From Static Rate Limiting to Adaptive Traffic Management in Airbnb’s Key-Value Store
[

How Airbnb hardened Mussel, our key-value store, with smarter traffic controls to stay fast and reliable during traffic spikes.
Press enter or click to view image in full size

By Shravan Gaonkar, Casey Getz, Wonhee Cho
Introduction
Every request lookup on Airbnb, from stays, experiences, and services search to customer support inquiries ultimately hits Mussel, our multi-tenant key-value store for derived data. Mussel operates as a proxy service, deployed as a fleet of stateless dispatchers — each a Kubernetes pod. On a typical day, this fleet handles millions of predictable point and range reads. During peak events, however, it must absorb several-fold higher volume, terabyte-scale bulk uploads, and sudden bursts from automated bots or DDoS attacks. Its ability to reliably serve this volatile mix of traffic is therefore critical to both the Airbnb user experience and the stability of the many services that power our platform.
Given Mussel’s traffic volume and its role in core Airbnb flows, quality of service (QoS) is one of the product’s defining features. The first-generation QoS system was primarily an isolation tool. It relied on a Redis-backed counter, client quota based rate-limiter, that checked a caller’s requests per second (QPS) against a configurable fixed quota. The goal was to prevent a single misbehaving client from overwhelming the service and causing a complete outage. For this purpose, it was simple and effective.
However, as the service matured, our goal shifted from merely preventing meltdowns to maximizing goodput — that is, getting the most useful work done without degrading performance. A system of fixed, manually configured quotas can’t achieve this, as it can’t adapt in real time to shifting traffic patterns, new query shapes, or sudden threats like a DDoS attack. A truly effective QoS system needs to be adaptive, automatically exerting prioritized backpressure when it senses the system has reached its useful capacity.
To better match our QoS system to the realities of online traffic and maximize goodput, over time we evolved it to add several new layers.
- Resource-aware rate control (RARC): Charges each request in request units (RU) that reflect rows, bytes, and latency, not just counts.
- Load shedding with criticality tiers: Guarantees that high-priority traffic (e.g., customer support, trust and safety) stays responsive when capacity evaporates.
- Hot-key detection & DDoS mitigation: Detects skewed access patterns in real time and then shields the backend — whether the surge is legitimate or a DDoS burst — by caching or coalescing the duplicate requests before they reach the storage layer.
What follows is an engineer’s view of how these layers were designed, deployed, and battle-tested, and why the same ideas may apply to any multi-tenant system that has outgrown simple QPS limits.
Press enter or click to view image in full size
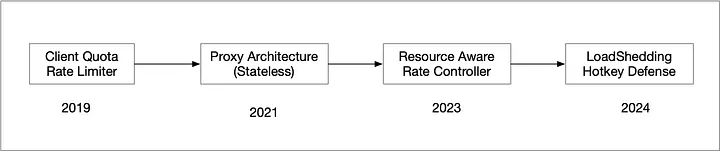
Progression Timeline
Background: Life with Client Quota Rate Limiter
When Mussel launched, rate-limiting was entirely handled via simple QPS rate-limiting using a Redis-based distributed counter service. Each caller received a static, per-minute quota, and the dispatcher incremented a Redis key for every incoming request. If the key’s value exceeded the caller’s quota, the dispatcher returned an HTTP 429. The design was simple, predictable, and easy to operate.
Two architectural details made this feasible. First, Mussel and its storage engine were tightly coupled; backend effort correlated reasonably well with the number of calls at the front door. Second, the traffic mix was modest in size and variety, so a single global limit per caller rarely caused trouble.
As adoption grew, two limitations became clear.
- Cost variance: A one-row lookup and a 100,000-row scan were treated equally, even though their load on the backend differed by orders of magnitude. The system couldn’t distinguish high-value cheap work from low-value expensive work.
- Traffic skew: Per-caller rate limits provided isolation at the client level, but were blind to the data’s access pattern. When a single key became “hot” — for example, a popular listing accessed by thousands of different callers simultaneously — the aggregate traffic could overwhelm the underlying storage shard, even if each individual caller remained within its quota. This created a localized bottleneck that degraded performance for the entire cluster, impacting clients requesting completely unrelated data. Isolation by caller was insufficient to prevent this kind of resource contention.
Addressing these gaps meant shifting from a request-counting mindset to a resource-accounting mindset and designing controls that reflect the real cost of each operation.
Resource-aware rate control
A fair quota system must account for the real work a request imposes on the storage layer. Resource-aware rate control (RARC) meets this need by charging operations in request units (RU) rather than raw requests per second.
A request unit blends four observable factors: fixed per-call overhead, rows processed, payload bytes, and — crucially — latency. Latency captures effects that rows and bytes alone miss: two one-megabyte reads can differ greatly in cost if one hits cache and the other triggers disk. In practice, we use a linear model. For both reads and writes, the cost is:
RU_read = 1 + w_r × bytes_read + w_l × latency_ms
RU_write = 6 + w_b × bytes_written / 4096 bytes + w_l × latency_ms
Weight factors w_r, w_b, and w_l come from load-test calibration
based on the compute, network and disk I/O.
bytes_read, bytes_written and latency is measured per request
Although approximate, the formula separates operations whose surface metrics look similar yet load the backend very differently.
