Advanced RAG Techniques: an Illustrated Overview
Now it is time to get to the more sophisticated RAG techniques like Query transformation and Routing, both involving LLMs and thus representing agentic behaviour — some complex logic involving LLM reasoning within our RAG pipeline.
4. Query transformations
Query transformations are a family of techniques using an LLM as a reasoning engine to modify user input in order to improve retrieval quality. There are different options to do that.
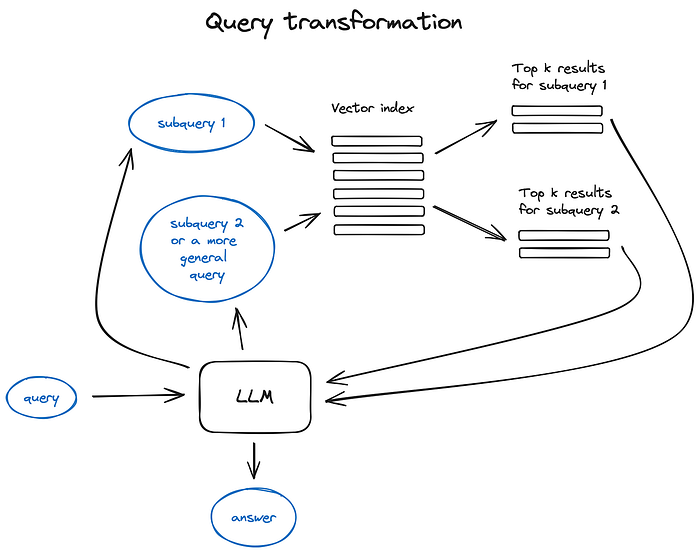
Query transformation principles illustrated
If the query is complex, LLM can decompose it into several sub queries. For examle, if you ask:
_— “What framework has more stars on Github, Langchain or LlamaIndex?”,
_and it is unlikely that we’ll find a direct comparison in some text in our corpus so it makes sense to decompose this question in two sub-queries presupposing simpler and more concrete information retrieval:
_— “How many stars does Langchain have on Github?” — “How many stars does Llamaindex have on Github?”_They would be executed in parallel and then the retrieved context would be combined in a single prompt for LLM to synthesize a final answer to the initial query. Both libraries have this functional implemented — as a Multi Query Retriever in Langchain and as a Sub Question Query Engine in Llamaindex.
-
Step-back prompting uses LLM to generate a more general query, retrieving for which we obtain a more general or high-level context useful to ground the answer to our original query on. Retrieval for the original query is also performed and both contexts are fed to the LLM on the final answer generation step.
Here is a LangChain implementation.
-
Query re-writing uses LLM to reformulate initial query in order to improve retrieval. Both LangChain and LlamaIndex have implementations, tough a bit different, I find LlamaIndex solution being more powerful here.
Reference citations
This one goes without a number as this is more an instrument than a retrieval improvement technique, although a very important one.
If we’ve used multiple sources to generate an answer either due to the initial query complexity (we had to execute multiple subqueries and then to combine retrieved context in one answer), or because we found relevant context for a single query in various documents, the question rises if we could accurately back reference our sources.
There are a couple of ways to do that:
5. Chat Engine
The next big thing about building a nice RAG system that can work more than once for a single query is the chat logic, taking into account the dialogue context, same as in the classic chat bots in the pre-LLM era.
This is needed to support follow up questions, anaphora, or arbitrary user commands relating to the previous dialogue context. It is solved by query compression technique, taking chat context into account along with the user query.
As always, there are several approaches to said context compression —
a popular and relatively simple ContextChatEngine, first retrieving context relevant to user’s query and then sending it to LLM along with chat history from the memory buffer for LLM to be aware of the previous context while generating the next answer.
A bit more sophisticated case is CondensePlusContextMode — there in each interaction the chat history and last message are condensed into a new query, then this query goes to the index and the retrieved context is passed to the LLM along with the original user message to generate an answer.
