Seamless Istio Upgrades at Scale
[

Zoom image will be displayed

Airbnb has been running Istio® at scale since 2019. We support workloads running on both Kubernetes and virtual machines (using Istio’s mesh expansion). Across these two environments, we run tens of thousands of pods, dozens of Kubernetes clusters, and thousands of VMs. These workloads send tens of millions of QPS at peak through Istio. Our IstioCon 2021 talk describes our journey onto Istio and our KubeCon 2021 talk goes into further detail on our architecture.
Istio is a foundational piece of our architecture, which makes ongoing maintenance and upgrades a challenge. Despite that, we have upgraded Istio a total of 14 times. This blog post will explore how the Service Mesh team at Airbnb safely upgrades Istio while maintaining high availability.
Challenges
Airbnb engineers collectively run thousands of different workloads. We cannot reasonably coordinate the teams that own these, so our upgrades must function independently of individual teams. We also cannot monitor all of these at once, and so we must minimize risk through gradual rollouts.
With that in mind, we designed our upgrade process with the following goals:
- Zero downtime for workloads and users. This is the seamless part of the upgrade — a workload owner doesn’t need to be in the loop for Istio upgrades.
- Gradual rollouts with the ability to control which workloads are upgraded or reverted.
- We must be able to roll back an upgrade across all workloads, without coordinating every workload team.
- All workloads should be upgraded within some defined time.
Architecture
Our deployment consists of one management cluster, which runs Istiod and contains all workload configuration for the mesh (VirtualServices, DestinationRules, and so forth), and multiple workload clusters, which run user workloads. VMs run separately, but their Istio manifests are still deployed to the management cluster in their own namespaces. We use Sidecar mode exclusively, meaning that every workload runs istio-proxy — we do not yet run Ambient.
Zoom image will be displayed
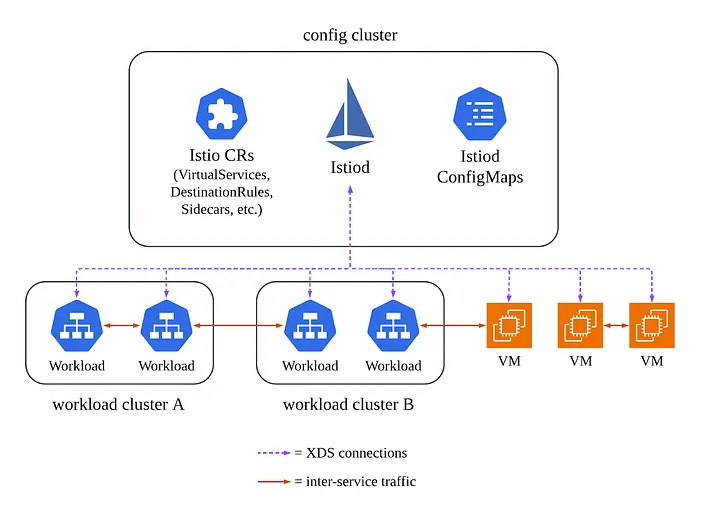
Upgrade Process
At a high level, we follow Istio’s canary upgrade model. This involves running two versions (or Istio revisions) of Istiod simultaneously: the current version and the new version that we are upgrading to. Both form one logical service mesh, so workloads connected to one Istiod can communicate with workloads connected to another Istiod and vice versa. Istiod versions are managed using different revision labels — for example, 1–24–5 for Istio 1.24.5 and 1–25–2 for Istio 1.25.2.
An upgrade involves both Istiod, the control plane, and istio-proxy, the data plane sidecar, running on all pods and VMs. While Istio supports connecting an older istio-proxy to a newer Istiod, we do not use this. Instead, we atomically roll out the new istio-proxy version to a workload along with the configuration of which Istiod to connect to. For example, the istio-proxy built for version 1.24 will only connect to 1.24’s Istiod and the istio-proxy built for 1.25 will only connect to 1.25’s Istiod. This reduces a dimension of complexity during upgrades (cross-version data plane — control plane compatibility).
The first step of our upgrade process is to deploy the new Istiod, with a new revision label, onto the management cluster. Because all workloads are explicitly pinned to a revision, no workload will connect to this new Istiod, so this first step has no impact.
The rest of the upgrade comprises all of the effort and risk — workloads are gradually shifted to run the new istio-proxy version and connect to the new Istiod.
