Machine Learning Model CI/CD and Shadow Platform
By Quinn Zuo, Sudhi Murthy, and Nitin Sharma

Arcaden By Denis
This blog is the first in a series that provides a comprehensive overview of a machine learning (ML) shadow platform for model continuous integration /continuous deployment (CI/CD) framework developed at PayPal for end-to-end management of a large cohort of ML models.
Introduction
isk platform is the biggest production AI/ML environment in PayPal. Risk platform enables PayPal to combat sophisticated fraud attacks and cybercrimes in real-time. The platform seamlessly shares intelligence and context across the customer journey while collecting feedback from multiple customer touch points to continuously improve the underlying machine learning (ML) and deep learning (DL) models.
Due to the regulatory requirements (criticality, high accuracy, and fairness) of these ML/DL models, models and dependent features need to pass through a model CI/CD pipeline and be tested in a ML shadow platform before they are released in a live production environment. The ML shadow platform we built to provide such capabilities is called “Quokka” — a cute, friendly, and approachable creature.
The problem is we don’t understand the problem — Paul MacCready
Before we dive into the platform, let’s start with a story. In 1959, Henry Kremer, a British industrialist, had a hypothesis that an airplane could fly by using a pilot’s body power only. He offered £50,000 for the first person to build such a plane. Further, he offered another £100,000 for the first human-powered airplane to fly across the English Channel. After 18 years, dozens of teams tried and failed until Paul MacCready, an American mechanical engineer, decided to take the challenge. MacCready found that people spent upwards of a year building an airplane on conjecture and theory without the grounding of empirical tests. Minutes later after the airplanes set to fly, a years’ worth of work would smash into the ground.
“The problem is we don’t understand the problem” said MacCready. MacCready then changed the process to enable better problem solving. He decided to build planes using Mylar, aluminum tubing, and wire so that the airplanes could be rebuilt in hours instead of months. This way he could keep rebuilding, retesting, and relearning. Sometimes, MacCready would fly three or four different planes in a single day. After six months, MacCready won the first Kremer prize. A year after, the airplane he built flew across the channel.
The process MacCready followed is what Quokka does for fraud models and dependent features. Modelers can iteratively and continuously train, test, deploy, and monitor (for model deterioration) in a safe, fast, cost-effective, and maintainable way. This avoids the time sink of building a theoretical high-performing model offline.
Fraud Domain Context
Developing and maintaining a CI/CD pipeline in the financial technology space comes with its own set of challenges, which can be addressed through a framework such as this platform. Domains such as fraud detection are complex: we need to identify dynamic patterns across heterogeneous regions, devices, populations, and use cases. Such heterogeneity can pose significant challenges to model performance stability, as training data and out-of-time or adjudicated population data might systematically diverge as time passes. In some contexts, and to varying extents, the heterogeneity in data distributions and temporal changes also apply to other domains such as credit risk (for example, delinquency assessment), and marketing (for example, customer churn prediction).
Temporally aware representations (such as time-weighted features to emphasize the importance of recent data over older data) are often introduced as features to represent evolving aspects of fraud patterns, and thus include temporal information that can boost model performance. Refreshing the model weights with the most recent data to learn evolving distributions aids model robustness further.
However, building temporally aware representations in an unsupervised context is an open-ended process, with a lot of subjective considerations such as time-duration for aggregations, range of constants, and mathematical transformations. Such manual feature engineering leads to a significant increase in feature space and adds overhead to the iterative feature selection process in the future. Aside from this, the source of truth (or the fraud tag) takes different extents of time to mature, depending on the type of fraud modus operandi.
Recognizing that model robustness and performance over time are critical to the model development process, the underlying deployment infrastructure needs to provide a framework that allows modelers to run temporal comparisons between different versions of models (for example, trained on different datasets, using different algorithms and hyperparameters), so a winner can be effectively picked for final stage deployment along with strategy considerations.
