Slashing CI Wait Times: How Pinterest Cut Android Testing Build Times by 36%+
[
George Kandalaft | Software Engineer II, Test Tools; Alice Yang | Staff Software Engineer, Test Tools
Press enter or click to view image in full size
TL;DR
Problem Statement
Our Android end-to-end testing builds in CI were slow and flaky because the test shards were unbalanced and the entire build had to wait for the single slowest shard on a third-party testing platform.
Solution
We built a runtime-aware sharding mechanism that uses historical test duration and stability data to pack tests greedily in an in-house testing platform with EC2-hosted emulators, ensuring all shards have a similar total runtime.
Impact
The end-to-end build time was reduced by 9 minutes (a 36% improvement), decreased the slowest shard’s runtime by 55%, and compressed the time difference between the fastest and slowest shards from 597 seconds to just 130 seconds.
Introduction
At Pinterest, one of the Test Tools team missions is to save engineers time across development, testing, and shipping. Delivering on that mission requires fast, reliable feedback for our end-to-end (E2E) testing pipelines. As our app and test suites have grown, we faced a familiar challenge: how do we keep E2E tests fast and reliable as test volume and complexity rise in CI?
Our Android E2E tests run on emulators and devices that exercise real user flows. In CI, we traditionally split these suites into shards by package names. The test run and parallelism were managed by Firebase Test Lab (FTL) based on the packaged sharding. This type of sharding created imbalance: some shards finished quickly while others dragged on — so the slowest shard gated the build.
To make feedback predictable and fast, we moved to time-based sharding with a new in-house testing platform and infrastructure. Using historical runtimes, we assign tests so each shard takes roughly the same time, not merely the same count of tests. This post explains how we built in-house time-based sharding for Android at Pinterest, how we handle flaky tests, and how the change reduced build latency and improved developer velocity.
Key terms we’ll use
- Emulator: a virtual Android device used to run tests in CI.
- Shard: a batch of tests that runs in parallel with other shards.
- Time sharding: assigning tests to shards using historical runtimes so all shards finish around the same time.
- Flaky test: a failed test passes in retries without code changes.
Why Build an In-House Testing Platform?
The Challenges Encountered with FTL
Before we could optimize our testing sharding, we needed to re-evaluate our testing execution environment. With FTL, there were some challenges. Each test run incurred a baseline setup time of five to six minutes. As our test suites grew and flaky tests required retries, this setup overhead became a significant portion (> 50%) of the total build duration.
Additionally, FTL infrastructure flakiness and instability started early 2023 blocked developer productivity one to two times per week on average, with each outage causing three to four hours of downtime and halting all code merges. There were no near term solutions provided by Google.
Evaluating the Market for an Alternative
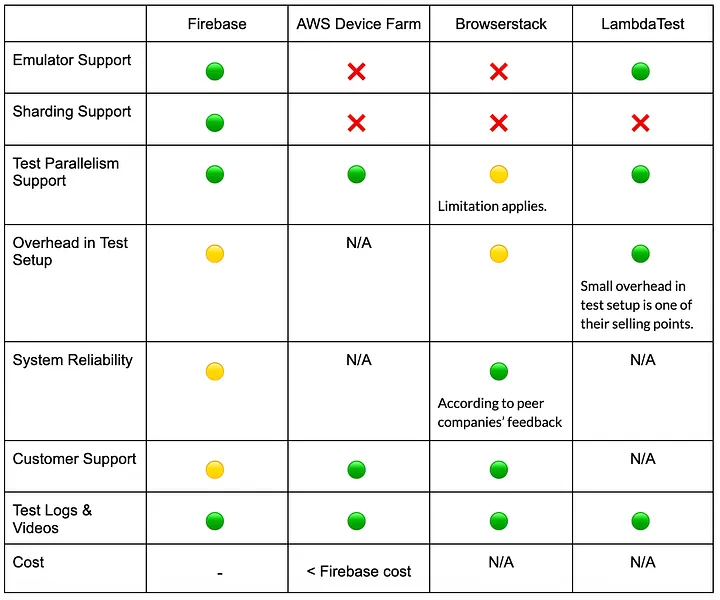
One of the first steps we took was to evaluate the vendor market for an alternative solution. The goal was to find a third-party solution that offers high reliability, low setup overhead, and massive parallelism on both emulators and physical devices. Emulator support is especially important as it offers much better cost and performance efficiencies for our large-scale test suite.