It’s important to note that there is also support for OpenAI agents based Chat Engine in LlamaIndex providing a more flexible chat mode and Langchain also supports OpenAI functional API.
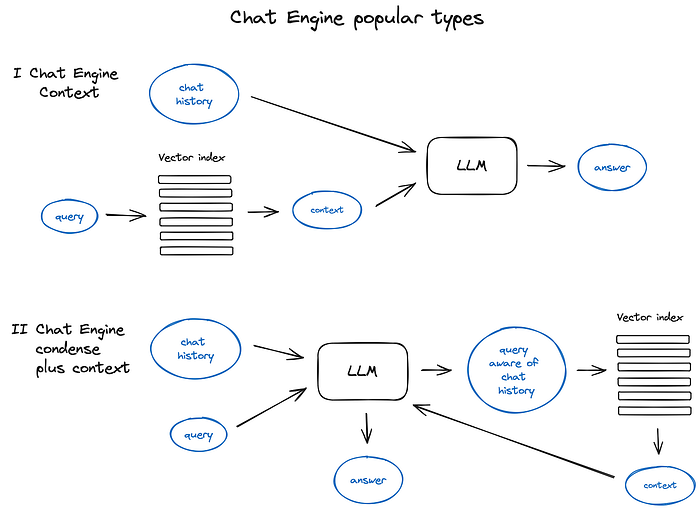
An illustration of different Chat Engine types and principles
There are other Chat engine types like ReAct Agent, but let’s skip to Agents themselves in section 7.
6. Query Routing
Query routing is the step of LLM-powered decision making upon what to do next given the user query — the options usually are to summarise, to perform search against some data index or to try a number of different routes and then to synthesise their output in a single answer.
Query routers are also used to select an index, or, broader, data store, where to send user query — either you have multiple sources of data, for example, a classic vector store and a graph database or a relational DB, or you have an hierarchy of indices — for a multi-document storage a pretty classic case would be an index of summaries and another index of document chunks vectors for example.
Defining the query router includes setting up the choices it can make.
The selection of a routing option is performed with an LLM call, returning its result in a predefined format, used to route the query to the given index, or, if we are taking of the agnatic behaviour, to sub-chains or even other agents as shown in the Multi documents agent scheme below.
Both LlamaIndex and LangChain have support for query routers.
7. Agents in RAG
Agents (supported both by Langchain and LlamaIndex) have been around almost since the first LLM API has been released — the idea was to provide an LLM, capable of reasoning, with a set of tools and a task to be completed. The tools might include some deterministic functions like any code function or an external API or even other agents — this LLM chaining idea is where LangChain got its name from.
Agents are a huge thing itself and it’s impossible to make a deep enough dive into the topic inside a RAG overview, so I’ll just continue with the agent-based multi document retrieval case, making a short stop at the OpenAI Assistants station as it’s a relatively new thing, presented at the recent OpenAI dev conference as GPTs, and working under the hood of the RAG system described below.
OpenAI Assistants basically have implemented a lot of tools needed around an LLM that we previously had in open source — a chat history, a knowledge storage, a document uploading interface and, maybe most important, function calling API. This latter provides capabilities to convert natural language into API calls to external tools or database queries.
In LlamaIndex there is an OpenAIAgent class marrying this advanced logic with the ChatEngine and QueryEngine classes, providing knowledge-based and context aware chatting along with the ability of multiple OpenAI functions calls in one conversation turn, which really brings the smart agentic behaviour.
Let’s take a look at the Multi-Document Agents scheme — a pretty sophisticated setting, involving initialisation of an agent (OpenAIAgent) upon each document, capable of doc summarisation and the classic QA mechanics, and a top agent, responsible for queries routing to doc agents and for the final answer synthesis.
Each document agent has two tools — a vector store index and a summary index, and based on the routed query it decides which one to use.
And for the top agent, all document agents are tools respectfully.
