Data Mesh at Grab Part II: The Foundational Tools behind Certification
Introduction
In Part I, we discussed why Grab is investing in a data mesh, referred to as the Signals Marketplace within Grab, as part of our evolving data culture. We also explained how data certification aids teams in reliably reusing data across different domains. However, cultural change doesn’t occur through principles alone; it happens when tools reshape people’s daily behaviors. Therefore, it is crucial for us to develop effective platforms that integrate these practices.
This follow-up focuses on these platforms that make certification work at Grab:
- Hubble – the central metadata management platform with a built-in certification engine.
- Genchi – the data quality observability platform.
- Data Contract Registry – the central service for managing data contracts.
Together, these platforms turn data mesh principles into an operational system that scales across hundreds of thousands of datasets, streams, attributes, and metrics.
Hubble: The data discovery and governance layer
Hubble is Grab’s central metadata management platform and data catalog for all data assets, including datasets, dashboards, metrics, Machine learning (ML) models, and more. Built on top of the open‑source DataHub and heavily extended for Grab’s needs, it is the discovery and governance layer for the Signals Marketplace.

Figure 1. Hubble cataloging data assets across various data platforms in Grab.
What Hubble does for data mesh
For certification and data mesh, Hubble provides a few key capabilities:
- Search and discovery: Data analysts/scientists, engineers, and product managers use Hubble to search the rich swath of data assets, then inspect schemas, documentation, lineage, and usage statistics in one place. This replaces back-channel questions and tribal knowledge with a single, self-serve catalog.
- Ownership and domains: Every asset is tied to a domain and explicit technical and business owners. This enforces the domain ownership model that Signals Marketplace depends on. Producers are clearly accountable for the quality and lifecycle of the data products they publish.
- Data contracts and documentation: Data contracts, classifications, and rich documentation live as structured metadata attached to each asset, not scattered across wikis and slide decks. Producers and consumers share the same source of truth when they ask questions like, “what does this table guarantee?”.
- Lineage and impact analysis: Hubble provides table, column, and metric-level lineage so owners can see which teams and pipelines depend on their data before making breaking changes or deprecations. Instead of guessing, they can answer “what will I break?” with a single click.
- Certification status: The familiar “Hubble green tick” turns trust into a first-class signal in the catalog. Assets that meet Grab’s certification criteria are clearly marked with a drill-down view of which criteria are satisfied (ownership, documentation, contracts, quality tests, upstream certification) and which are still missing.
From a consumer’s point of view, this collapses a lot of uncertainty into a simple workflow: search → filter to “certified” → pick the most suitable asset. They don’t need to reverse-engineer reliability from table names and hearsay.
Hubble’s system architecture
The open-source DataHub architecture is fundamentally event-driven and designed for high extensibility, moving away from the “passive” catalogs of the past, towards a “living” metadata graph. DataHub models everything as an Entity (e.g., a Dataset), composed of multiple Aspects (atomic versioned metadata like SchemaMetadata or Ownership), connected by Relationships (e.g., DownstreamOf).
Since introducing DataHub as Grab’s central data catalog in 2022, we’ve tailored it to Grab’s specific needs while continuously rebasing onto the latest open-source DataHub releases. This lets us adopt new capabilities from the community quickly, contribute improvements back, and evolve Hubble without forking away from the main project.
On top of the DataHub foundation, Hubble ingests metadata from Grab’s source platforms in two ways. Source systems either push changes as they happen, or Hubble periodically pulls metadata via Airflow jobs into the central metadata service that exposes GraphQL and REST APIs. Every change is then published to Kafka as metadata events (low-level change logs for indexers and audits, and higher-level semantic events for workflows), keeping Hubble’s search and lineage indices fresh and allowing downstream integrations like certification, deprecation notices, and governance automation to react to metadata changes in near real time.
This architecture is crucial for a data mesh because metadata evolves more rapidly than organizational changes. As domains change, tables are relocated, or pipelines are refactored, Hubble continuously updates, allowing certification to keep pace without the need for manual re-audits.