However, the vendor evaluation showed that the available solutions did not fully align with our requirements for large-scale, native emulator support. We found out that even with an alternative vendor, we would still need to build and maintain our own custom test orchestration and sharding mechanism. Below is a list of the critical acceptance criteria we had during the evaluation.
Press enter or click to view image in full size
The Decision to Build A Path to Deeper Innovation
Based on the analysis, we concluded that building an in-house testing platform was the most direct path to solve the root cause of the problem to improve developer velocity and experience. Through conversations with peer companies who had successfully built their own Android testing platform, and an internal proof-of-concept, we’ve seen feasibility and promising performance gains.
This led to the creation of PinTestLab, Pinterest’s in-house Android E2E testing solution that runs on EC2-hosted Emulators. This gave us direct control over the entire testing stack, from docker images, emulator configurations, error logging, and sharding.
Infrastructure and Resource Allocation
A smart sharding algorithm is only as effective as the infrastructure it runs on. Building PinTestLab required a stable and efficient foundation. This involves a solid proof-of-concept (POC) to identify the right instance type, followed by iterative optimization to maximize resource utilization.
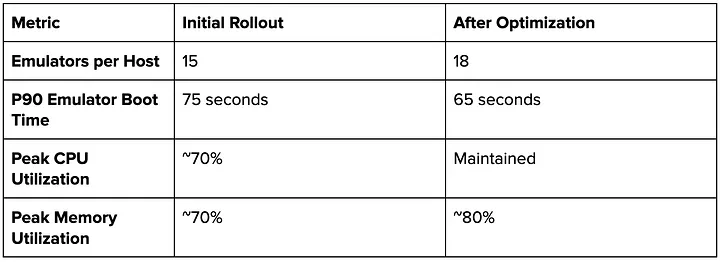
Our initial POC explored running Android emulators on standard, virtualized EC2 instances (x86 architecture) inside a docker image. It revealed significant performance bottlenecks. A switch to bare-metal instances immediately resolved these issues, as shown by the drastic improvements in emulator boot time and test time.
Press enter or click to view image in full size

We also briefly investigated using ARM-base bare-metal instances but encountered significant tooling friction and kernel panics during emulation.
Based on these findings, we selected c7i.metal-24xlarge instances for all test executions. Our initial rollout established a baseline, which we later improved through resource allocation optimization to our docker image. This enhancement, combined with the improved load distribution from time-based sharding, allowed us to better utilize host resources and increase peak memory usage to 80%.
Press enter or click to view image in full size
How We Ran Tests Before, and Why We Changed
In December 2024 we launched PinTestLab minimum viable product (MVP). We wanted to cut external flakiness and regain control over device images, scheduling, and retries — while keeping engineers’ CI/CD flow in Buildkite.
For the MVP, we kept orchestration simple. Buildkite YAML defined the end‑to‑end test run. A Python orchestrator spun up one emulator per shard, ran a pre‑assigned test list, uploaded artifacts, and then shut the emulator down. Sharding used a uniform round‑robin split by test count, with package‑based splits as a baseline. We recorded per‑shard timings and outcomes as Buildkite artifacts and sent events to an observability platform to spot skew and outliers, and we added conservative shard‑level retries. This gave us stable runs under our control.
In FTL we split tests by package: all tests within a single package were grouped together and put into one shard. This was slow, and some packages containing long running or resource intensive tests took too long to finish, increasing total build time. We decided to move away from this toward a more balanced approach.
The first version kept things simple: scan the repo, divide the same total number of tests into shards round‑robin by count, and generate Buildkite steps to execute them. It worked, but shard durations were uneven: across 17 shards we saw P90 runtimes from roughly 8.8 to 13 minutes, which meant one long shard often gated the entire build. Our goal was to tighten that spread so that the “tail” stopped owning the overall time.
The Goal: Equal Wall‑Time, Not Equal Number of Tests
Two practical constraints shape how we do this:
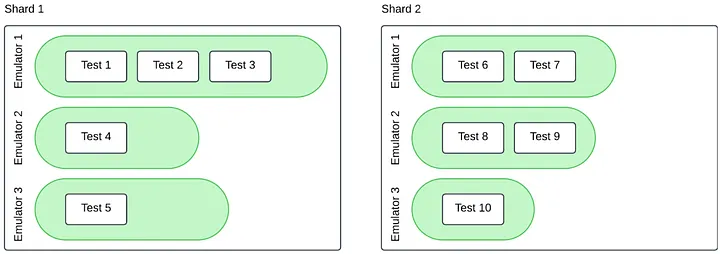
- Multiple emulators per shard: Each shard runs several emulators in parallel, and each emulator runs a list of tests assigned in sequence. Some emulators may finish their job minutes before the others depending on the distributed tests.
