Bash is the SQL for file systems
When onboarding, almost all of our customers ask me about egress fees from the clouds. This makes sense, any public service (not running in your cloud account) gets charged full egress when you talk to it -- even when the actual service is in the same cloud region. Lame, but we support private networking options for our largest customers to avoid this.
A couple of months ago, I was talking to @nikitabase about the Databricks acquisition, and I asked him how he dealt with the fact that his customers must be angry about egress too. He told me "it's never come up", which really struck me. Why is it that the largest serverless database provider doesn't have customers worried about egress? I walked away and wrote it off as some kind of fluke where databases are very IOPS heavy but not very throughput heavy.
A little while later, I was talking to @richardartoul about Archil, and he said to me (unprompted) -- "You guys have the same problem as WarpStream, huh? Everyone is worried about egress because customers have to read 1:1 every byte they put into the service. How do you solve it?" YES. Someone who gets it, and the truth sat exactly in what he said.
"Because customers have to read 1:1 every byte they put into the service." At that moment, Hunter became enlightened.
Let's take a super-simple case in data storage: doing search through some fields. On a database, you might write "select * from table where X = Y", and in a file system you would... that's right -- you'd use grep.
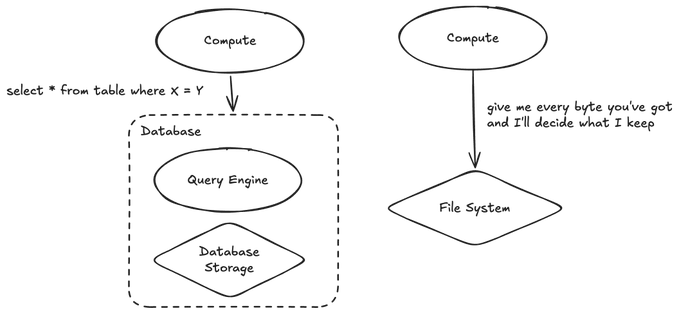
Now, obviously, there's a huge difference between these two things. When you use grep on the file system, your machine literally downloads every file that you're searching through and (in its memory) pokes around to find the files that match. [aside: it's also single threaded, so that's just great]
When you execute a "select .. where" statement on a database, your client... sends it to the database. The database embeds compute inside of it that does a similar thing, but smarter -- identifies what indexes are relevant, tries to build the most optimal version of the query, and -- importantly -- only sends back the specific data that you asked for.
Now, not only does that sound faster, it's also significantly less network traffic between the compute that you're running and the storage system. As a result, what might be 100 GBs of egress on the file system could be <2 KBs on a database.
Because the database isn't transferring the data directly. It's transferring instructions for how to interact with the data.
The net result of this fact is why we work so hard to lower the latencies on our service, and we only recommend that people use our service when they have a network round trip in hundreds of microseconds. It's worth asking though: why is the file system crippled like this? Is there any way for the file system to manage sending instructions instead of just transferring the data raw?
In fact, there is, and we already have a lingua franca that we use to interact with file systems -- it's a Linux computer with a bash interface.
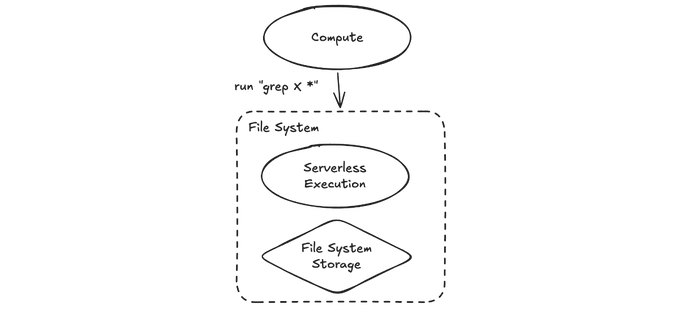
We could envision a world in which the client is able to send us a complete instruction -- a bash command -- that either retrieves or manipulates the state of the file system. We could then execute that inside of the file system itself and only return the result that the user cares about.
Just like the database case, this gives us TONS of options for how we do this execution. We could implement a planner to optimize the bash and fan it out across lots of internal compute, we could colocate the bash on the servers where the storage actually lives locally to reduce the latency of the query, and more.
The big win though: the customer doesn't need to worry about egress, latency to our service, or sizing their instance.
This is the future that we're delivering on with Archil's serverless execution feature. We are building the first file system that is not only elastic, performant, and simple to use. We're building the first file system that works how customers want, by embedding compute as a first-class primitive into the system.
We expect that serverless execution will radically simplify how developers build stateful systems. The explosion in building agents marks the first time that most developers have to think about stateful systems: managing conversation history, prompts, memory, and context are all stateful problems. Serverless execution will become a vital part of this stack.
Serverless execution is rolling out to all Archil file systems today. Create a new disk at console.archil.com to get started.