Zoom image will be displayed
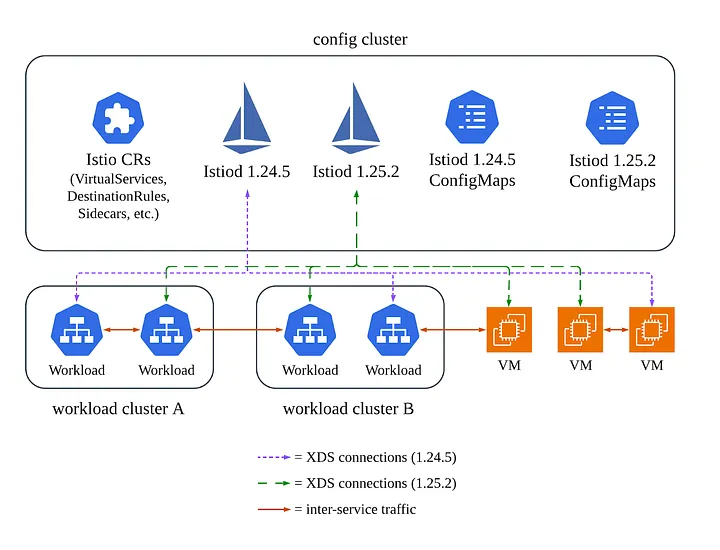
Multiple Istio revisions, with some workloads connected to different revisions.
Rollout specification
We control what version of istio-proxy workloads run through a file called rollouts.yml. This file specifies workload namespaces (as patterns) and the percentage distribution of Istio versions:
production:
1-24-5: 100
".*-staging":
1-24-5: 75
1-25-2: 25
istio-e2e:
1-25-2: 100
This spec dictates the desired state of all namespaces. A given namespace is first mapped to a bucket (based on the longest pattern that matches) and then a version is chosen based on the distribution for that bucket. The distribution applies at the namespace level, not the pod (or VM) level. For example,
".*-staging":
1-24-5: 75
1-25-2: 25
means that 75% of the namespaces with the suffix -stagingwill be assigned to 1–24–5 and the remaining 25% will be assigned to 1–25–2. This assignment is deterministic, using consistent hashing. The majority of our upgrade process involves updating rollouts.yml and then monitoring.
This process allows us to selectively upgrade workloads. We can also upgrade environments separately and ensure that only a certain percentage of those environments are on the new version. This gives us time to bake an upgrade and learn of potential regressions.
The rest of this post will describe the mechanism through which a change to rollouts.yml is applied to thousands of workloads, for both Kubernetes and VMs.
Kubernetes
Each Istio revision has a corresponding MutatingAdmissionWebhook for sidecar injection on every workload cluster. This webhook selects pods specifying the label istio.io/rev=<revision> and injects the istio-proxy and istio-init containers into those pods. Notably, the istio-proxy container contains the PROXY_CONFIG environment variable, which sets the discoveryAddress to the Istiod revision. This is how the istio-proxyversion and the configuration for which Istiod to connect to are deployed atomically — entirely by the sidecar injector.
Every workload’s Deployment has this revision label. For example, a workload configured to use Istio 1.24.5 will have the label istio.io/rev=1–24–5in its pod template; thus pods for that Deployment will be mutated by the MutatingAdmissionWebhook for Istio 1.24.5.
This setup is the standard method of upgrading Istio, but requires that every Deployment specifies a revision label. To perform an upgrade across thousands of workloads, every team would have to update this label and deploy their workload. We could neither perform a rollback across all workloads nor reasonably expect an upgrade to complete to 100%, both for the same reason — relying on every workload to deploy.
Krispr
To avoid having to update workloads individually, a workload’s configuration never directly specifies the revision label in source code. Instead, we use Krispr, a mutation framework built in-house, to inject the revision label. Krispr gives us the ability to decouple infrastructure component upgrades from workload deployments.
Airbnb workloads that run on Kubernetes use an internal API to define their workload, instead of specifying Kubernetes manifests. This abstraction is then compiled into Kubernetes manifests during CI. Krispr runs as part of this compilation and mutates those Kubernetes manifests. One of those mutations injects the Istio revision label into the pod specification of each Deployment, reading rollouts.ymlto decide which label to inject. If a team sees any issue with their workload when they deploy, they can roll back and thus also roll back the Istio upgrade — all without involving the Service Mesh team.