- Test Flakiness and retries: Which add time that isn’t accounted for.
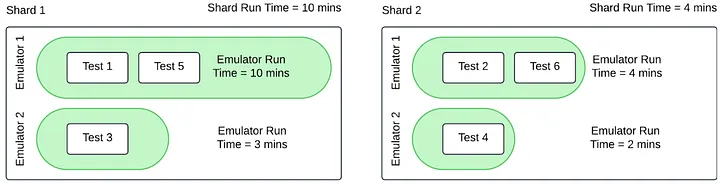
That’s why equal test counts per shard can still be slow. In the example, Shard 1 bunches three tests on one emulator while two emulators sit idle, so the shard’s wall‑time is dragged out by that single busy emulator and any retry there makes it worse. Shard 2 spreads work across emulators, so it finishes sooner even with the same number of tests.
Press enter or click to view image in full size
Why “Sort + Round‑Robin” Still Fails
For PinTestLab, we kept orchestration simple at first, so we split tests with a round‑robin approach. It was better than the old package‑based splits, but still not ideal. This six test example made it obvious.
Press enter or click to view image in full size
You get Shard_1 = [test_1, test_3, test_5] and Shard_2 = [test_2, test_4, test_6]. Inside the shard, the scheduler runs tests on two emulators; Shard_1 ends up with one emulator running for 10=6+4 minutes, while the other finishes a single 3 minute test and sits idle. Shard_1 takes 10 minutes, and Shard_2 takes 4 minutes. Even though we “balanced” by test count and total time looks fine on paper, one emulator in one shard becomes the straggler, causing a total build time of at least 10 minutes.
Press enter or click to view image in full size
Takeaway One
Even with equal test counts per shard, one emulator in shard_1 becomes the straggler, so total build time is ≥ 10 minutes. Round‑robin balances lists.
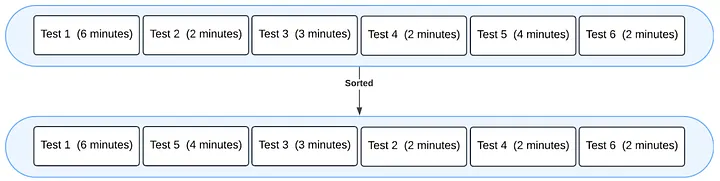
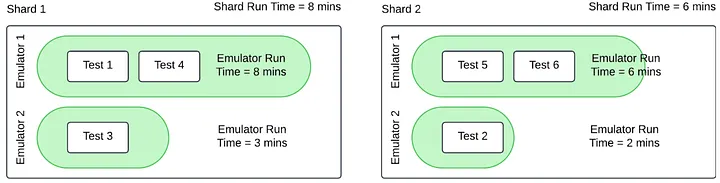
Attempt 2: Sort, then round‑robin
Sorted tests by expected time: [6, 4, 3, 2, 2, 2] → [test_1, test_5, test_3, test_2, test_4, test_6] Shards (round‑robin after sort):
- Shard 1: [test_1, test_4, test_3]
- Shard 2: [test_5, test_6, test_2]
Press enter or click to view image in full size
Press enter or click to view image in full size
Takeaway Two
Sorting reduces the skew (8 vs. 10 minutes) but still leaves idle time on the second emulator in each shard and a longer shard that gates the build.