Platform Motivation
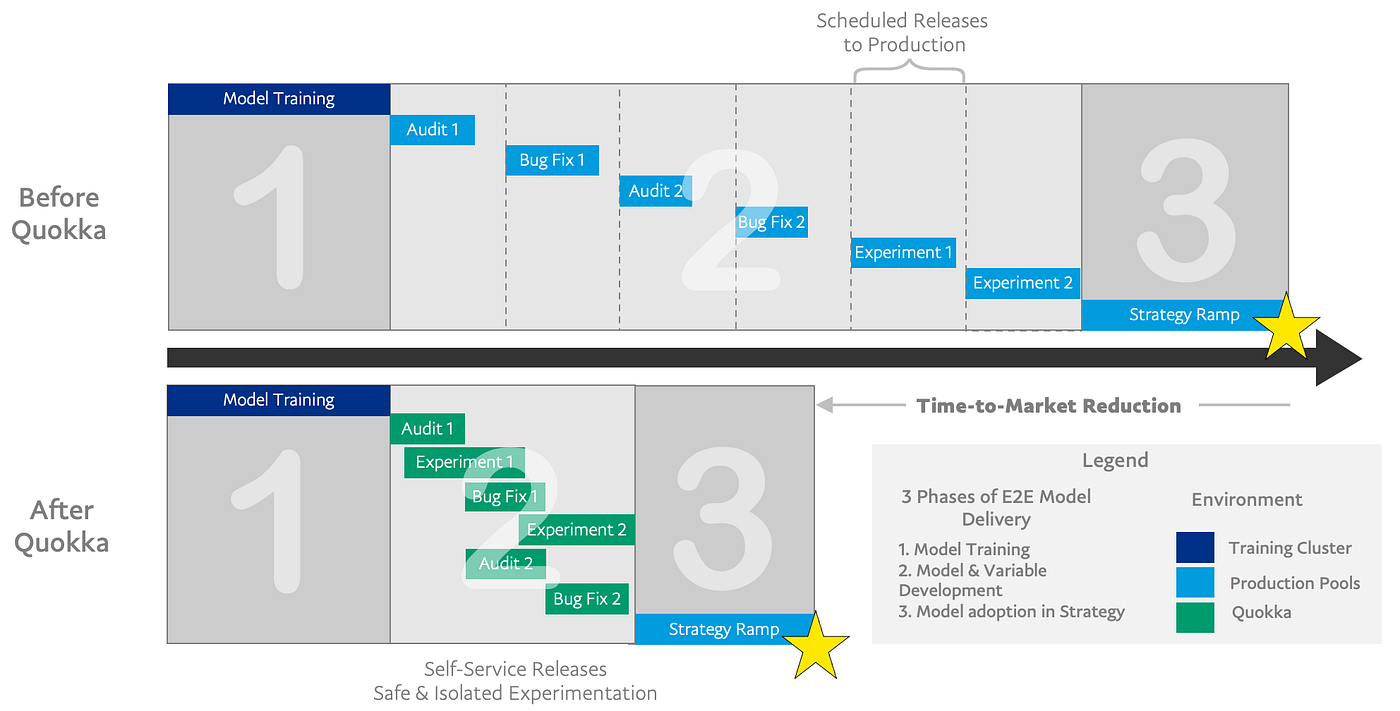
Before this ML shadow platform was built, there were several challenges in model development, deployment, and operation.
First, models and dependent features were bundled as part of a build image and the release schedule was fixed. If a modeler didn’t get to release a trained model in a particular release, then s/he needed to wait for the next release, which was usually another couple of weeks.
Second, there were many manual steps during the release process among different teams. This forced the ML release engineers to not only have a good understanding of different internal software platforms, but also the complex business processes.
Third, the model may have model score or data drift once brought to real-time prediction in production. This is because offline training and real-time production data often have data parity issues. The model sometimes failed during execution or couldn’t complete the execution within the required real-time SLA, and caused runtime system issues. When that happened, the entire live pool needed to rollback, and the released model needed to go through the entire model development lifecycle again. If it was a brand-new model, the model time to value could take up to several months before a model could be fully adoptable by business. If it was a new modeling technology, it could take even longer.

