The Evolution from RAG to Agentic RAG to Agent Memory
I have been learning about memory in AI agents, and found myself overwhelmed by all the new terms. It started with short-term and long-term memory. Then it became even more confusing with procedural, episodic, and semantic memory. But wait. Semantic memory reminded me of a familiar concept: Retrieval-Augmented Generation (RAG).
Could memory in agents be the logical next step after vanilla RAG evolved to agentic RAG? At its core, memory in agents is about transferring information into and out of the large language model (LLM)‘s context window. Whether you call this information ’memories’ or ‘facts’ is secondary to this abstraction.
This blog is an introduction to memory in AI agents from a different angle than you might see in other blogs. We will not talk about short-term and long-term memory (yet), but gradually evolve the naive RAG concept to agentic RAG and to memory in AI agents. (Note that this is a simplified mental model. The entire topic of agent memory is more complex under the hood and involves things like memory management systems.)
The concept of Retrieval-Augmented Generation (RAG) was introduced in 2020 (Lewis et al.) and gained popularity around 2023. It was the first concept to give a stateless LLM access to past conversations and knowledge it hadn’t seen and stored in its model weights during training (parametric knowledge).
The core idea of the naive RAG workflow is straightforward, as shown in the image below:
- Offline indexing stage: Store additional information in an external knowledge source (e.g., vector database)
- Query stage: Use the user’s query to retrieve related context from the external knowledge source. Feed the retrieved context, along with the user query, to the LLM to obtain a response grounded in the additional information.

Naive RAG workflow
The following pseudo-code illustrates the naive RAG workflow:
# Stage 1: Offline ingestion
def store_documents(documents):
for doc in documents:
embedding = embed(doc)
database.store(doc, embedding)
# Stage 2: Online Retrieval + Generation
def search(query):
query_embedding = embed(query)
results = database.similarity_search(query_embedding, top_k=5)
return results
def answer_question(question):
# Always retrieve first, then generate
context = search(question)
prompt = f"Context: {context}\nQuestion: {question}\nAnswer:"
response = llm.generate(prompt)
return response
Although the naive RAG approach was effective at reducing hallucinations for simple use cases, it has a key limitation: It is a one-shot solution.
- Additional information is often retrieved from an external knowledge source without reviewing whether it is even necessary.
- Information is retrieved once, regardless of whether the retrieved information is relevant or correct.
- There’s only one external knowledge source for all additional information.
