Agentic Memory: A Detailed Breakdown
Imagine one day you hire a brilliant freelancer. On her first day, she’s incredible, catches every bug, writes clean docs, & even suggests improvements you hadn’t thought of. You’re impressed.
On the second day, you walk in & say, “Hey, remember that issue we discussed yesterday?”
She pauses. Looks at you. Slight smile.
“Sorry… what issue?”
No memory. No context. Completely gone. You will be shocked as I am while writing this here.
That’s exactly how most LLMs behave. Every new conversation is a fresh start. The model doesn’t know who you are, what you’ve built together, or what you discussed even a few minutes ago in another chat window.
For a simple chatbot, that’s fine. But for an agent, something that runs tasks, makes decisions, and improves over time, this kind of amnesia is a dealbreaker.
Because real intelligence isn’t just about responding well. It’s about remembering, learning, and building on what came before.
Memory is what turns a stateless system into something that can actually evolve.
What is agentic memory, really?
Agentic memory isn’t just one thing. It’s more like a system working behind the scenes, different types of storage, ways to retrieve information, and smart strategies to manage it all so an agent can actually carry context over time.
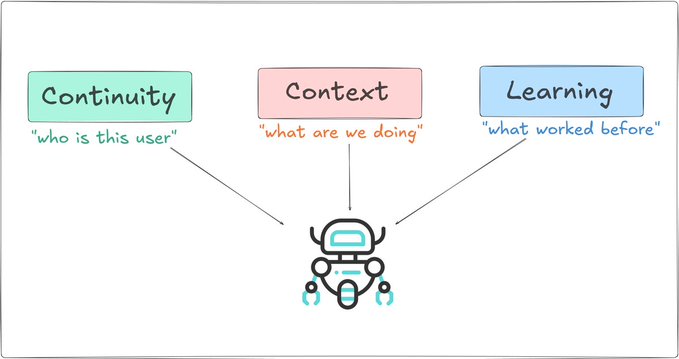
The key idea is simple: memory isn’t doing one job; it’s doing three very different ones at the same time.
➜ Continuity is about identity. It’s how the agent knows who you are, what you prefer, and what you’ve already built together. Without it, every interaction feels like starting from scratch.
➜ Context is about the task at hand. What just happened, which tool was used, what came back as a result, and what needs to happen next. It’s what keeps multi-step workflows from falling apart.
➜ Learning is about getting better. Understanding what worked, what didn’t, and slowly improving decisions over time instead of repeating the same mistakes.
Put together, it makes agents feel consistent, reliable, and a little more intelligent with every interaction.
Designed by author @techwith_ram
A well-designed agent memory system handles all three, using different storage backends for each.
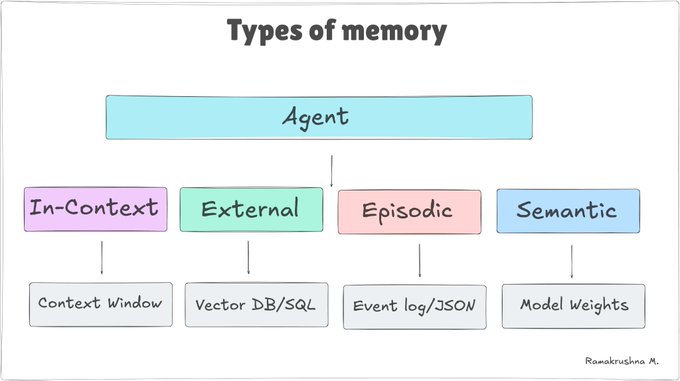
The 4-types of memory
The field has converged on four distinct memory types. Think of them as four different parts of the brain, each evolved for a specific job.
Designed by author @techwith_ram
1. In-context memory
The context window is your agent's working desk. Everything on it is instantly accessible. The model can reason over it in a single forward pass. No retrieval step required.
But the desk has a size limit. Every token costs money and time. And when the session ends, the desk gets wiped clean.
