Your Biggest Customer Might Be Your Biggest Bottleneck
An illustration of messages being bottlenecked.
It was a late night at the Trieve office, and we had just onboarded our largest customer to date onto the platform. That’s when our phones started lighting up with complaints flooding our Slack and Discord channels. Customers were reporting that their documents had been failing to index for hours.
The culprit was our newest customer, who was dumping millions of documents into our service and had completely clogged our ingestion pipeline. We tried throwing more workers at the problem, but it didn’t help. They were all tied up processing this massive job while everyone else’s data sat in an endless queue.
We needed a better way to manage our queues and ensure that all customers were treated fairly.
The Anatomy of a Noisy Neighbor
What we were seeing had a name: the “noisy neighbor” problem. In multi-tenant systems, one greedy tenant can starve out the rest.
Imagine you’re Cursor, indexing millions of codebases. Each repo is broken down into thousands of files, and each file needs to get pushed through an ingestion pipeline—tokenized, vectorized, chunked, and embedded.
Then, a new customer signs up with a massive monorepo containing tens of millions of files. The moment their job hits the pipeline, you can only watch in horror as your other customers’ indexing requests grind to a halt. For the next several hours, your system is held hostage by a single tenant.
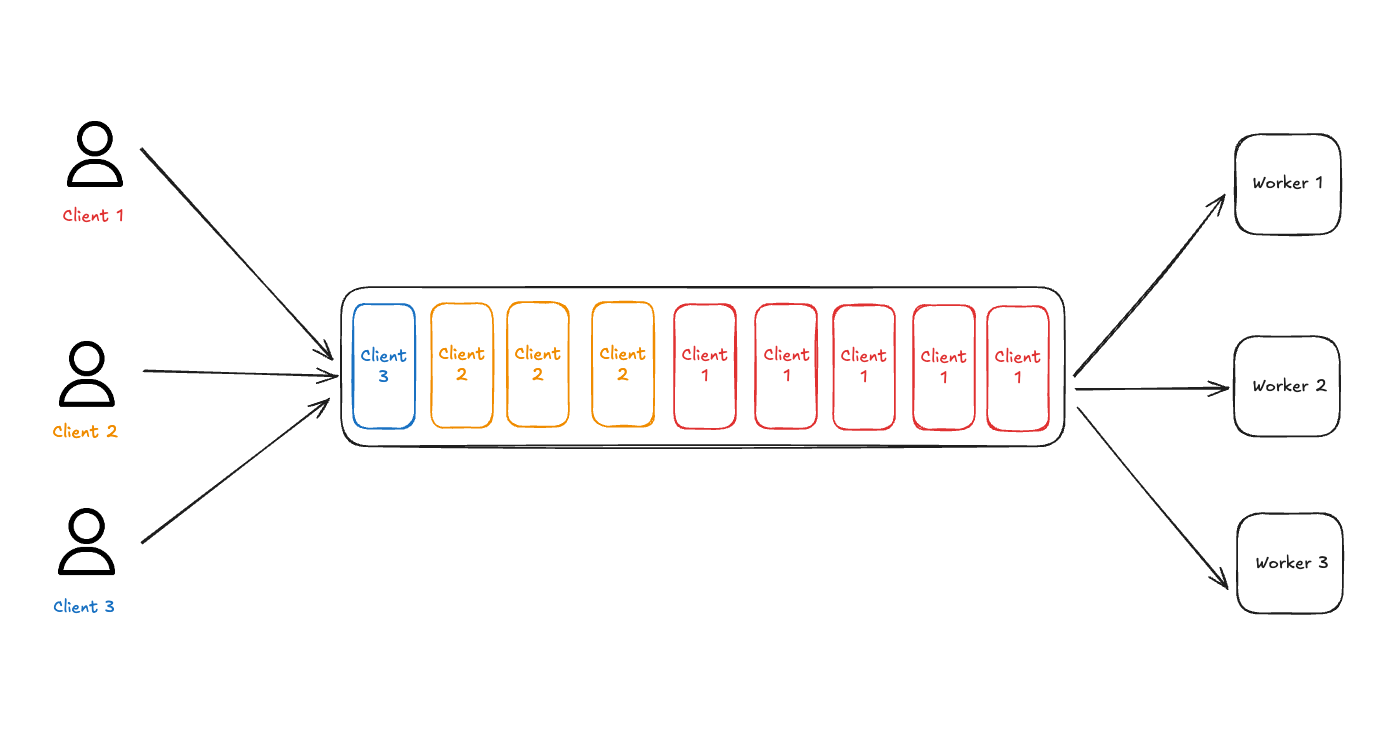
In a traditional FIFO queue, smaller jobs are stuck waiting behind one massive job.