The Insight We Shipped: Runtime‑Aware Sharding
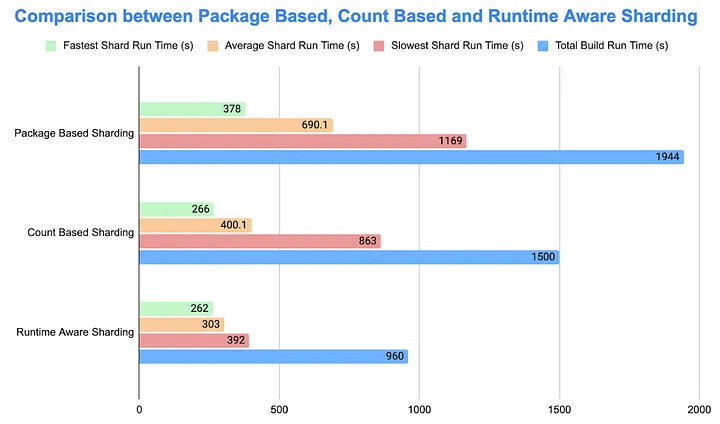
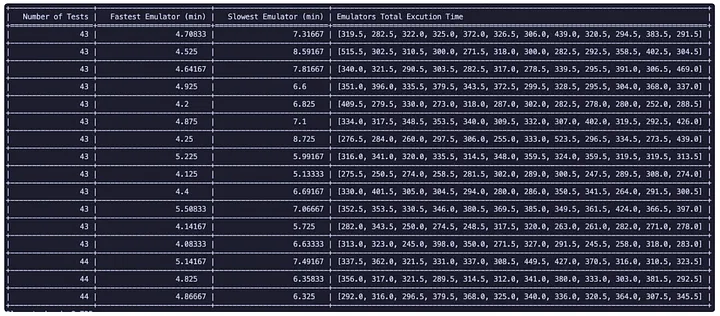
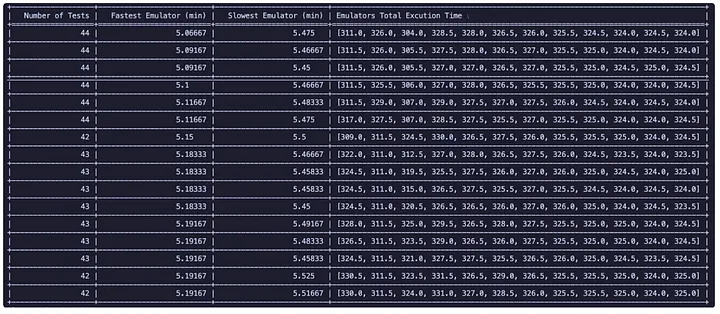
We decided to develop a runtime-aware sharding, and we had a promising first run. The numbers speak for themselves. Under round-robin sharding, our slowest shard took 522 seconds, while the fastest finished in just 246 seconds. A 276-second spread meant developers waited for the tail every time.
With time-based sharding using p90 duration as our metric, we compressed that spread to just 28 seconds (5.6 vs 5.1 minutes). In practice, this meant cutting typical CI feedback from nearly 9 minutes down to about 5.5 minutes; this is a significant boost to developer velocity.
Round-robin
Press enter or click to view image in full size
Runtime-aware Sharding
Press enter or click to view image in full size
To address the timing imbalance, we leveraged historical runtime data stored in Metro, Pinterest’s test management system. Metro tracks test results, trends, ownership, and build history, while allowing engineers to debug test failures and take actions, such as quarantine flaky tests when necessary.
Using this rich historical data, we developed a greedy, runtime-aware allocation algorithm. The approach is straightforward: we sort tests by a robust performance metric (such as the average duration), add a small per-test overhead to account for setup costs, then pack tests into shards using a greedy strategy. Each test gets assigned to whichever emulator is projected to finish earliest, keeping all execution emulators busy and ensuring emulators within each shard complete at roughly the same time. This approach reduces tail latency without adding complexity to our CI orchestration.
Our initial implementation created a minimal runtime-aware sorter that ran entirely within Buildkite. We added a step that fetched historical data from Metro for the current test suite, calculated average runtimes based on the past x runs from the pipeline, then used a min-heap data structure to continuously assign the next test to the shard expected to finish first.
We schedule tests using a simple, fast heuristic. Let N be the number of tests and M be the number of emulators. We first sort tests by descending average runtime, then assign each test to the currently least loaded emulator using a min-heap. This is the classic Longest Processing Time (LPT) rule for identical machines: it isn’t guaranteed to be optimal, but it’s well suited to our CI. Computing the exact optimum is NP-hard and impractical at our scale, while LPT runs in O(N log N + N log M), scales cleanly across shards×emulators, and delivers near‑optimal finish times in practice. Given runtime estimates and the need for predictable, low‑overhead scheduling, we favor effectiveness, simplicity, and operational reliability over theoretical optimality.