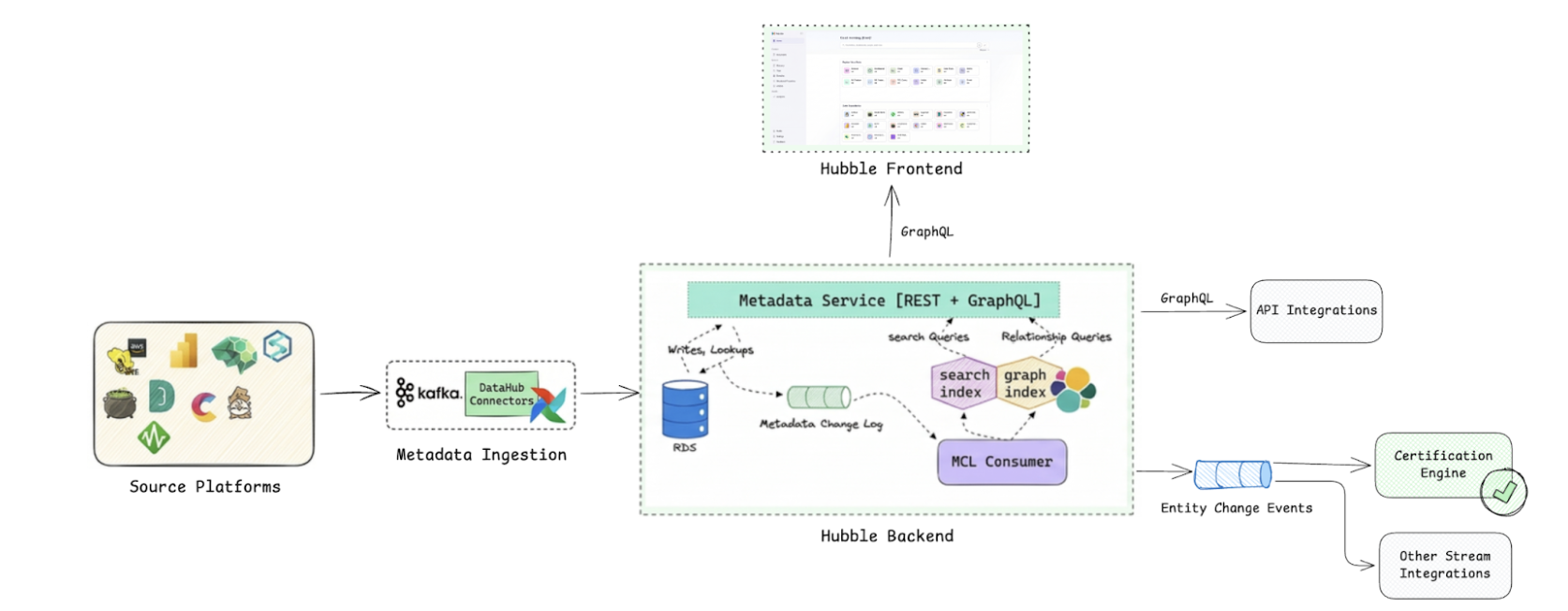
Figure 2. Hubble’s system architecture.
Computational certification via the certification engine on Hubble
A data asset’s certification state is not a manual label, it is computed by an event-driven certification engine built on the DataHub Actions framework. As source platforms for tables, streams, metrics, and user attributes push metadata into Hubble, every change becomes a metadata event. The engine subscribes to these events and re-evaluates the certification state of the data asset based on the predetermined certification criteria.
Conceptually, assets move between four states:
- Uncertified: Never met all criteria.
- Certified: Asset itself meets all required criteria.
- CertifiedPlus: Stricter conditions than Certified, requiring both the asset and all of its upstreams to meet the criteria.
- Revoked: Previously certified but now out of compliance.
The state diagram below captures how assets move between these states as metadata and upstream health change.
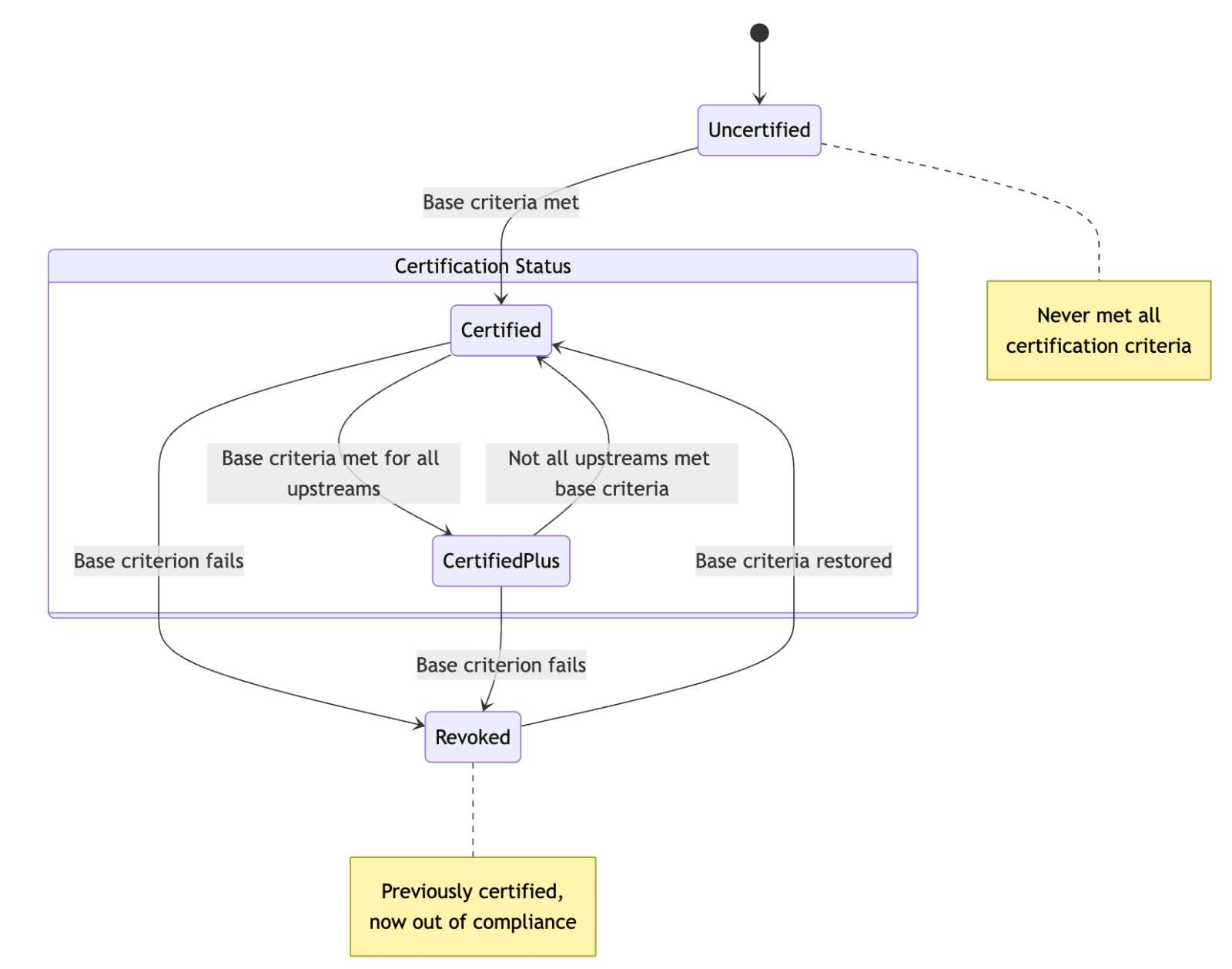
Figure 3. Certification state diagram.
While each asset type can add its own nuances (for example, metrics and attributes may also require explicit endorsement from business data owners), the core certification criteria are consistent:
- Ownership and domain: Clear domain assignment plus accountable technical and business data owners.
- Documentation and semantics: Table/metric documentation and, where relevant, column-level descriptions so consumers understand what the data means.
- Lineage and upstream trust: For stronger levels like CertifiedPlus, upstream lineage must be present, and upstream assets must themselves be certified.
- Contracts and runtime quality: Linked data contracts that spell out expectations, backed by required Genchi tests for freshness, volume/completeness, schema stability, and critical business checks.
- Governance signals: No conflicting deprecation flags or policy violations (for example, missing required classifications on sensitive data).
If an asset satisfies the base criteria, the engine writes a certification aspect back into Hubble and surfaces it as a green tick; if the asset later falls out of compliance, certification is revoked, and downstream assets are re-evaluated as needed. This is because all certification changes are stored as time-series metadata and driven by events rather than a one-off checklist; certification becomes a continuous, metadata-driven process that keeps pace as the entity evolves.
Genchi: The data quality observability layer
Genchi is Grab’s in-house, self-service data quality observability platform. It allows teams to define and run data quality tests on their datasets, receive alerts when something goes wrong, and integrate those tests directly into data contracts so that issues are caught and contained before they impact downstream consumers.