This is a fundamental flaw in systems built on a traditional First-In, First-Out (FIFO) messaging queue. FIFO only cares about who got there first, not who needs serving most.
Why Traditional Fixes Fall Short
When you’re dealing with noisy neighbors, there are a few common solutions that come to mind.
A. Throttling Clients
The first instinct is to just limit how fast customers can send messages. But this approach basically says “your burst traffic is now your problem to solve.”
Customers end up having to build complex retry logic, implement their own queuing, and deal with the operational headaches that come with managing backpressure. Meanwhile, you’re stuck building sophisticated global rate-limiting systems that add complexity to your infrastructure.
B. Dedicated Worker Queues
The next idea sounds reasonable: give big customers their own dedicated resources. We actually tried this at Trieve, spinning up separate worker fleets for our largest clients.
The reality was far from ideal. These customers would send massive bursts of work, like uploading hundreds of gigabytes of data in an hour, followed by long periods of silence, leaving expensive worker instances sitting completely idle.
Even worse, we discovered that smaller customers would occasionally have their own traffic spikes, forcing us into the nightmare scenario of manually extracting their messages from shared queues and migrating them to dedicated infrastructure. The operational overhead was unsustainable.
The Solution: Fair Queueing
After hitting a wall with these conventional approaches, we realized we weren’t facing an infrastructure problem, but a logic problem. We needed a smarter queue.
Traditional queues are like having one massive line at the DMV. Everyone gets served in the order they arrived, which sounds fair until someone shows up with paperwork for 100 vehicles.
Fair queueing is different. It’s like having separate lines for each customer, but with a receptionist who calls one person from each line in rotation.
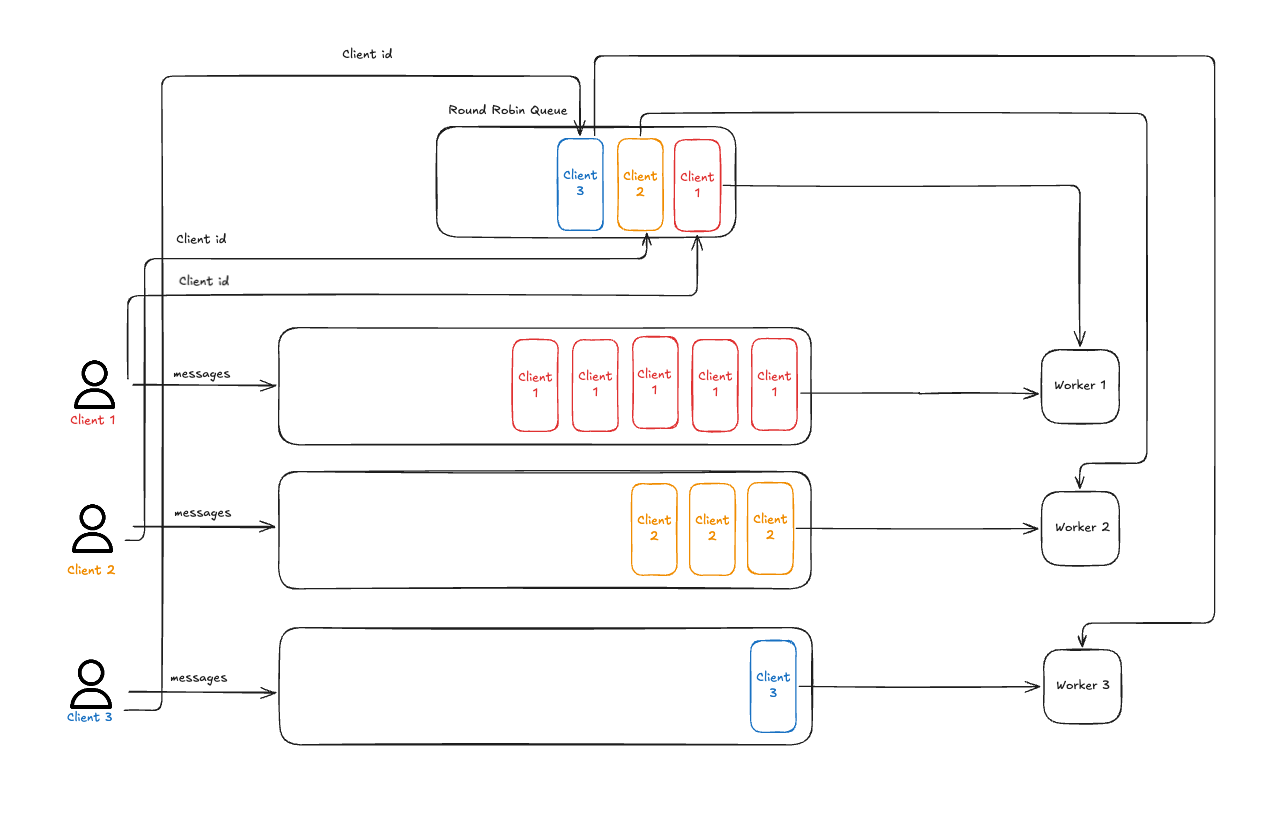
Fair queueing ensures every customer gets a turn, preventing starvation.