Figure 1. End-to-end model lifecycle before Quokka
When we created this ML shadow platform, our goal was to solve the above challenges. So, our requirements were as following:
- Model release, test, and deploy need to be as easy as software engineer release code via CI/CD, and with the same discipline and rigor.
- The platform need to be automated with a self-service capability. Modelers who need to release the model could bring their own models through the self-service UI/UX.
- We need to build a shadow environment which is almost identical to our production environment except model scores are only logged without participating in decision adjudication. This shadow system not only can be used to test different models at any given time to speed up the model development in a safe and fast way, but also can concurrently test multiple versions of the same model in a cost-effective and maintainable manner.
System Architecture
The ML shadow platform was built to consist of front-tier apps in Node.js and React.js, mid-tier apps in Python and Java, Hadoop/BigQuery for storage of analytical data, Aerospike for caching, and many open-source components such as HDFS, ONNX, TensorFlow, and MLFlow.
The platform has three subcomponents that are integrated together to form a working E2E shadow environment as follows:
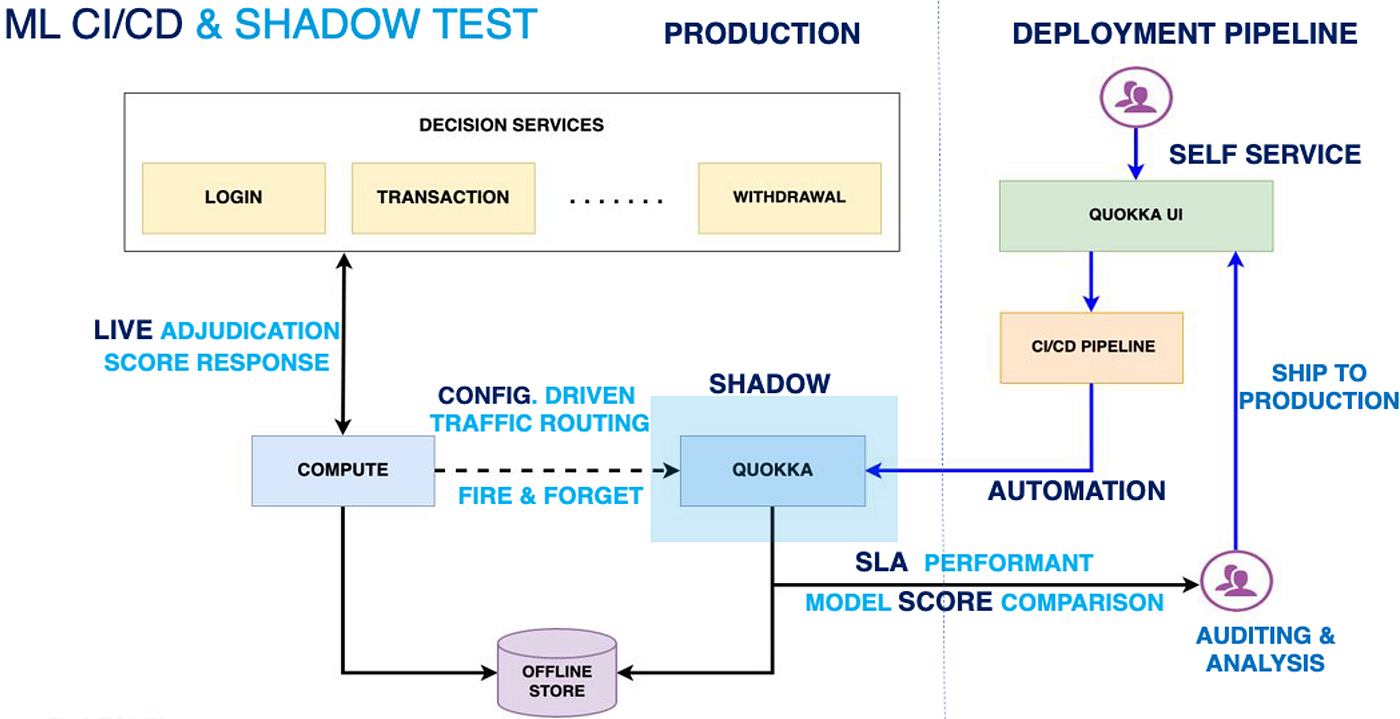
A) Self-Service UI/UX workflows to trigger the audit journey of the trained model from the store to real-time inferencing. The UI/UX allows the modeler/researcher to schedule the deployment at a time of choice. The platform also provides scheduling via API interfaces as well.