Why this works well for us:
- Predictable runtime with a small implementation surface
- Fast enough to run on every commit and resilient to minor runtime noise
- Easy to reason about and monitor thanks to a simple heap invariant
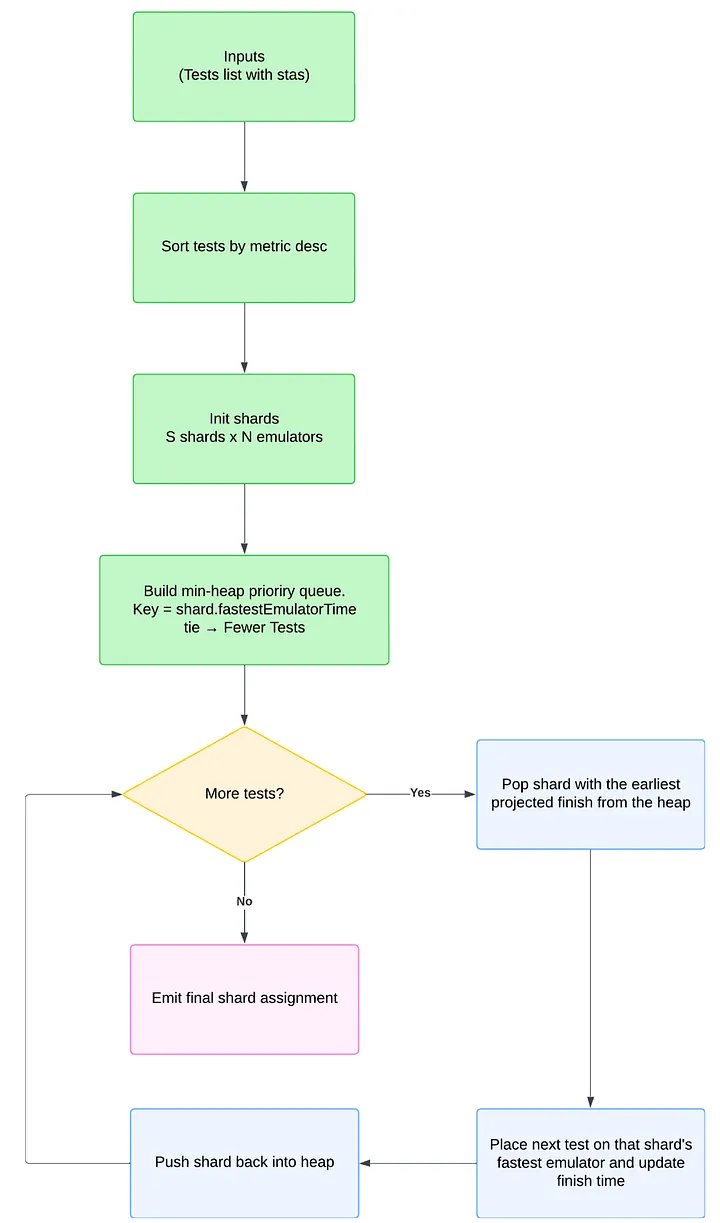
How the algorithm works (step-by-step):
-
Estimate runtime per test from recent history
-
Sort tests by adjusted runtime, descending
-
Initialize the min-heap with k entries (finish_time=0, shard_id)
-
For each test:- Pop the shard with the earliest projected finish_time- Assign the test to that shard- Update finish_time += test_runtime and push back into the heap
- The maximum finish_time across shards approximates total suite duration
Press enter or click to view image in full size
Why is this?
- Predictable runtime and small implementation surface
- Fast enough to run on every commit, robust to minor runtime noise
- Easy to reason about and monitor (simple heap invariant)
Expanding Beyond Post Commit
To scale beyond post-commit, we decoupled our sharding algorithm from the pipeline. Because we already had rich historical data in the Metro, we built the solution there to be reusable for any testing pipelines. Given a list of tests plus the desired number of shards and emulators, the system computes an optimal sharding plan and estimates the fastest and slowest shard, as well as the fastest and slowest emulator if applicable. It also tracks prediction accuracy over time, so we can both forecast performance and measure how well those forecasts hold up.
ALGORITHM: Runtime-Aware Test AllocationINPUT: - tests: List of test cases - num_shards: Number of available shards - num_of_emulators: Number of available emulators - per_test_overhead: Setup cost per test (constant)OUTPUT:
- shard_assignments: Map of shard_id -> List of tests
This allowed us to use Metro as a brain given that we already have the tests duration in Metro. In addition, it also provided us with a rough estimate for the slowest and fastest shard giving us insights on the overall run time of the build.
Other Options Considered: On‑Demand Sharding
We also explored a second path: on‑demand sharding driven by a message queue. This would let emulators pull work dynamically rather than running a precomputed test list. It’s promising, but it requires a separate proof of concept with third party dependencies evaluation.