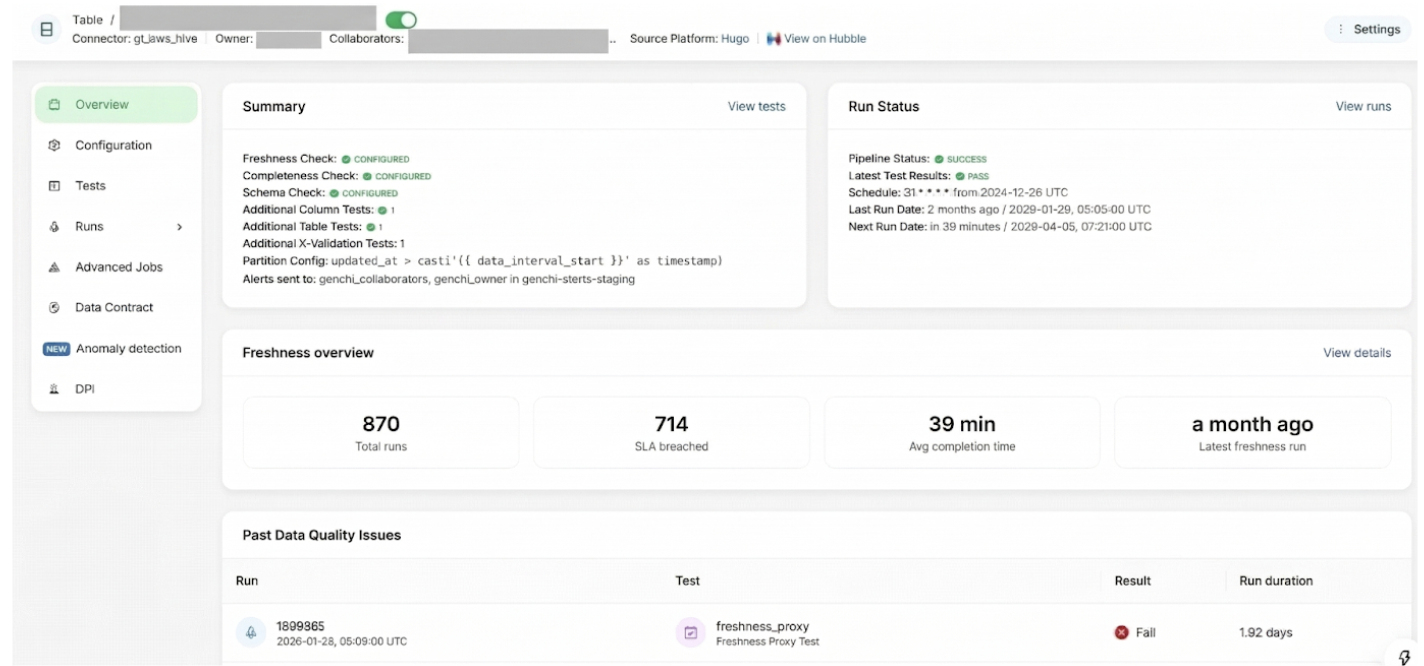
Figure 4. Genchi job configuration page, where dataset owners enroll a table and set up freshness, volume, schema, and other data quality tests for it.
What Genchi does for data mesh
In a data mesh, every domain is responsible for the quality of the data products it publishes. Genchi is the guardrail that makes that responsibility practical at scale. At its core, Genchi turns “good data” into clear, testable pillars that a data asset must satisfy:
- Freshness and timeliness: Is the data recent enough to trust? Genchi runs data freshness and pipeline-freshness checks so owners know when today’s numbers are really “today’s” and can spot delayed loads before they hit dashboards or models.
- Completeness and volume: Are we seeing all the records we expect? Volume and completeness tests compare current loads against historical baselines or source systems to flag partial backfills, silent drops, or suspicious spikes.
- Structural stability (schema): Did the shape of the data change? Schema checks detect added/removed columns and type changes so that teams don’t discover breaking changes only after pipelines or reports start failing.
- Semantic validity (values and business rules): Do the values themselves make sense? Column-level and X-Validation tests enforce constraints like uniqueness, ranges, patterns, cross-table reconciliations, and more advanced anomaly detection on row counts and null percentages.
Wrapped around these pillars is the operational layer:
- Genchi runs these checks continuously (on schedule or on pipeline completion), emits real-time alerts, and helps teams drill into failing records and trends instead of debugging blind.
- Its health signals flow into the catalog and incident tooling, so consumers see quality status alongside metadata and contract breaches are handled consistently.
The result is a mesh where domains publish data products with explicit, machine-enforced quality guarantees, and consumers can safely reuse them without a central team hand-holding every request.
Genchi’s system architecture
The Genchi system is designed to handle validation workflows triggered by user actions or automated schedules. It utilizes Temporal for reliable workflow orchestration and Kafka for event-driven data distribution to downstream consumers.