Press enter or click to view image in full size
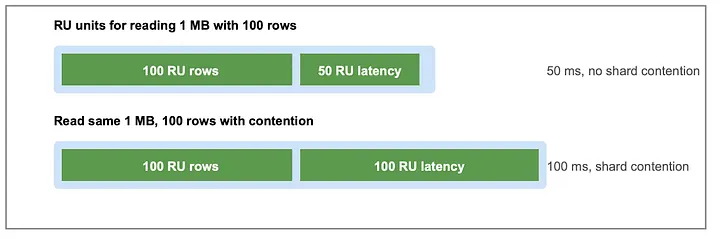
Impact of Latency on RU computation
Each dispatcher continues to rely on rate-limiter for distributed counting, but the counter now represents request-unit tokens instead of raw QPS. At the start of every epoch, the dispatcher adds the caller’s static RU quota to a local token bucket and immediately debits that bucket by the RU cost of each incoming request. When the bucket is empty, the request is rejected with HTTP 419. Because all dispatchers follow the same procedure and epochs are short, their buckets remain closely aligned without additional coordination.
Adaptive protection is handled in the separate load-shedding layer; backend latency influences which traffic is dropped or delayed, not the size of the periodic RU refill. This keeps rate accounting straightforward — static quotas expressed in request units — while still reacting quickly when the storage layer shows signs of stress.
Load shedding: Staying healthy when capacity evaporates or develops hotspots
Rate limits based on request units excel at smoothing normal traffic, but they adjust on a scale of seconds. When the workload shifts faster — a bot floods a key, a shard stalls, or a batch job begins a full-table scan — those seconds are enough for queues to balloon and service-level objectives to slip. To bridge this reaction-time gap, Mussel uses a load-shedding safety net that combines three real-time signals: (1) traffic criticality, (2) a latency ratio, and (3) a CoDel-inspired queueing policy.
The latency ratio is a ratio that serves as a real-time indicator of stress on the system stress. Each dispatcher computes this ratio by dividing the long-term p95 latency by the short-term p95 latency. A stable system has a ratio near 1.0; a value dropping towards 0.3 indicates that latency is rising sharply. When that threshold is crossed, the dispatcher temporarily increases the RU cost applied to a designated client class so that its token bucket drains faster and the request rate naturally backs off. If the ratio keeps falling, the same penalty can be expanded to additional classes until latency returns to a safe range.
The estimate uses the constant-memory P² algorithm [1], requiring no raw sample storage or cross-node coordination.
Press enter or click to view image in full size
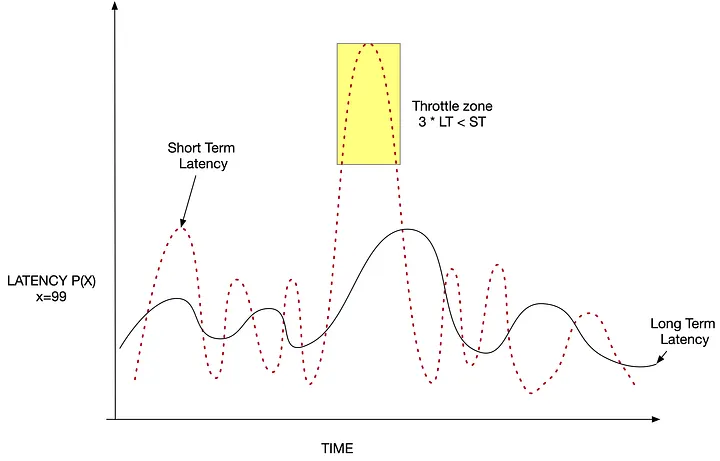
Latency response over time and illustration of throttling
The Control-Delay (CoDel) thread pool tackles the second hazard: queue buildup inside the dispatcher itself [2]. It monitors the time a request waits in the queue. If that sojourn time proves the system is already saturated, the request fails early, freeing up memory and threads for higher-priority work. An optional latency penalty can also be applied to RU accounting, charging more for queries from callers that persistently trigger the latency ratio.
Together, these layers — criticality, a real-time latency ratio, and adaptive queueing — form a shield that lets guest-facing traffic ride out backend hiccups. In practice, this system has cut recovery times by about half and keeps dispatchers stable without human intervention.
Hot-key detection and DDoS defence
Request-unit limits and load shedding keep client usage fair, but they cannot stop a stampede of identical reads aimed at one record. Imagine a listing that hits the front page of a major news outlet: tens of thousands of guests refresh their browser, all asking for the same key. A misconfigured crawler — or a deliberate botnet — can generate the same access pattern, only faster. The result is shard overload, a full dispatcher queue, and rising latency for unrelated work.