How It Would Work at a High Level
We introduce an SQS layer to dispatch individual tests and create logical queues keyed by build_id and device_type so each build and device family is isolated.
Each shard spins up N emulators; every emulator becomes an SQS consumer. Instead of a static list, emulators fetch test messages on demand. For each message, the consumer asks Metro whether the test is already done (passed) or has failed out by hitting the retry limit. If neither, the emulator runs the test. On success, the consumer deletes the message from SQS. On failure, it re‑enqueues the test with retry metadata (attempt count, last error, backoff hints) so another consumer can pick it up later.
This push‑pull model keeps emulators busy and naturally shifts capacity toward longer or flaky tests during the run.
Trade‑Offs and Decision
We chose time‑based sharding for the best ROI at the moment, as it already serves the purpose and meets (and exceeds) our expectations: tightening tail latency with minimal orchestration changes. It offers lower uncertainty and an existing prototype, reducing implementation risk and operational overhead. On‑demand sharding remains a viable next step: if our test mix becomes more skewed, or we need finer‑grained elasticity and targeted retries at very large scale, we can integrate Metro with SQS and pilot dynamic dispatch behind a feature flag. For now, runtime‑aware sharding provides predictable, fast feedback with a smaller blast radius and simpler operations.
Reflections
Wins
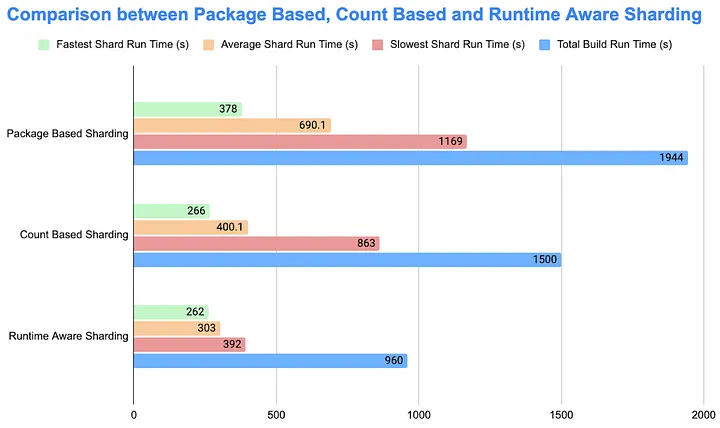
To measure impact, we ran two builds in parallel to capture up‑to‑date results. Compared with sorted count‑based sharding, runtime‑aware sharding reduced the slowest shard from 863s to 392s (−54.6%), lowered average shard time from 400.1s to 303s (−24.3%), and cut total build time by about nine minutes (−36%). Bottom line: runtime‑aware sharding shortens end‑to‑end build time by roughly nine minutes while cutting tail latency by about 55%.
Press enter or click to view image in full size

Press enter or click to view image in full size
Learns
- Always ship with a graceful fallback (round‑robin) to preserve developer trust. During Metro outages, the sharding mechanism automatically falls back to a round‑robin algorithm based on the tests retrieved from the repository within the testing pipeline.
- Budget for newly added tests and account for silenced tests in planning. When a test has no historical data, assume the worst case — for example, assign it the maximum expected runtime — until sufficient data is collected.
- When planning, prefer averages to p90s because flakiness inflates tail metrics and misbalances shards.
Future Enhancements and Expansion
- Explore on demand sharding for more balanced execution times
- Expand the solution to other testing pipelines reporting to Metro
- Dynamic infrastructure resources allocation based on the predicted execution run time
Acknowledgement
Kudos to everyone involved! Among them:
- David Chang for Android infrastructure and general Android domain consultation, Jesus Antonio Huerta, Blake Martinez for their code contributions and code reviews.
- Darsh Patel, Krishna Pandian for their timely support and prioritization with Buildkite infrastructure capacity and stability.
- Eric Kalkanger for validating the instance type and ensuring the availability of EC2 instances.
- Sha Sha Chu, Vani Kumar, Manuel Nakamurakare, Jiawei Shi and Roger Wang for all the support of the project.
- David Chang, Wei Hou and Jiawei Shi for reviewing the blog post.
Join the Conversation
Building a fast and reliable CI/CD pipeline is a continuous journey. What challenges have you faced with test parallelization in your organization? Share your thoughts or questions in the comments below!