One AI, streaming videos for all
By 2022, videos will make up more than 82 percent of all consumer internet traffic, 15 times higher than it was in 2017, according to a survey at Cisco. People watch videos on home Wi-Fi, on their cellphones, on a train, in cities, in mountains, after dinner when the whole family is using the internet, and at 3 AM when the kids are asleep. The variety of network conditions poses unprecedented challenges in online video streaming.
As of December 31, 2020, the Vimeo video player was powering ~100 billion views a month, with 297,000 new videos uploaded to our platform each day. High-resolution, seamless playback experiences are critical to the success of our creators. Among our numerous efforts to optimize the viewing experience, from the assignment of storage tiers and CDN selection and delivery to improving the efficiency of the algorithms that constitute our super-lightweight player, designing a good streaming algorithm is one of the most important.
Adaptive bitrate streaming, or ABR, is the modern epitome of seamless viewing. In old progressive streaming, the CDN delivers the entire video in one package and one transcode to the viewer. In an adaptive streaming session, a video is divided into short segments, which for most commercial players is either 3 or 6 seconds long. Each segment has different quality transcodes to select from, including 360p, 720p, 1080p, and so on. For each segment, an ABR algorithm selects the most suitable quality by gauging the current bandwidth and throughput (see Figure 1).
Figure 1: Adaptive bitrate streaming. Each film clip represents a segment. During playback, an ABR algorithm can switch up or down qualities depending on the internet condition to ensure a seamless viewing experience. In this figure, the quality is switched down from 1440p to 720p.
Considering challenges
To optimize the QoE — the quality of experience — for our viewers, the goals for the ABR algorithm are conflicting: we’d like to stream the highest quality possible, but downloading a segment size exceeding the throughput can cause stalling. When the bandwidth changes, we want to adapt smartly by switching qualities up and down, but unnecessary quality switches also impact the QoE. The algorithm needs to keep in mind all the general QoE standards without excessively preferring one over the other.
At Vimeo, we define a good playback experience as:
- Fast video startup. A general rule of thumb is if a page or video takes more than 3 seconds to load, more than 50 percent of visits are abandoned.
- High quality at startup. And throughout the video.
- No stalling. No stopped frames or spinning circles.
- Minimal quality switches. Seamlessness is the key.
To hit these targets, we developed a reinforcement learning algorithm, Mimir, a one-size-fits-all ABR solution for Vimeo. This algorithm adapts differently to network conditions around the globe and network fluctuations throughout the day.
We used A3C, or Asynchronous Actor-Critic Agents, as our learning framework, where multiple agents work in independent, asynchronous environments, collect data, and update the central agent; see “Asynchronous Methods for Deep Reinforcement Learning” by Volodymyr Mnih, et. al. for more details. We extract data from millions of real playback sessions on Vimeo and use them to simulate playback in an offline player, where the environment is programmed to model the conditions that the Vimeo player might encounter in the wild. In training, the environment simulates a playback session and generates a snapshot of its current state, including observed throughput history, past segment sizes, download times, current buffer size, and so on (see Figure 2). The state is sent to an agent, which is formulated as an actor network. The actor then takes an action, such as choosing a quality for the current segment. The environment executes the action and records the reward r, a summation of all the QoE metrics. When a session ends, this action has a cumulated reward R, measuring how good the action is in the long term. A critic network evaluates the R by comparing it to the average reward v for this state. At the end of each session, the actions and rewards are sent back to a central agent. The central agent performs gradient descent, updates its own parameters, and then copies itself to the actors. The loop repeats.
Figure 2: The training loop.
We found four design decisions to be crucial to Mimir’s success:
- Modeling the reward correctly
- Providing the agent substantial information for modeling download time
- Programming the environment to be as close to the real player as possible
- Balanced training data
Simulating playback
When a reinforcement learning agent is trained in a simulated environment, the agent often suffers from training-serving skew when deployed in the real world. The Vimeo player consists of a set of highly specified rules to download and play video packages under the constraint of a small buffer. For example, a download timeout error happens when the download time of one segment exceeds 8 seconds. Upon encountering this error, the player throws out the data already downloaded for this segment and re-requests the entire segment at a smaller quality. In training, the agent needs to learn that when download time exceeds 8 seconds, the download fails, by having this error reflected in the reward.