Mussel neutralises this amplification with a three-step hot-key defence layer**:** real-time detection, local caching, and request coalescing.
Real-time detection in constant space
Every dispatcher streams incoming keys into an in-memory top-k counter. The counter is a variant of the Space-Saving algorithm [2] popularized in Brian Hayes’s “Britney Spears Problem” essay [4]. In just a few megabytes, it tracks approximate hit counts, maintains a frequency-ordered heap, and surfaces the hottest keys in real time in each individual dispatcher.
Local caching and request coalescing
When a key crosses the hot threshold, the dispatcher serves it from a process-local LRU cache. Entries expire after roughly three seconds, so they vanish as soon as demand cools; no global cache is required. A cache miss can still arrive multiple times in the same millisecond, so the dispatcher tracks in-flight reads for hot keys. New arrivals attach to the pending future; the first backend response then fans out to all waiters. In most cases only one request per hot key per dispatcher pod ever reaches the storage layer.
Impact in production
In a controlled DDoS drill that targeted a small set of keys at ≈ million-QPS scale, the hot-key layer collapsed the burst to a trickle — each dispatcher forwarded only an occasional request, well below the capacity of any individual shard — so the backend never felt the surge.
Press enter or click to view image in full size
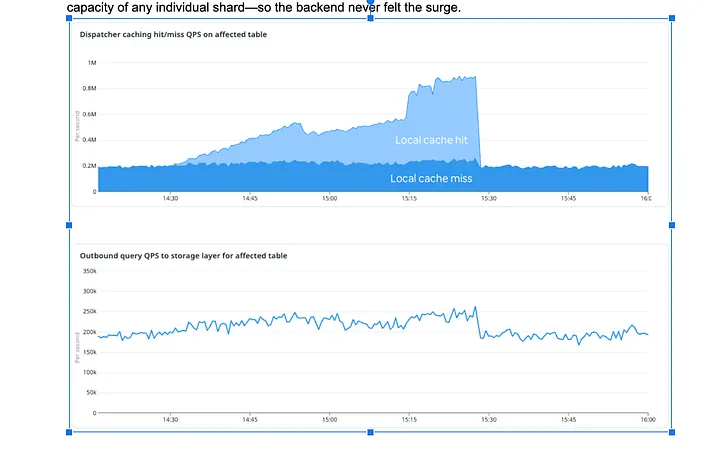
Hotkeys detected and served from dispatcher cache in real time
Retrospective and key takeaways
The journey from a single QPS counter to a layered, cost-aware QoS stack has reshaped how Mussel handles traffic and, just as importantly, how engineers think about fairness and resilience. A few themes surface when we look back across the stages described above.
The first is the value of early, visible impact. The initial release of request-unit accounting went live well before load shedding or hot-key defence. Soon after deployment it automatically throttled a caller whose range scans had been quietly inflating cluster latency. That early win validated the concept and built momentum for the deeper changes that followed.
A second lesson is to prefer to keep control loops local. All the key signals — P² latency quantiles, the Space-Saving top-k counter, and CoDel queue delay — run entirely inside each dispatcher. Because no cross-node coordination is required, the system scales linearly and continues to protect capacity even if the control plane is itself under stress.
Third, effective protection works on two different time-scales**.** Per-call RU pricing catches micro-spikes; the latency ratio and CoDel queue thresholds respond to macro slow-downs. Neither mechanism alone would have kept latency flat during the last controlled DDoS drill, but in concert they absorbed the shock and recovered within seconds.
Finally, QoS is a living system. Traffic patterns evolve, back-end capabilities improve, and new workloads appear. Planned next steps include database-native resource groups and automatic quota tuning from thirty-day usage curves. The principles that guided this project — measure true cost, react locally and quickly, layer defences — form a durable template, but the implementation will continue to grow with the platform it protects.
Does this type of work interest you? We’re hiring, check out open roles here.
📚 References
- Raj Jain and Imrich Chlamtac. 1985. The P² algorithm for dynamic calculation of quantiles and histograms without storing observations. Communications of the ACM, 28(10), 1076–1085. https://doi.org/10.1145/4372.4378
- Erik D. Demaine, Alejandro López-Ortiz, and J. Ian Munro. 2002. Frequency estimation of internet packet streams with limited space. In Algorithms — ESA 2002: 10th Annual European Symposium, Rome, Italy, September 17–21, 2002. Rolf H. Möhring and Rajeev Raman (Eds.). Lecture Notes in Computer Science, Vol. 2461. Springer, 348–360.
- Kathleen M. Nichols and Van Jacobson. 2012. Controlling queue delay. Communications of the ACM, 55(7), 42–50. https://doi.org/10.1145/2209249.2209264
- Brian Hayes. 2008. Computing science: The Britney Spears problem. American Scientist, 96(4), 274–279. https://www.americanscientist.org/article/the-britney-spears-problem