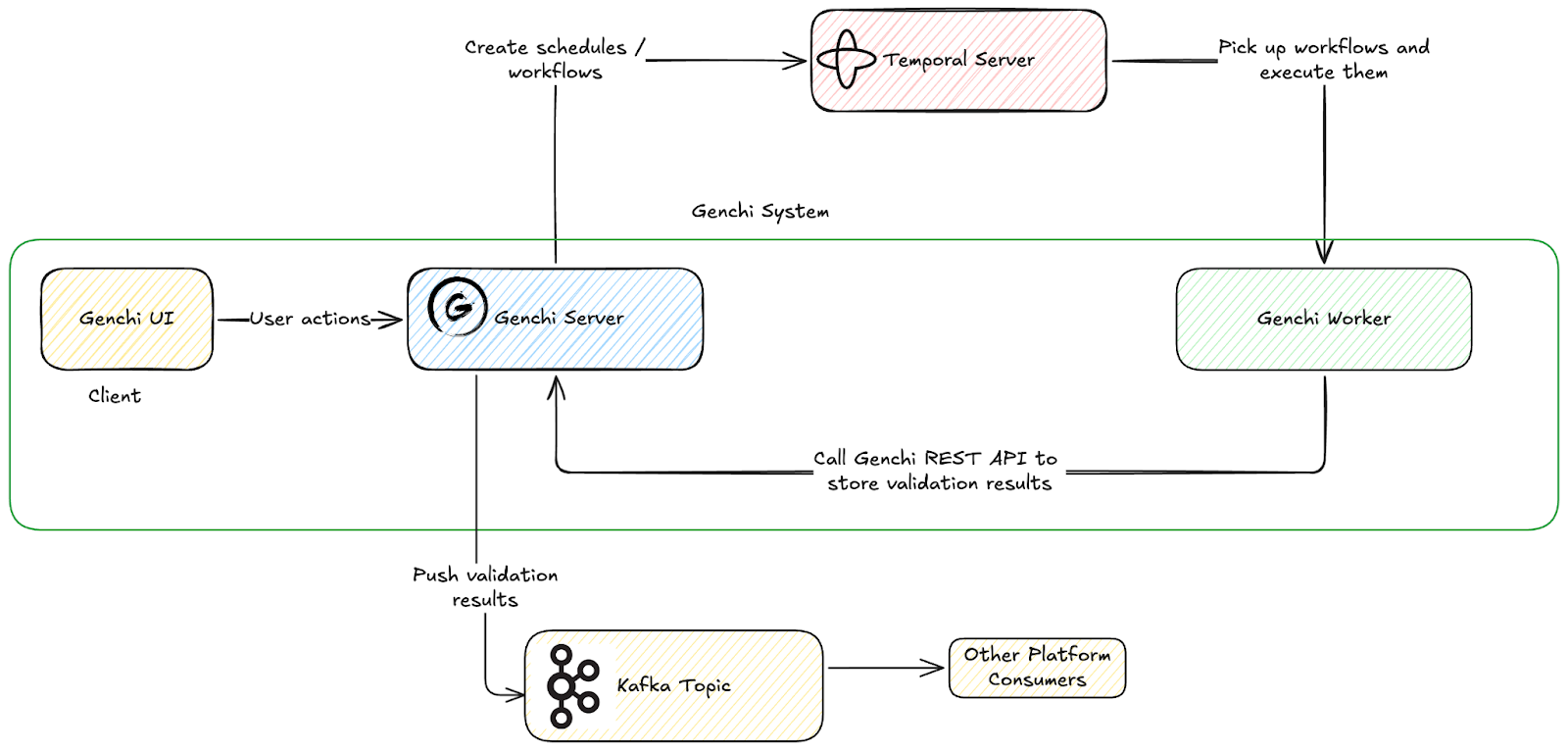
Figure 5. Genchi’s system architecture.
Triggering tests on pipeline completion with Sync with Pipeline (SWP)
Before SWP, Genchi tests lived on their own cron schedules, completely decoupled from the Airflow pipelines that actually produced the data. Teams had to manually copy pipeline crons into Genchi, juggle offset/lookback math to point at the “right” pipeline batch, and hope that nothing drifted over time. The result: misconfigured pipeline duration Service Level Agreement (SLA) checks, and tests sometimes running too early, too late, or against the wrong batch. This leads to noisy alerts and false-positive Data Production Issue (DPI).
To solve this, Genchi leans on Lighthouse, Grab’s pipeline execution and monitoring service. Lighthouse tracks when Airflow jobs start, finish, and which data interval they cover, and exposes that as structured execution events that the rest of the observability stack can consume.
SWP then flips Genchi from “best-effort cron alignment” to event-driven orchestration. Instead of guessing when a pipeline should have finished, Genchi listens to Lighthouse execution events. When a pipeline run is completed, Lighthouse emits an event with the run’s schedule and data interval; Genchi consumes that event, spins up an ad-hoc validation run aligned to that execution, and runs data-quality tests on the corresponding slice of data.
Pipeline-freshness is modeled as its own run type, separate from the data-quality tests that run on pipeline completion. Instead of inspecting rows, it is triggered asynchronously on the same schedule as the pipeline and tracks when each run actually completes in Lighthouse. This gives data producers an intuitive way to get alerted when a pipeline exceeds its expected runtime, and to review historical runtime behavior for any drift over time.
In practice, this makes test orchestration both simpler and more trustworthy. Users no longer need to think about crons or offsets for their data validation jobs. “Run after my pipeline finishes” becomes the default, with advanced overrides for custom schedules when needed. Misconfigured freshness tests and noisy DPIs drop, because Genchi is now anchored to real pipeline execution signals rather than approximations.