In addition, Krispr runs during pod admission. If a pod is being admitted from a Deployment that is more than two weeks old, Krispr will re-mutate the pod and accordingly update the pod’s revision label if needed. Combined with the fact that our Kubernetes nodes have a maximum lifetime of two weeks, thus ensuring that any given pod’s maximum lifetime is also two weeks, we can guarantee that an Istio upgrade completes. A majority of workloads will be upgraded when they deploy (during the Krispr run in CI) and for those that don’t deploy regularly, the natural pod cycling and re-mutation will ensure they are upgraded in at most four weeks.
In summary, per workload:
- During CI, Krispr mutates the Kubernetes manifests of a workload to add the Istio revision label, based on
rollouts.yml. - When a pod is admitted to a cluster, Krispr will re-mutate the pod if its Deployment is more than two weeks old and update the Istio revision label if needed.
- The revision-specific Istio MutatingAdmissionWebhook will mutate the pod by injecting the sidecar and associated
discoveryAddress.
Virtual machines
On VMs, we deploy an artifact that contains istio-proxy, a script to run istio-iptables (similar to the istio-init container), and the Istiod discoveryAddress. By packaging istio-proxy and the discoveryAddress in the same artifact, we can atomically upgrade both.
Installation of this artifact is the responsibility of an on-host daemon called mxagent. It determines what version to install by polling a set of key-value tags on the VM (such as EC2 tags on AWS or resource tags on GCP). These tags mimic the istio.io/rev label for Kubernetes-based workloads. Whenever they change, mxagent will download and install the artifact corresponding to that version. Thus, upgrading istio-proxy on a VM just involves updating these tags on that VM; mxagent will take care of the rest.
Our VM workloads are largely infrastructure platforms that don’t typically have code deployed at regular intervals. As such, VMs don’t support a deploy-time upgrade (in the way that Kubernetes workloads can be upgraded when they deploy). Similarly, teams cannot roll back these workloads themselves, but this has been acceptable, given that there are just a handful of such infrastructure platforms.
The tag updates are managed by a central controller, mxrc, which scans for outdated VMs. If rollouts.yml would result in a different set of resource tags for a VM, the controller will update the tags accordingly. This roughly corresponds to Krispr’s pod admission-time mutation — however, with the caveat that VMs are mutable and long-lived, and thus are upgraded in-place.
For safety, mxrc takes into account the health of the VM, namely in the form of the readiness probe status on the WorkloadEntry. Similar to Kubernetes’ maxUnavailable semantics, mxrc aims to keep the number of unavailable VMs (that is, unhealthy VMs plus those with in-progress upgrades) below a defined percentage. It gradually performs these upgrades, aiming to upgrade all the VMs for a workload in two weeks.
At the end of two weeks, all VMs will match the desired state in rollouts.yml.
Conclusion
Keeping up-to-date with open-source software is a challenge, especially at scale. Upgrades and other Day-2 operations often become an afterthought, which furthers the burden when upgrades are eventually necessary (to bring in security patches, remain within support windows, utilize new features, and so forth). This is particularly true with Istio, where a version reaches end-of-life support rapidly.
Even with the complexity and scale of our service mesh, we have successfully upgraded Istio 14 times. This was made possible due to designing for maintainability, building a process that ensures zero downtime, and derisking through the use of gradual rollouts. Similar processes are in use for a number of other foundational infrastructure systems at Airbnb.
Future work
As Airbnb’s infrastructure continues to evolve and grow, we’re looking at a few key projects to evolve our service mesh:
- Utilizing Ambient mode as a more cost-effective and easier-to-manage deployment model of Istio. In particular, this simplifies upgrades by not needing to touch workload deployments at all.
- Splitting our singular production mesh into multiple meshes in order to separate fault domains, provide better security isolation boundaries, and scale Istio further. For upgrades, this would further reduce the blast radius, as some meshes that only run low-risk workloads (such as staging) could be upgraded first.
If this type of work interests you, we encourage you to apply for an open position today.
Acknowledgements
All of our work with Istio is thanks to many different people, including: Jungho Ahn, Stephen Chan, Weibo He, Douglas Jordan, Brian Wolfe, Edie Yang, Dasol Yoon, and Ying Zhu.
All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.