This scheme illustrates an advanced RAG architecture with a lot of routing decisions made by each involved agent. The benefit of such approach is the ability to compare different solutions or entities, described in different documents and their summaries along with the classic single doc summarisation and QA mechanics — this basically covers the most frequent chat-with-collection-of-docs usecases.
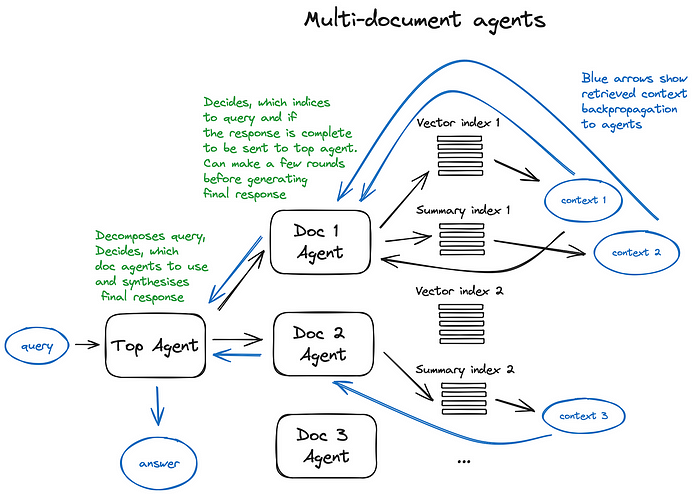
A scheme illustrating multi document agents, involving both query routing and agentic behavior patterns.
The drawback of such a complex scheme can be guessed from the picture — it’s a bit slow due to multiple back and forth iterations with the LLMs inside our agents. Just in case, an LLM call is always the longest operation in a RAG pipeline — search is optimised for speed by design. So for a large multi document storage I’d recommed to think of some simplifications to this scheme making it scalable.
8. Response synthesiser
This is the final step of any RAG pipeline — generate an answer based on all the context we carefully retrieved and on the initial user query. The simplest approach would be just to concatenate and feed all the fetched context (above some relevance threshold) along with the query to an LLM at once.
But, as always, there are other more sophisticated options involving multiple LLM calls to refine retrieved context and generate a better answer.
**The main approaches to response synthesis are:
**1. iteratively refine the answer by sending retrieved context to LLM chunk by chunk2. summarise the retrieved context to fit into the prompt3. generate multiple answers based on different context chunks and then to concatenate or summarise them.
For more details please check the Response synthesizer module docs.
Encoder and LLM fine-tuning
This approach involves fine-tuning of some of the two DL models involved in our RAG pipeline — either the Transformer Encoder, resposible for embeddings quality and thus context retrieval quality or an LLM, responsible for the best usage of the provided context to answer user query — luckily, the latter is a good few shot learner.
One big advantage nowadays is the availability of high-end LLMs like GPT-4 to generate high quality synthetic datasets.
But you should always be aware that taking an open-source model trained by professional research teams on carefully collected, cleaned and validated large datasets and making a quick tuning using small synthetic dataset might narrow down the model’s capabilities in general.
Encoder fine-tuning
I’ve also been a bit skeptical about the Encoder funetuning approach as the latest Transformer Encoders optimised for search are pretty efficient.
So I have tested the performance increase provided by finetuning of bge-large-en-v1.5 (top 4 of the MTEB leaderboard at the time of writing) in the LlamaIndex notebook setting, and it demonstrated a 2% retrieval quality increase. Nothing dramatic but it is nice to be aware of that option, especially if you have a narrow domain dataset you’re building RAG for.
Ranker fine-tuning
The other good old option is to have a cross-encoder for reranking your retrieved results if you dont trust your base Encoder completely. It works the following way — you pass the query and each of the top k retrieved text chunks to the cross-encoder, separated by a SEP token, and fine-tune it to output 1 for relevant chunks and 0 for non-relevant.
A good example of such tuning process could be found here, the results say the pairwise score was improved by 4% by cross-encoder finetuning.