B) An automated CI/CD pipeline that could package the artifact with the production stack and deploy all the way to production boxes. The automated CI/CD system can provide status notifications at periodic intervals of the deployment progress.
C) An auditing compute environment is depicted as “SHADOW,” separate from a production computing environment to perform LIVE testing of risk models. The audit pool corresponds to a set of machines that run in parallel and mimic the production pool by processing sampled domain traffic that is configurable and routed from the production pool. The auditing pool (Quokka) receives the same context data and accesses the same production databases. However, the pool does not participate in the adjudication (decisioning) process, such as risk analysis determination, in the rule engines. The audit pool generates critical data for performing offline auditing analysis as well as checking if the model execution was SLA performant.
This ML shadow platform provides a dual mode of operation, one in which to iteratively package, deploy and audit models in Test mode. Once audited and SLA performant, using the same pipeline enabled the graduation of the audited model to release.
Model CI/CD Pipeline
An iterative representation of the model CI/CD pipeline is below, with front tier orchestrating the change request test, and then pushing analytical artifacts to production per schedule release.

Below is the lifecycle representation of the analytical artifact delivered via the model store or API integration to an iterative CI/CD workflow. On validating and meeting release criteria, the ML artifact graduates to the production pool.
Self-Service UIs and APIs
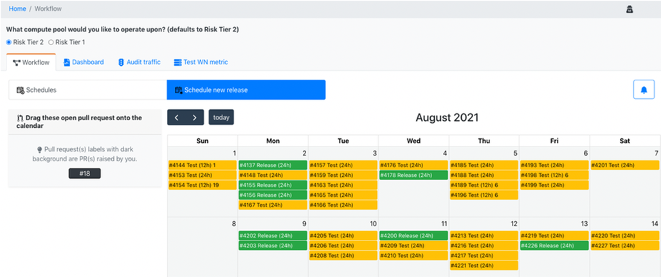
A self-service UI/UX automates and streamlines the model CI/CD workflows as below. Some of the features of our self-service UI/UX include:
A) A change request calendar with capabilities to book in the shadow environment for each data science team member with a configurable duration to test the analytical artifact. The “YELLOW” points to “TEST” content and the “GREEN” indicates the “RELEASE” content. “RELEASE” content has undergone iterative deployment in the SHADOW environment via “TEST” mode and meets the release criteria to ship to production pools.
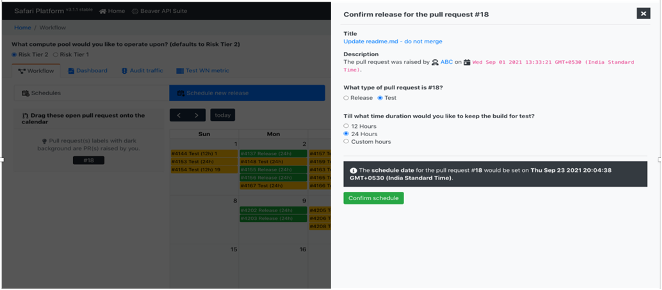
B) A representation workflow to configure the sampling traffic from the production pool for auditing for specific (black boxes for masking confidential information) checkpoints where analytical artifacts are deployed. Checkpoints are customer journey touch points and each touch point has risk decisioning. In addition to performing traffic metering to existing risk checkpoints, the self-service workflows enable onboarding newer risk checkpoints integrated in the stack.
