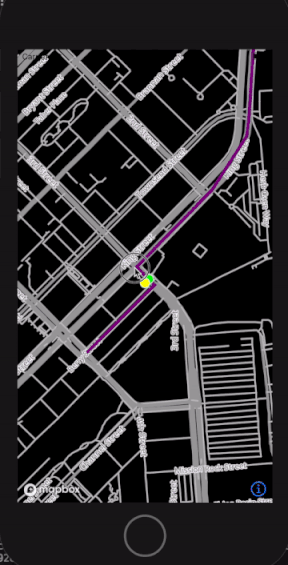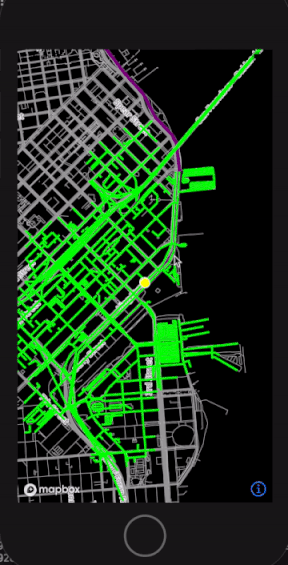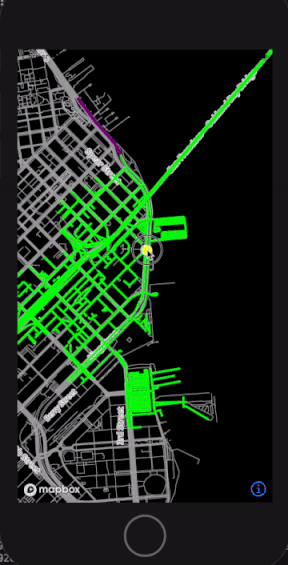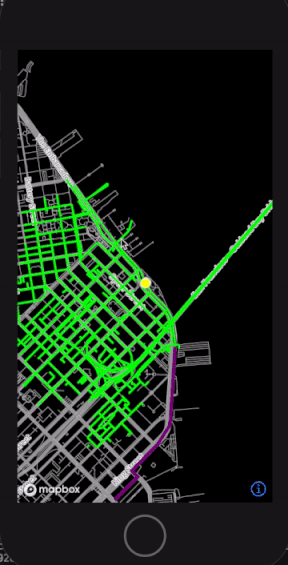
Figure 6: Prototype visualization of map data cells dynamically loading as user locations move
Lyft drivers generally operate in a single service area, and their locality is highly concentrated, so duplicate downloads of the same data are likely. Repeat downloads will lead to high over-the-network data usage for our drivers.
To solve this problem, we added an in-memory SQLite caching layer directly in C++. SQLite was our preferred database choice because of its simplicity and native support on client platforms.
This secondary cache allows us to store the unique highest locality data for each driver directly on-device. By persisting map data on disk, we can store data across sessions, so we only have to refresh the cache when the underlying map data changes.
Based on data analysis of driving patterns, we determined that with less than roughly 15MB of on-device data, we can achieve a high cache hit rate for the vast majority of Lyft Drivers (figure 7).
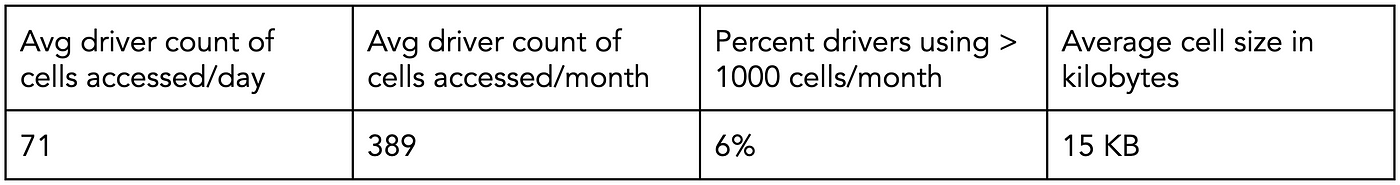
Figure 7: Driver cell usage stats
Analyzing Results
Once we finalized the initial prototypes and design plans, it was time to validate everything was working as expected.
We determined the best metric for success would be to track how often mobile clients have map data cells on-device. With the current release, we achieved map data availability metrics showing >99% availability among drivers in the experiment group.
We also monitored the performance of the map data system to ensure it only uses a reasonable amount of computation power. In experimentation, we achieved sub 10ms latency for the p99 computation time of our map matching models.
Next, we investigated how client map data models affect quality. Figure 8 shows a local map simulation, where the blue dots represent raw locations roughly one second apart. The red dots reflect the map-snapped locations, centering over the road segment as expected.
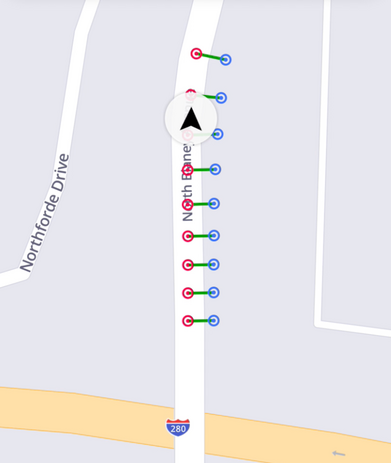
Figure 8: Raw and map matched locations
We also compared different localization strategies. In figure 9, we plotted Kalman filtered locations in yellow against map-snapped locations in pink. Even with a basic snapping model without additional heuristics, the pink locations are a much better representation of where the driver is on the road.
Figure 9: Kalman filtered locations and map snapped locations
Finally, we investigated the impact of the SQLite cache on the download rate of map data. In the chart in figure 10, we ranked drivers by the amount of over-the-network data they were downloading with and without the cache. Seeing the order of magnitude reduction in downloads helped us validate the database is working.
Figure 10: Over the network download rate for users with and without the SQLite cache
Conclusion
The Map Data in the Client project is a foundational investment for our location tracking capabilities at Lyft. With this project complete, we managed to successfully download Lyft map data, build in-memory road network graphs, compute map matching models and ingest the locations back to the server — all in the mobile client!
Looking forward, we are excited to develop higher accuracy on-device localization models, implement offline routing and rerouting capabilities, and introduce new features that will make driver navigation and wayfinding in the physical world safer and more reliable.
Acknowledgments
Huge thanks to the entire Mapping Team at Lyft for helping shepherd this effort into production! Especially to Rex McArthur, Ben Low, and Phoenix Li for collaborating closely on the integration points.
As always, we are hiring! If you’re passionate about developing the future of mapping at Lyft, join our team.