These limitations mean that for more complex use cases, the LLM can still hallucinate if the retrieved context is irrelevant to the user query or even wrong.
Agentic RAG addresses many aspects of the limitations of naive RAG: It defines the retrieval step as a tool that the agent can use. This change enables the agent first to determine whether additional information is needed, decide which tool to use for retrieval (e.g., a database with proprietary data vs. a web search), and assess whether the retrieved information is relevant to the user query.
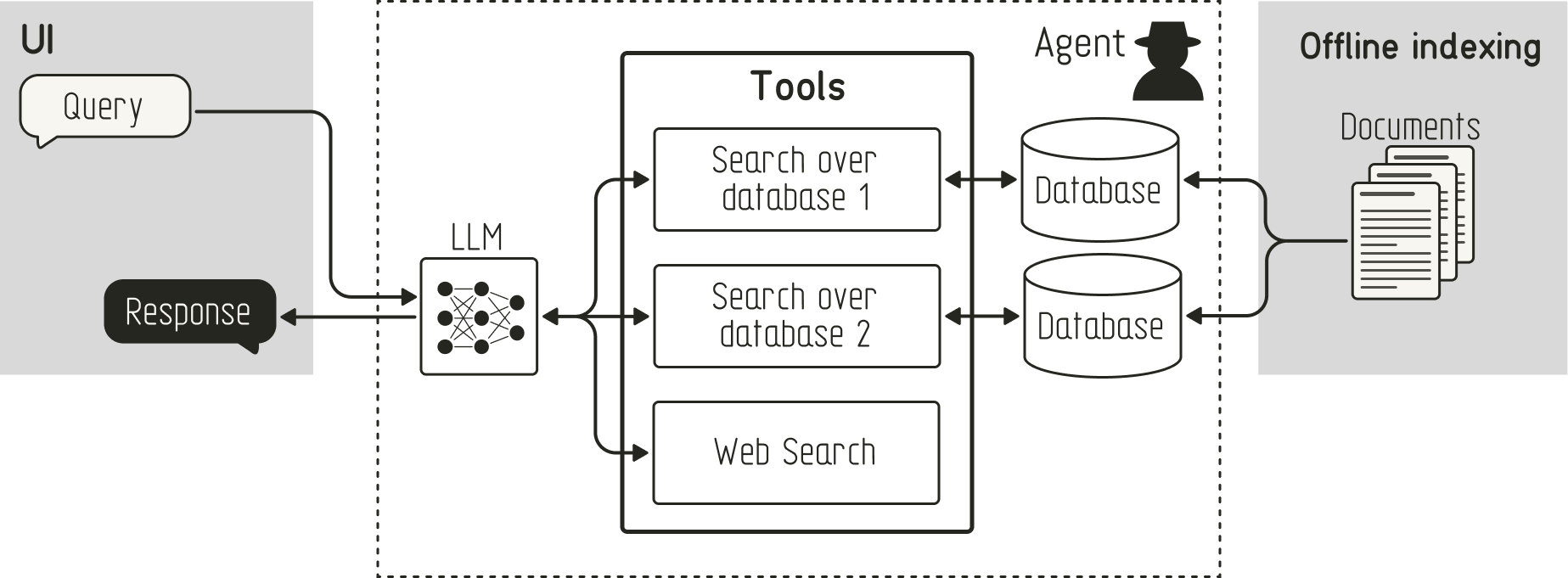
Agentic RAG workflow
The following pseudo-code illustrates how an agent can call a SearchTool during an agentic RAG workflow:
class SearchTool:
def __init__(self, database):
self.database = database
def search(self, query):
query_embedding = embed(query)
results = self.database.similarity_search(query_embedding, top_k=5)
return results
def agent_loop(question):
messages = [{"role": "user", "content": question}]
while True:
response = llm.generate(
messages,
tools=[SearchTool]
)
if response.tool_calls:
for tool_call in response.tool_calls:
if tool_call.name == "search":
results = search_tool.search(tool_call.arguments["query"])
messages.append({
"role": "tool",
"content": f"Search results: {results}"
})
else:
return response.content
One similarity between naive and agentic RAG is that information is stored in the database offline, rather than during inference. This means that data is only retrieved by the agent but not written, modified, or deleted during inference. This limitation means that both naive and agentic RAG systems are not able to learn and improve from past interactions (by default).
Agent memory overcomes this limitation of naive and agentic RAG by introducing a memory management concept. This allows the agent to learn from past interactions and enhance the user experience through a more personalized approach.
The concept of agent memory builds on the fundamental principles of agentic RAG. It also uses tools to retrieve information from an external knowledge source (memory). But in contrast to agentic RAG, agent memory also uses tools to write to an external knowledge source, as shown below:
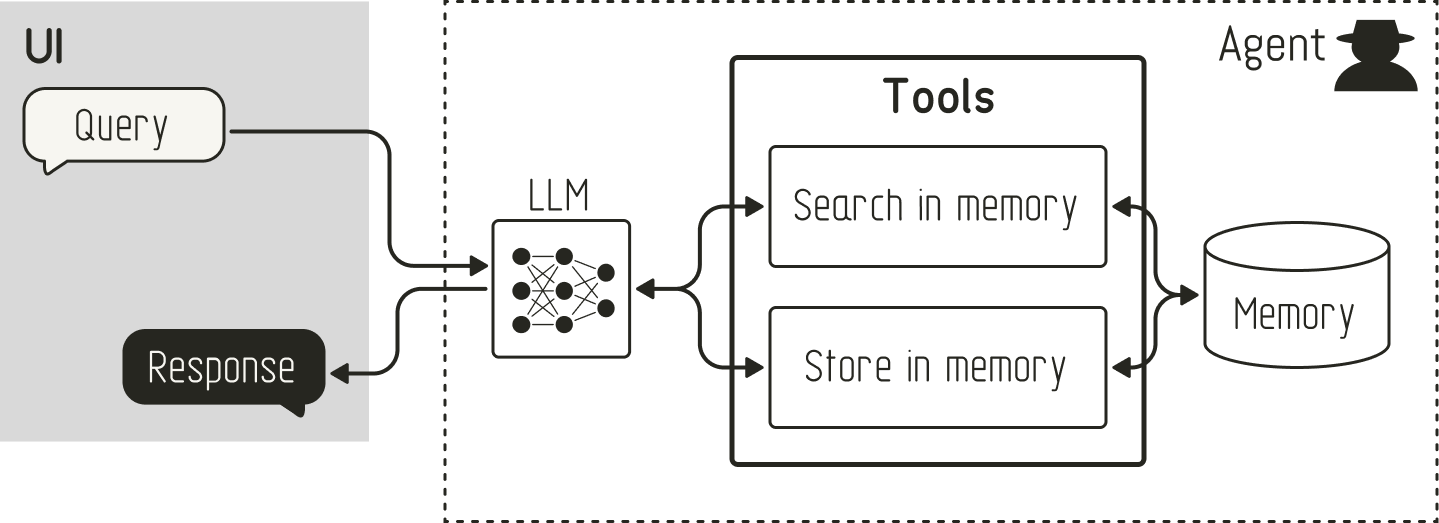
Agentic Memory
This allows the agent not only to recall from memory but also to “remember” information. In its simplest form, you can store the raw conversation history in a collection after an interaction. Then, the agent can search over past conversations to find relevant information. If you want to extend this, you can prompt the memory management system to create a summary of the conversation to store for future reference. Furthermore, you can also have the agent notice important information during a conversation (e.g., the user mentions a preference for emojis or mentions their birthday) and create a memory based on this event.