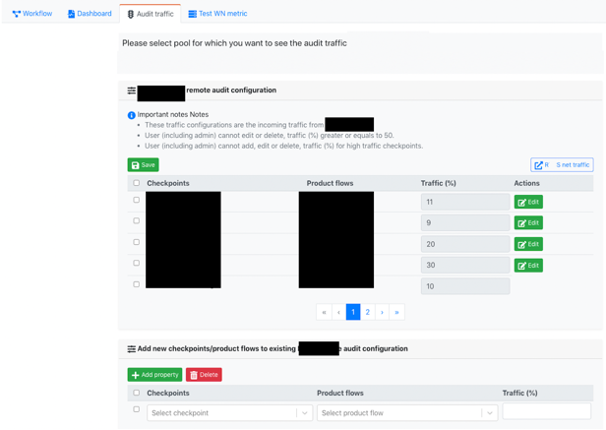
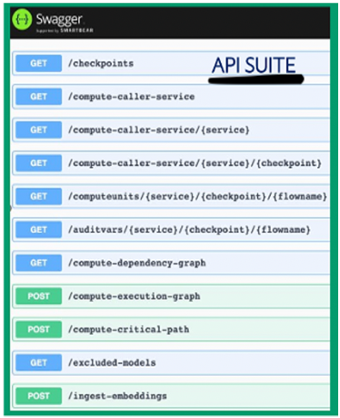
C) An API suite for delivering artifacts, analytical data for research, and model lifecycle management — a subset of the API list as below. The below list is not definitive and is a representation of the capabilities available from the SHADOW environment.
System Metrics
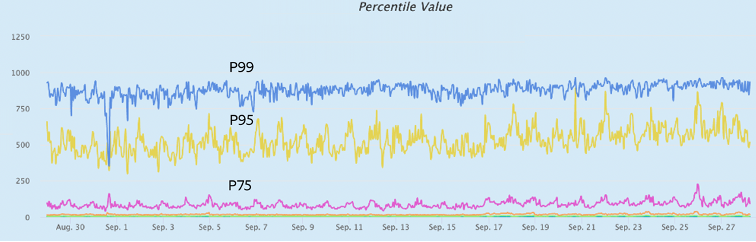
Real-time prediction has a stringent SLA for model inferencing and the balance of performance and analytical accuracy must be met.
The model inferencing should be within the prescribed SLA and has a correlation with the ATB of the hosting service. Metrics such as P99 and data load time for the model inferencing are vital data. Analytical accuracy and score distribution correlates with the efficacy of strategy rule execution (business policy).
The “SHADOW” facilitates the readout of these metrics and enables seamless graduation of the model from shadow to production. Representation graphs of the model show execution and score distribution.
P99 Model Execution

Model score distribution
Scalability and Adoption
In the absence of the ML shadow platform, the velocity of the change requests for rapid refresh of the models and analytical artifacts would be a constraint. The MLOps tool enablement between the year with manual step to the year with MLOps indicates the leap in productivity and adoption acceleration of fraud solutions. Note that PRs mean pull requests or change requests to the ML/DL hosting stack.
Since the emergence of Quokka, the data science teams’ adoption (based on PR counts) has grown quarter-by-quarter at a 50% rate. The model development and deployment time reduced by 80%. There has been no system rollback due to model execution failure. User productivity improved by 3x. Without additional engineering resources, we extend our operational support coverage from 8x5 to 24x7.
Future Work
In subsequent blogs, we will provide an overview of how the CI/CD pipeline is being developed to provide meta-learning features for effectively and proactively relearning model coefficients in response to evolving distributions. We will elaborate on key CI/CD features in the ML platform, such as a feature store for cataloging manually engineered features and representations derived during the process of model training. Lastly, we will describe a hub for generic models and components. This hub can be used to begin the process of transfer learning through more nuanced fraud patterns or customer segments.
Acknowledgement
Many thanks to Anshuman Gondalia and his engineering team for creating the ML shadow platform and Grahame Jastrebski for sponsoring the effort and providing input to this blog.
If you are interested in solving challenging problems in machine learning and see how your work can directly contribute to PayPal’s business, please contact us! We are actively looking for motivated engineers and product managers.