The reward r informs the agents of the viewer’s perceived QoE. Combining what we saw in recent works, we formulated it as:
r = αQ( ) + βR( ) + γS( ) + (custom player rules)
where Q( ) is a positive reward linear to segment quality (240p, 360p, 720p, and so on); R( ) is the length of rebuffering in seconds; and S( ) is the step size of quality switch (for example, if switching from 1080p to 720p, the step size is 720 − 1080 = −360). R( ) and S( ) are penalties and are hence always negative, and α, β, and γ are weighting parameters. In practice, the viewer’s perceived quality isn’t necessarily linear to the resolution of the video, and a linear Q( ) is a simplified assumption. As transcoding technology evolves, some lower-quality transcodes can look very good by deploying intelligent algorithms that take visual perception and attention into account, another important topic at Vimeo! While some users might prefer lower quality with absolute zero buffering, others might be willing to sit through some buffers to view a higher quality. The important thing is that Mimir behaves however you write the cost function, which makes it super easy to change these rules. (For more information on how a business model and user portraits impact the definition of QoE, check out Steve Robertson’s Demuxed 2018 talk.)
Custom player rules are player-dependent, arbitrary rewards or penalties. In the Vimeo player, they are:
- Video startup reward. If this segment is the first few segments of the video, reward higher quality.
- Download timeout penalty. If there is a download timeout error, this segment is practically not downloaded, so this penalty cancels out the Q( ) and also penalizes the excessive CDN cost.
In traditional ABR algorithms, these rules are difficult to insert into the existing optimization logic. These rules are where a reinforcement learning algorithm shines! In simulated tests, Mimir outperforms the baseline by 26 ±3 percent in terms of total reward gained and reduces rebuffering by 69 percent compared to the baseline, a throughput-based algorithm.
In the test playback session graphed in Figure 3, the throughput (the purple line) fluctuates rapidly between 1 to 4 Mbps. Rapid fluctuation like this occurs frequently at peak hours. Mimir consistently streams 720p. It runs into two timeout events as the blue line dips, at roughly 67 seconds and 162 seconds, but quickly adjusts quality down to 240p for one segment to recover the buffer. Hence there is no rebuffering error. In comparison, the baseline, a throughput-based algorithm, has trouble streaming at a consistent high quality and runs into one rebuffering error when it mistakenly switches to a higher quality. Notice how the baseline algorithm experiences two timeout errors in a row. After the first timeout error, it is incapable of switching down quality without explicit programming.
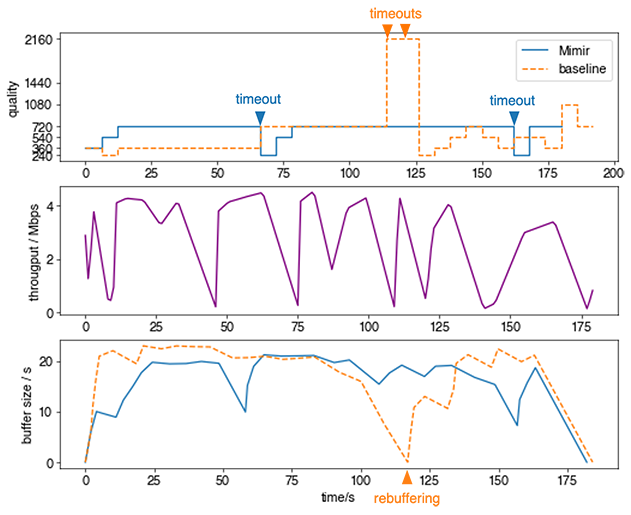
Figure 3: Test playback session.
In the second playback session graphed in Figure 4, the throughput fluctuates less but suffers from one big dip later on. Mimir consistently streams 540p, and then 720p after the buffer builds up. It also streams a higher quality than the baseline algorithm at video startup. When throughput dips at roughly 140 seconds, Mimir switches down quality to keep the buffer size above zero. In math, Mimir is trying to maximize the time it streams high quality (720p). For users who don’t like a rapid dip and recovery in quality, it can also be trained to stream 540p throughout this session.
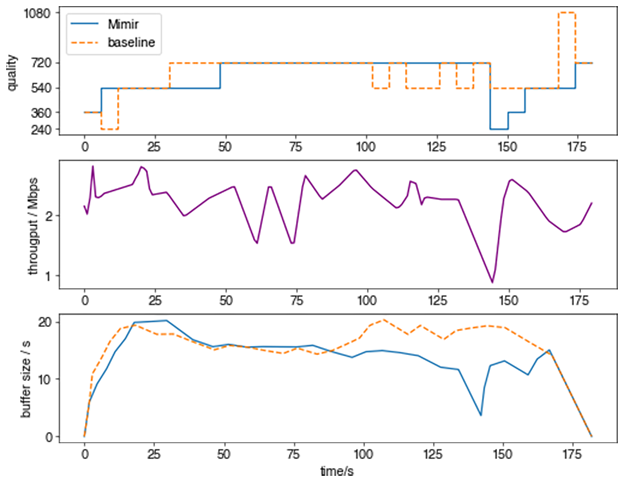
Figure 4: Second test playback session.
