Memory is the Moat
You've felt this before, even if you didn't have a word for it.
You spend an hour walking an AI agent through your project. Your stack. Your style. Your preferences. The way you like to be talked to.
You close the tab.
The next morning, you open a new chat thread. The agent has no idea who you are.
It's Groundhog Day, and you're Bill Murray.
This is the memory problem. It's the unsexiest, most important problem in AI right now... and the way teams are solving it has gone through more evolution in the last two years than most people realize.
Get memory right and your agent starts to feel like a coworker who's been with you for years. Get it wrong and every conversation starts from zero.
Here's how we got from "starts from zero" to where we're going. And spoiler: where we're going, you won't need threads.
Stage 1: Message History (the naive answer)
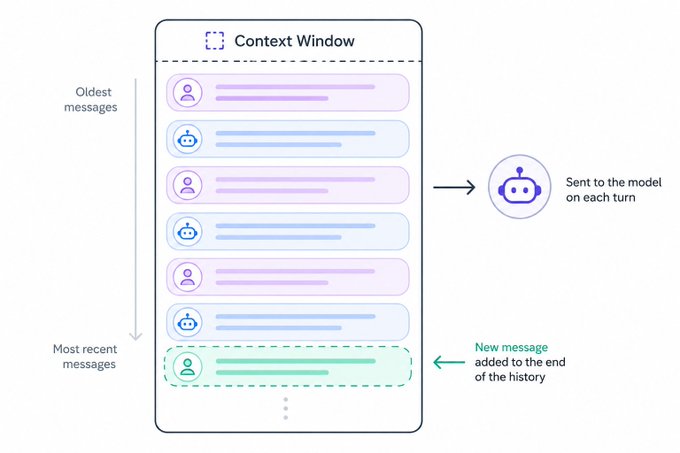
The simplest memory is no memory at all. Just shove every past message back into the context window on each call.
It works. For a while.
Then the conversation gets long, or the tool calls start dumping JSON into the context, and the window fills up. You hit the wall.
So teams patch it. Send only the last X messages. Or the last Y tokens. Or... and this is where the real damage starts... they introduce compaction, where the context gets summarized whenever a threshold is hit.
Compaction is brutal. It's lossy. It quietly drops things you needed and you don't know what's gone until the agent says something dumb.
We have a saying at Mastra: friends don't let friends use compaction.
But the bigger problem with message history isn't compaction. It's that every new chat session starts over. The agent never learns anything about you. Same questions. Same answers. Forever.
This is where most "AI chat" products live today. It's the floor, not the ceiling.
Stage 2: Scratchpad Memory (the first taste of "learning")
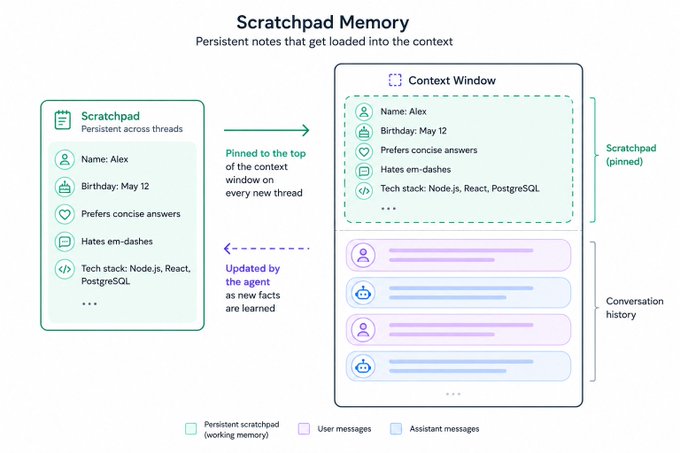
Next move: give the agent a scratchpad.
A file. A markdown doc. A text column in a database. Doesn't matter. What matters is the agent has a place to write things down — your name, your birthday, the fact that you hate em-dashes — and that scratchpad gets pinned to the top of the context on future chats.
Suddenly it feels different. The agent remembers. It learns. It calls you by name on Tuesday because you told it your name on Monday.
We call this Working Memory in Mastra, and it's a real upgrade. It persists across threads. It feels human-ish.
But it's primitive, and it breaks down fast.
Some teams try to dodge the breakdown by making it the user's problem. They prompt you to confirm what should be saved. They give you a settings page where you can edit your "memories" by hand.
This is the lazy approach. It's the team admitting we couldn't build a real memory system, so here's a textbox.
It will go the same way as threads. In a few years, people will look at hand-edited memories the way we look at people who used to defrag their hard drives. Quaint. Why did we ever do that?
There's also a quieter problem with scratchpad memory: it nukes the prompt cache. Every time the agent updates the scratchpad, the block at the top of the context window changes, and your cache is gone. More sophisticated systems keep the context stable mid-conversation and only refresh the memory block at the start of the next thread. But naive implementations bleed cost and latency every time the agent learns something new.