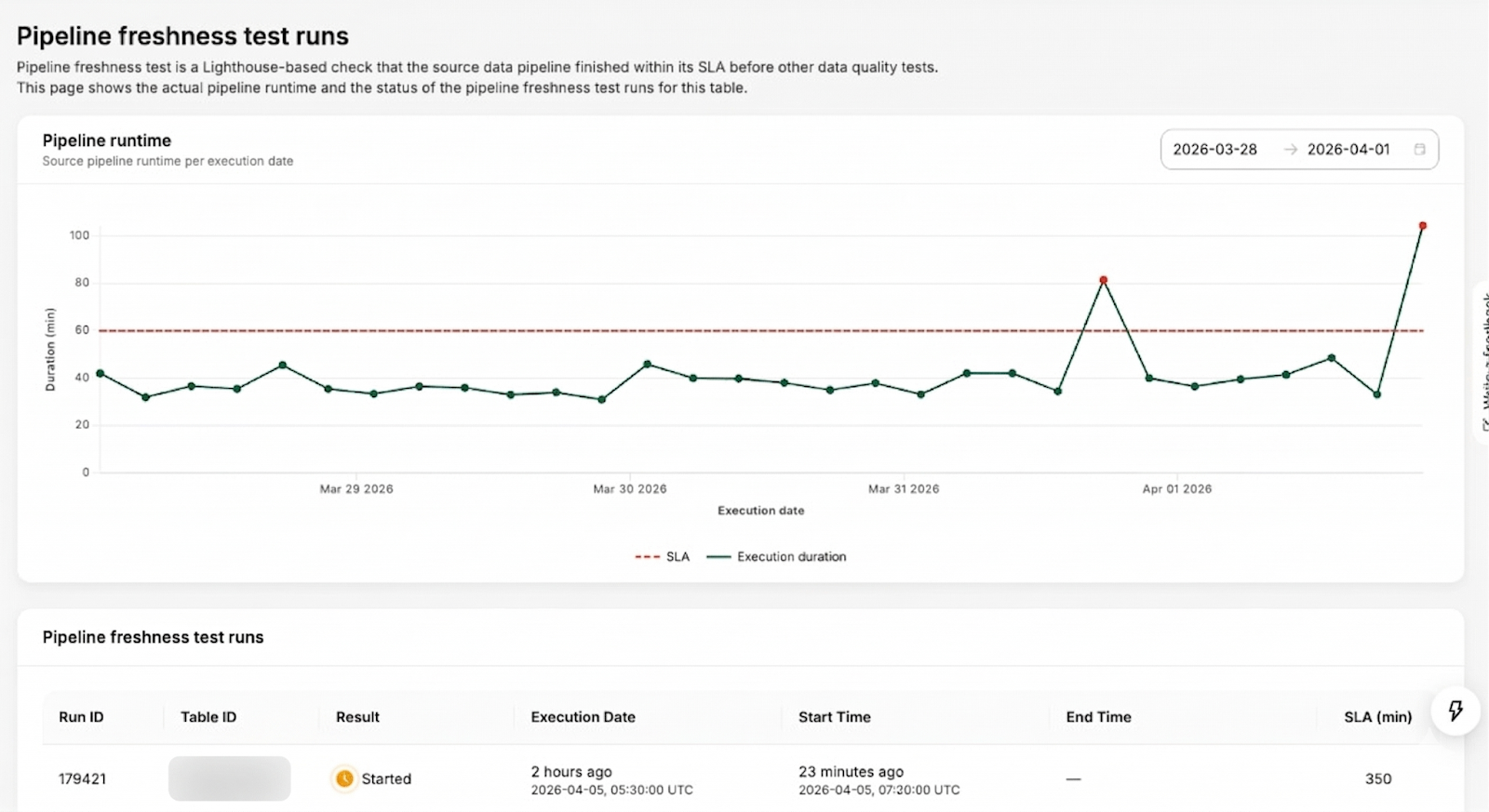
Figure 6. Genchi pipeline-freshness run page for a table, showing the historical runtime patterns and the SLA status.
Data Contract Registry: The producer–consumer agreement layer
At Grab, a data contract is the explicit, versioned agreement between a producer and its consumers that defines the data’s shape and semantics, the quality and availability guarantees around it, and the rules for how and for how long it may be used. The Data Contract Registry is the source of truth for these agreements, while Genchi and platform-specific observability stacks continuously verify that reality still matches what the contract promises.