Figure 5 shows a plot of Mimir’s action distribution after a download timeout in a session steadily streaming 1080p at ~16 Mbps. Mimir doesn’t know the exact current throughput so decides on the next quality depending on the remaining buffer size in seconds. If there’s 15 seconds left in the buffer (the bluest line with the 15s label), Mimir continues to choose 1080p at ~45 percent probability. If there’s 6 or 7 seconds in the buffer, Mimir reduces to 720p. But if there’s only a few seconds left, Mimir switches down quality to 240p.
Figure 5***:*** Mimir’s action probability at different remaining buffer lengths.
Modeling download time
The key to the success of Mimir lies in predicting future throughput and download time. The more information Mimir has about the current session — cell or cable, cell plan data type (4G, 5G, and so on), rural or urban, time of the day or week, and more — the better it is at estimating throughput. As previously discussed, throughput estimation is hard at video startup. To provide a good estimate of throughput even before the session starts, we store a hash table of 20,000 geolocations in the world along with their mean, standard deviation, and 95-percentile throughput as seen on Vimeo (see Figure 6). The model takes a string as input and looks up the throughputs at runtime. This table is updated periodically to keep up with the latest networking changes globally. For areas where there is little or no data, the model loads an empty string as its input and falls back to default behavior. For example, the mean and 95-percentile throughput in New York, USA are respectively 324 percent and 436 percent the mean and 95-percentile throughput of Abbotsford, USA. With that in mind, Mimir starts out with a less aggressive strategy in Abbotsford.
Figure 6: Mean throughput by city on the Vimeo player (August–November 2020). The missing areas have too few playback sessions for us to get a good estimate of throughput. In general, high-density urban centers in developed countries have an average throughput in excess of 20 Mbps (think 4G), enough to stream 1080p. In more rural areas, even in the same countries, the throughput can drop to a few megabytes per second. Remember that Vimeo’s streaming speed depends on our CDNs among other factors, so this graph is not a reflection of the average local bandwidth.
When an HTTP request is sent for the video segment, the total download time, dT, consists of two parts: time-to-first-byte (TTFB), plus the download time, dt, which is defined as segment size divided by throughput. TTFB depends on the user’s network conditions as well as whether the segment has recently been cached at the CDN. Notably, TTFB is independent of segment size. It’s important for the model to separate TTFB from download time.
Suppose we only provide the model with total download time, dT, as input. The model will likely assume:
dT = size / throughput + error
Whereas, if we provide both TTFB and download time dt as input:
dT = TTFB + dt = TTFB + size / throughput + error
The first model causes large biases in throughput estimation, when average TTFB is far larger than dt, like when this video isn’t cached at the CDN. Say that for a certain segment TTFB equals 60 ms and dt equals 30 ms with a segment size of 500 KB. Throughput estimates from these two models would be, respectively:
throughput = size / dt = 500 / 30 = 16.67 KB/ms
throughput = size / dT = 500 / (600 + 30) = 0.79 KB/ms
The first is the actual throughput, and the second is what the agent thinks, if it wasn’t given separate TTFB and download time. One is up to 4K in quality, and the other one is 540p! So it’s important to separate TTFB and download time in simulation and in deployment.
In practice, we collect hundreds of thousands of throughput and TTFB traces. We start up each playback session in the environment with a randomly sampled TTFB trace and throughput trace.
Balancing training data
Balanced data! What a classic and yet eternal topic in machine learning. We started out our training journey with a randomly sampled throughput dataset of 100,000 real streaming sessions and a video dataset of 30,000 videos from the Vimeo platform. The resulting Mimir model could handle commonly seen throughput ranges but had trouble switching up to high quality (2K, 4K) or handling low-throughput sessions (slower than 240p, meaning eternal rebuffering). This brought to our attention that Mimir needs to be trained to handle all kinds of throughput distribution as well as equally every single transcode.
Adding 2K and 4K videos to the video dataset and adding low-throughput data helped resolve these issues. Our final throughput sampling strategy collected an equal number of sessions from the buckets of 0.4–0.7 Mbps, 0.7–2 Mbps, 2–3 Mbps, 3–4 Mbpss, 4–7 Mbps, 7–20 Mbps, and 20+ Mbps. These ranges correspond to 240p, 360p, 540p, 720p, 1080p, 1440p, and 2160p respectively, which are the beautiful transcodes we currently use on Vimeo.
And with that, I leave you (for now)
I have much more to tell you about lessons learned in debugging Mimir in online A/B tests and deploying it in the wild, but I’ll save that for a future post.
Check out Jobs at Vimeo for our current offerings.