Stage 3: Retrieval-Based Memory (RAG memory)
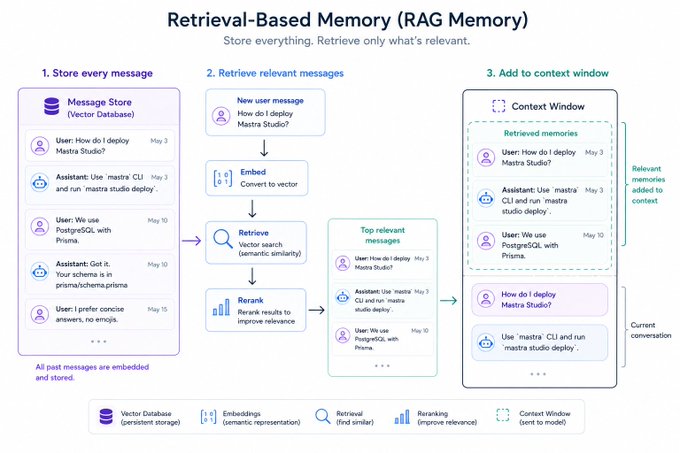
The next leap was: stop trying to fit memory into the prompt at all. Store every message in a database. Retrieve only what's relevant.
This is RAG memory. Two flavors:
Keyword matching (BM25-style): fast, dumb, surprisingly effective.
Semantic search: embed every message, store the embeddings in a vector DB, embed each new user message, and pull back the most similar past messages. Add reranking on top to filter the noise.
When it works, it works well. The agent can pull a relevant exchange from six months ago without ever needing to see it in between.
It also works across surfaces. If you have memory in a vector DB, it doesn't care which thread the message came from. That's a quiet superpower we'll come back to.
But it has its own bill to pay:
- Latency. Embedding, retrieval, reranking... every step adds time.
- No prompt cache. The context is rebuilt every turn.
- Fewer tokens, but not always cheaper queries. Cached tokens are heavily discounted by most providers. Rebuilding the context every turn often costs more than just keeping it stable, even if you're sending fewer tokens.
Mastra's Semantic Recall handles all of this automatically, but the tradeoffs are real no matter who builds it.
Retrieval memory is good. It's not the endgame.
Stage 4: Observer Agents (the human-inspired turn)
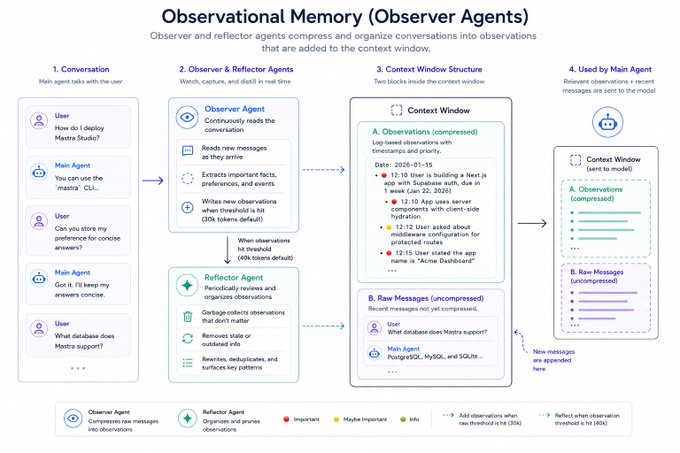
This is where it gets interesting.
Instead of asking the main agent to manage its own memory, write to its scratchpad, update its notes, decide what's important... you bring in a second agent whose entire job is to watch the conversation and produce memories from it.
The main agent gets to focus on the user. The observer handles the rest.
In Mastra's Observational Memory, two observer agents handle two things:
- An observer agent reads the conversation and creates dense, distilled observations at certain token thresholds.
- When observations pile up, a reflector agent rewrites and reorganizes them; collapsing duplicates, fixing stale facts, surfacing patterns.
You'll notice the parallel. This is roughly how human memory works. We don't store every minute of every day. We compress. We consolidate during sleep. We rewrite our own memories every time we recall them.
Anthropic recently announced something called "Dreaming" for Claude, which is... surprise... an observer agent reflecting on past conversations and producing memories from them. Same idea, different name.
And the next move is already happening: observer agents that don't just produce memories, but produce skills. Walk an agent through a task a few times, and the observer notices the pattern, packages it up, and hands the main agent a reusable skill for next time.
The agent stops needing to remember. It starts to learn.
Stage 5: Layered Memory (what most serious teams actually do)
Nobody picks one of these systems and calls it a day. The good teams stack them.
Working memory plus message history, for short-term coherence.
Observer agents plus retrieval, for long-term recall.
Different layers handle different jobs, the same way your brain has different systems for "what I had for breakfast" and "how to ride a bike."
Mastra's Observational Memory and our Memory Gateway have an optional retrieval tool wired in for exactly this reason. The future of agent memory isn't a single system, it's a memory architecture, the same way databases are an architecture, not a single product.
The thread is dying. You just don't know it yet.

Here's the part most people are still missing.
Threads were never the goal. Threads were a workaround.
We invented threads because early models had tiny context windows and no ability to manage memory on their own. So we made the human do it. Each thread was a little box where you, the user, did the manual labor of giving the agent enough context to be useful. Lose the thread, lose the context.
It made sense in 2023. It does not make sense in 2026.
The future of agent memory is multi-surface and transparent.
You'll send your agent a message in a web app at your desk.
You'll open Slack on your phone an hour later and ask it for the status of that request... same agent, same memory, no thread to dig up.
There won't be a "chat session" because there won't need to be one. The agent will know who you are, what you've been working on, what it's been doing for you, and where the conversation left off, across every surface you use.
We're not far. The best teams building agents today are already building toward this. Some of the systems above; observer agents, layered memory, vector retrieval... are the scaffolding for that world.
In a few years, you'll forget threads existed. You'll look at the chat history sidebar in some 2025 product the way you look at floppy disk save icons now. Ugly. Ancient.
The teams that get memory right are going to feel like magic. The teams that don't are going to feel like a tab you keep forgetting to close.
Memory is the moat.