What Data Contract Registry does for data mesh
Within Grab’s data mesh, the Data Contract Registry is the producer–consumer agreement layer: it centralizes contracts for key assets (data lake tables, Kafka streams, metrics) so expectations on shape, quality, SLAs, and lifecycle live in one canonical place instead of being scattered across individual platforms. That single source of truth underpins Hubble certification (only assets with valid contracts can be certified), gives Kinabalu (Grab’s central incident lifecycle orchestrator) the context it needs to open and route DPIs when checks fail, and lets Ouroboros (a table lifecycle management tool) interpret lifecycle clauses consistently.
This is important for a data mesh because it transforms the concept of “data as a product” from a mere slogan into an operational reality. Contracts provide domain teams with a clear and enforceable method to specify their guarantees, offering consumers a solid foundation for trust and data reuse across domains. Importantly, a contract is only valuable if its promises are verifiable and enforceable. Schema expectations, quality checks, and SLAs are all connected to concrete tests and health endpoints, enabling downstream platforms to automatically detect breaches and manage or mitigate breaking changes, rather than treating the contract as static documentation.
On top of storing contracts, the registry also manages contract changes. When a contract evolves, say a schema tweak, a new freshness SLA, or a planned deprecation, it identifies the right stakeholders (direct downstream owners, heavy query users, and, for critical assets, deeper dependencies) and pushes targeted Slack notifications. Producers get a structured way to roll out changes safely while consumers get timely, actionable signals instead of surprise breakages so that both enforcement and change management are baked into the mesh.
In addition to storing contracts, the registry also manages contract changes. When a contract evolves such as a schema adjustment, a new freshness SLA, or a planned deprecation, it identifies the appropriate stakeholder (direct downstream owners, heavy query users, and critical assets with deeper dependencies) and then sends targeted Slack notifications to these stakeholders. This process provides producers with a structured method to implement changes safely, while consumers receive timely and actionable alerts, preventing unexpected disruptions. As a result, both enforcement and change management are seamlessly integrated into the data mesh.
The data contract specification
Under the hood, a data contract in the registry is a JSON construct that follows the contract specification. Grab’s data contract specification is inspired by the public Data Contract Specification, but adapted to our environment so that contracts plug directly into our observability stack and automated incident management workflows.
Notably, we embed data health and test health URLs in the contract itself. Each data-quality rule points to a concrete health endpoint, so Kinabalu can determine contract breaches and create DPIs by calling those test health URLs, without hard-coding what “healthy” means. For example, a completeness test on the latest partition can be marked healthy only if the last N days are complete, not just because the most recent test run happened to pass. The data health URL at the contract root then lets Kinabalu fetch the overall diagnosis and decide who the DPI should be assigned to. More on this will be covered in Part III.
Here’s a simplified example of a contract for a data-lake table:
{
"specification_version": 1,
"asset_urn": "urn:li:dataset:(urn:li:dataPlatform:hive,genchi.validation_jobs,PROD)",
"entity_type": "datalake_table",
"health_url": "https://example-hugo.grab.com/assets/genchi.validation_jobs/health",
"contract_details": {
"contact": {
"oncall_group": "oncall-genchi",
"slack_channel": "ask-genchi"
},
"terms": {
"usage": "Source of truth for all genchi validation jobs.",
"limitations": "Not suitable for real-time use cases.",
"notice_period_in_days": 14
},
"schema": [
{
"type": "genchi",
"health_url": "https://example-genchi.grab.com/assets/genchi.validation_jobs/tests/fundamental_schema_test/health",
"uid": "fundamental_schema_test",
"version": 1
}
],
"sla": {
"freshness": [
{
"type": "genchi",
"health_url": "https://example-genchi.grab.com/assets/genchi.validation_jobs/tests/fundamental_freshness_test/health",
"uid": "fundamental_freshness_test",
"version": 1
}
],
"lifecycle": null
},
"data_quality": [
{
"type": "genchi",
"health_url": "https://example-genchi.grab.com/assets/genchi.validation_jobs/tests/fundamental_completeness_test/health",
"uid": "fundamental_completeness_test",
"version": 1
}
]
}
}
The contract in the registry only stores references to enforceable rules, which are an identifier and version, like the example above, rather than the full configuration body. This keeps contracts lightweight and tool-agnostic, while giving rule-enforcement tools (Genchi for data-quality tests, Ouroboros for table lifecycle) and Kinabalu a stable handle to resolve the actual rule definition in their own systems, without duplicating configuration or letting it drift across platforms.