Busy customers stay busy, but they can’t starve quiet customers. If Customer A has 1,000 messages and Customer B has 1, Customer B doesn’t have to wait for all 1,000 of Customer A’s messages to clear. The system simply alternates between them: A, B, A, A, A… Everyone makes progress.
How Broccoli Implements Fairness
I built Broccoli to make this concept a reality. The core architecture is simple, built on just two main components: a dedicated queue for each client and a single round-robin scheduler. This design makes it reliable and easy to debug, which is crucial for critical infrastructure.
Here’s how the fair queuing is implemented:
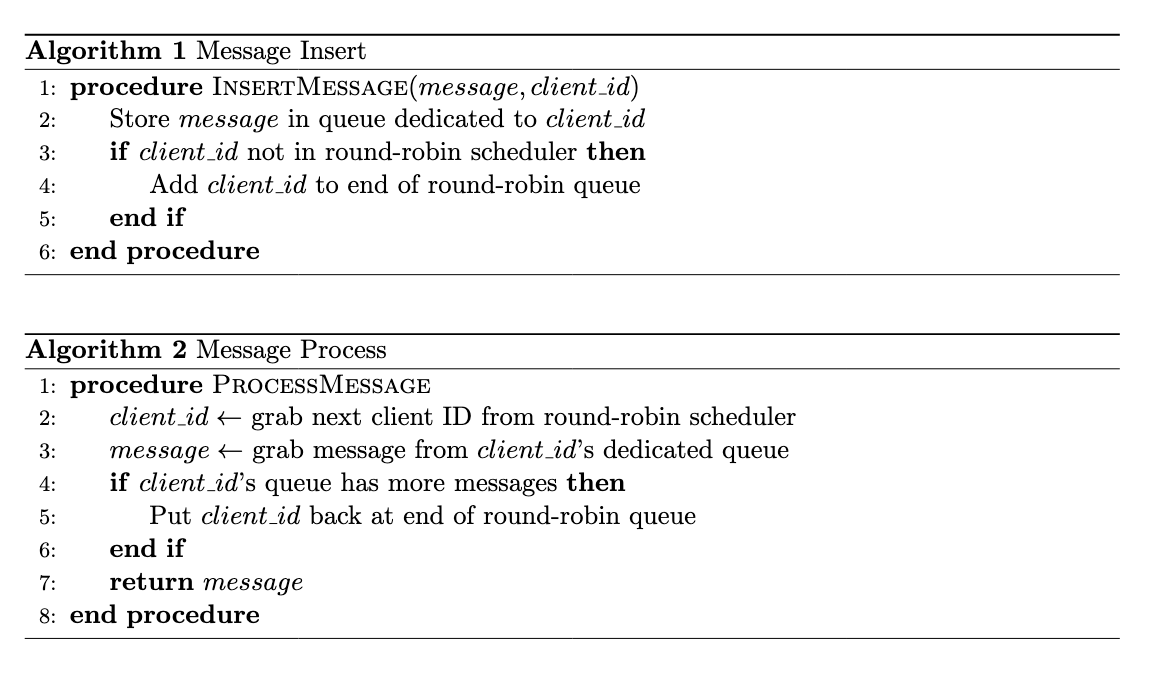
Pseudo code for fairness algorithm
When a message arrives (Insert operation):
-
We store the message in a queue that’s dedicated to that specific client
-
We check if this client’s ID is already in our round-robin scheduler
-
We grab the next client ID from our round-robin scheduler
-
We go to that client’s dedicated queue and grab one of their messages
-
After processing, we check if they have more work waiting
The beauty of this approach is that it’s completely self-balancing. Busy clients stay in the rotation, quiet clients automatically drop out, and everyone gets fair access to processing time regardless of how much work they’ve queued up.
Conclusion
When I first open-sourced Broccoli, I had no expectations about whether people would use it, but the reception has been insane. Since then, the project has had 15,000+ downloads and 400+ stars on GitHub.
Big shoutout to danigiri for adding support for SurrealDB as a broker and making the project more flexible for everyone.
If you want to dig in deeper or try it out for yourself, check out Broccoli on GitHub, or if you just want to chat about queues or distributed systems in general, feel free to reach out to me on Twitter @densumesh.