LLM fine-tuning
Recently OpenAI started providing LLM finetuning API and LlamaIndex has a tutorial on finetuning GPT-3.5-turbo in RAG setting to “distill” some of the GPT-4 knowledge. The idea here is to take a document, generate a number of questions with GPT-3.5-turbo, then use GPT-4 to generate answers to these questions based on the document contents (build a GPT4-powered RAG pipeline) and then to fine-tune GPT-3.5-turbo on that dataset of question-answer pairs. The ragas framework used for the RAG pipeline evaluation shows a 5% increase in the faithfulness metrics, meaning the fine-tuned GPT 3.5-turbo model made a better use of the provided context to generate its answer, than the original one.
A bit more sophisticated approach is demonstrated in the recent paper RA-DIT: Retrieval Augmented Dual Instruction Tuning by Meta AI Research, suggesting a technique to tune both the LLM and the Retriever
(a Dual Encoder in the original paper) on triplets of query, context and answer. For the implementations details please refer to this guide.
This technique was used both to fine-tune OpenAI LLMs through the fine-tuning API and Llama2 open-source model (in the original paper), resulting in ~5% increase in knowledge-intense tasks metrics (compared to Llama2 65B with RAG) and a couple percent increase in common sense reasoning tasks.
In case you know better approaches to LLM finetuning for RAG, please share your expertise in the comments section, especially if they are applied to the smaller open source LLMs.
Evaluation
There are several frameworks for RAG systems performance evaluation sharing the idea of having a few separate metrics like overall answer relevance, answer groundedness, faithfulness and retrieved context relevance.
Ragas, mentioned in the previous section, uses faithfulness and answer relevance as the generated answer quality metrics and classic context precision and recall for the retrieval part of the RAG scheme.
In a recently released great short course Building and Evaluating Advanced RAG by Andrew NG, LlamaIndex and the evaluation framework Truelens, they suggest the RAG triad — retrieved context relevance to the query, groundedness (how much the LLM answer is supported by the provided context) and answer relevance to the query.
The key and the most controllable metric is the retrieved context relevance — basically parts 1–7 of the advanced RAG pipeline described above plus the Encoder and Ranker fine-tuning sections are meant to improve this metric, while part 8 and LLM fine-tuning are focusing on answer relevance and groundedness.
A good example of a pretty simple retriever evaluation pipeline could be found here and it was applied in the Encoder fine-tuning section.
A bit more advanced approach taking into account not only the hit rate, but the Mean Reciprocal Rank, a common search engine metric, and also generated answer metrics such as faithfulness abd relevance, is demonstrated in the OpenAI cookbook.
LangChain has a pretty advanced evaluation framework LangSmith where custom evaluators may be implemented plus it monitors the traces running inside your RAG pipeline in order to make your system more transparent.
In case you are building with LlamaIndex, there is a rag_evaluator llama pack, providing a quick tool to evaluate your pipeline with a public dataset.
Conclusion
I tried to outline the core algorithmic approaches to RAG and to illustrate some of them in hopes this might spark some novel ideas to try in your RAG pipeline, or bring some system to the vast variety of tecniques that have been invented this year — for me 2023 was the most exciting year in ML so far.
There are many more other things to consider like web search based RAG (RAGs by LlamaIndex, webLangChain, etc), taking a deeper dive into agentic architectures (and the recent OpenAI stake in this game) and some ideas on LLMs Long-term memory.
The main production challenge for RAG systems besides answer relevance and faithfulness is speed, especially if you are into the more flexible agent-based schemes, but that’s a thing for another post. This streaming feature ChatGPT and most other assistants use is not a random cyberpunk style, but merely a way to shorten the perceived answer generation time.
That is why I see a very bright future for the smaller LLMs and recent releases of Mixtral and Phi-2 are leading us in this direction.
Thank you very much for reading this long post!
The main references are collected in my knowledge base, there is a co-pilot to chat with this set of documents: https://app.iki.ai/playlist/236.