Conclusion
By bringing Hubble, Genchi, and the Data Contract Registry together, we provide the foundational tools to build trust in certified data assets. Hubble enables discovery and establishes domains and ownership; the Data Contract Registry captures explicit expectations between producers and consumers; and Genchi continuously validates those promises with tests on freshness, volume, schema, and business rules. Hubble’s certification engine then evaluates these ownership, contract, and quality signals to decide whether an asset meets Grab’s standards and surfaces that as a visible certification state. As a result, consumers can confidently default to certified assets, usage converges on a smaller, better-governed pool of datasets, and certification becomes a mechanism that changes producer behavior and guides consumer choice. We saw this convergence in practice. In just one year since the Signals Marketplace campaign began in 2024, the number of P80 datasets (the most used tables that account for 80% of all queries) has dropped by over 58%.
This data foundation is especially important in an AI-first future for Grab. Certified streams, tables, metrics, and attributes give AI agents and automated analytics a default substrate they can rely on. With Hubble and Genchi, data producers have clear ownership, contracts, and observability. Data consumers can discover and trust certified assets without guesswork, and platform teams can measure and improve Signals Marketplace health over time (for example, queries on certified assets, lineage depth, and cost). Together, these capabilities turn “data mesh” from a slogan into an operational, AI-ready marketplace of reliable, reusable signals that power decisions across Grab.
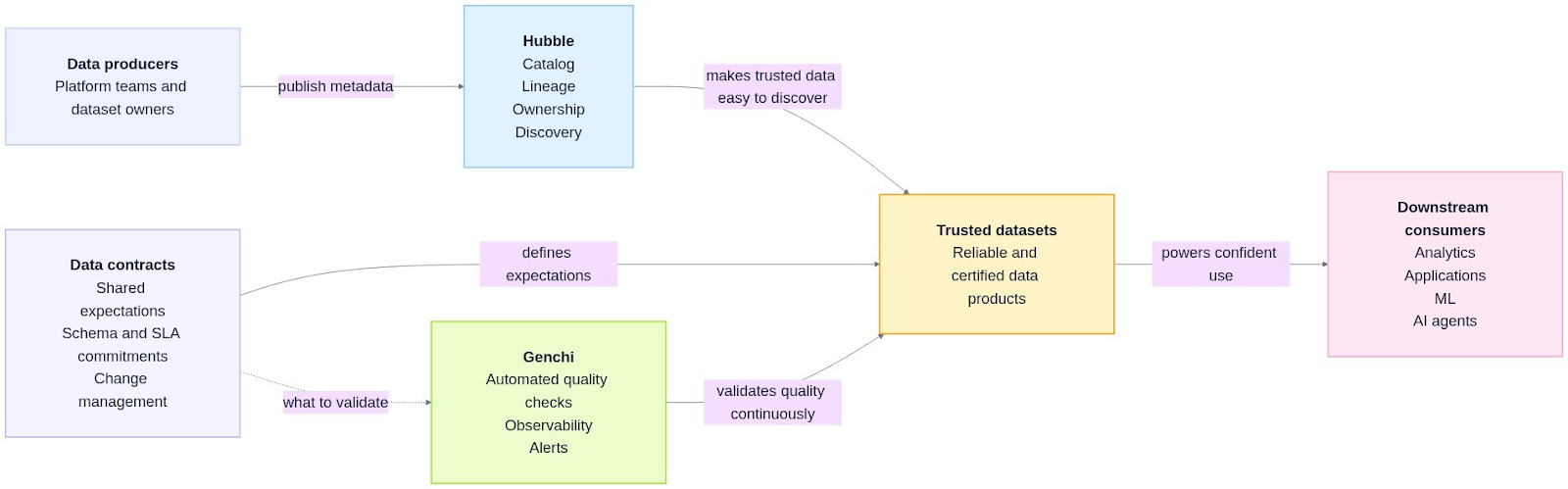
Figure 7. Building trust in certified data assets through discovery, contracts, and continuous validation.
What’s next
In the next blog, we’ll zoom into the DPI process itself with Kinabalu as the incident lifecycle orchestrator:
- How Genchi test failures and data contract breaches turn into DPIs.
- How DPI is assigned based on root causes and what sets the priority level.
- The patterns we’ve seen in “noisy” vs actionable DPIs, and what we’ve changed in our platforms.
- How we’re using automation and agents to reduce DPI toil and close the loop back into certification.
We’ll walk through concrete case studies showing how a single broken table moves from first failure, to diagnosis and fix, to updated contracts and a more resilient certified data asset.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility, and digital financial services sectors, serving over 900 cities in eight Southeast Asian countries: Cambodia, Indonesia, Malaysia, Myanmar, the Philippines, Singapore, Thailand, and Vietnam. Grab enables millions of people every day to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. We operate supermarkets in Malaysia under Jaya Grocer and Everrise, which enables us to bring the convenience of on-demand grocery delivery to more consumers in the country. As part of our financial services offerings, we also provide digital banking services through GXS Bank in Singapore and GXBank in Malaysia. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line. We aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!