The following pseudo code illustrates how the concept of agent memory extends the idea of agentic RAG with a WriteTool the agent can use to store information:
class SearchTool:
def __init__(self, database):
self.database = database
def search(self, query):
results = self.database.search(query)
return results
# For simplicity, we only define a write tool here. You could also have tools for updating, deleting, or consolidating, etc.
class WriteTool:
def __init__(self, database):
self.database = database
def store(self, information):
self.database.store(information)
def agent_loop(question, ):
messages = [{"role": "user", "content": question}]
while True:
response = llm.generate(
messages,
tools=[SearchTool, WriteTool]
)
if response.tool_calls:
for tool_call in response.tool_calls:
if tool_call.name == "search":
results = search_tool.search(tool_call.arguments["query"])
messages.append({
"role": "tool",
"content": results"
})
elif tool_call.name == "store":
result = write_tool.store(
tool_call.arguments["information"]
)
messages.append({
"role": "tool",
"content": result
})
else:
return response.content
As stated at the beginning of this blog, this comparison of memory in AI agents is only a simplified mental model. It helped me to put it into perspective of something I was already familiar with. But to avoid making the entire topic of memory in AI agents seem like it’s only an extension of agentic RAG with write operations, I want to highlight some limitations of this simplification:
The above illustration of memory in AI agents is simplified for clarity. It only shows a single source of memory. However, in practice, you could use multiple sources for different types of memory: You could use separate data collections for
- “procedural” (e.g., “use emojis when engaging with user”),
- “episodic” (e.g., “user talked about planning a trip on Oct 30”), and
- “semantic memory” (e.g., “The Eiffel Tower is 330 meters tall”),
as discussed in the CoALA paper. Additionally, you could have a separate data collection for the raw conversation history.
Another simplification of the above illustration is that it is missing memory management strategies beyond CRUD operations, as seen in MemGPT.
Additionally, while agent memory enables persistence, it introduces new challenges that RAG and agentic RAG don’t have: memory corruption and the need for memory management strategies, such as forgetting.
At its core, RAG, agentic RAG, and agent memory are about how you create, read, update, and delete information stored in external knowledge sources (e.g., text files or databases).
| Storing information | Retrieving information | Editing and Deleting information | |
|---|---|---|---|
| RAG | Offline at ingestion stage | One-shot | Manual |
| Agentic RAG | Offline at ingestion stage | Dynamic via tool calls | Manual |
| Memory in Agents | Dynamic via tool calls | Dynamic via tool calls | Dynamic via tool calls |
Initially, the key focus in optimizing naive RAG lay in optimizing the retrieval aspect, e.g., with different retrieval techniques, such as vector, hybrid, or keyword-based search (“How to retrieve information”). Then, the focus shifted towards using the right tool to retrieve information from different knowledge sources (“Do I need to retrieve information? And if yes, from where?”). Over the last year, with the advent of memory in agents, the focus has shifted again. This time towards how information is managed: While RAG and agentic RAG had a strong focus on the retrieval aspect, memory incorporates the creation, modification, and deletion of data in external knowledge sources.