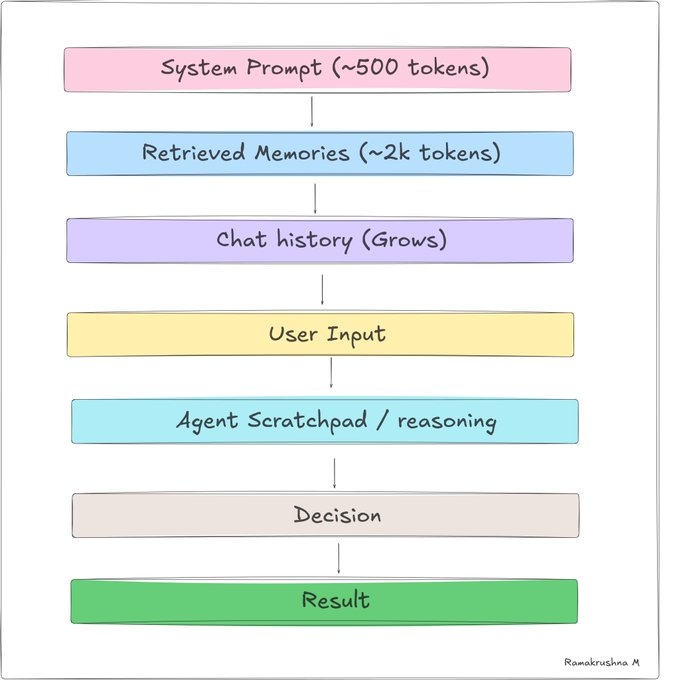
What lives in context?
- System prompt: agent persona, rules, capabilities, current date/user info
- Conversation history: the back-and-forth so far this session
- Tool call results: outputs from tools the agent just invoked
- Retrieved memories: chunks pulled in from external storage
- Scratchpad: intermediate reasoning (think-step-by-step outputs)
Designed by author @techwith_ram
The sliding window problem
In long conversations, history accumulates and eventually overflows the context limit. The naive solution of truncating the oldest messages loses important early context. Better strategies:
- Summarization: periodically compress old turns into a brief summary and replace them with the summary
- Selective retention: keep turns that contain key facts, decisions, or tool results; discard small talk.
- Offload to external memory: extract important facts into a vector store, then retrieve them as needed
2. External memory
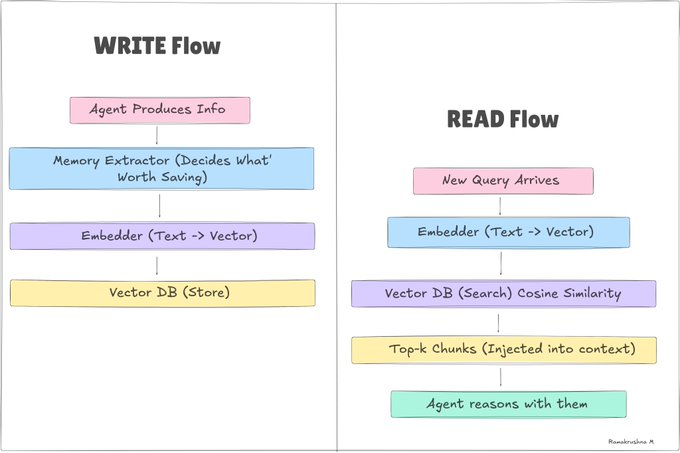
External memory is anything that persists outside the model—databases, vector stores, key-value stores, and files. It survives session boundaries. Your agent can remember something from six months ago if you store it right.
There are two flavors of external storage:
Structured Store (Exact Lookup): PostgreSQL, Redis, SQLite. You query by key, ID, or SQL. Fast, predictable, great for user profiles, preferences, and structured data.
Vector Stores (Semantic Search): Pinecone, Chroma, pgvector. You query by meaning, "find memories similar to this concept." "Essential for unstructured notes and episodic recall.
Designed by author @techwith_ram
The retrieval step is a bottleneck. If you don't retrieve the right memories, the agent behaves as if they don't exist. Good memory architecture is 20% storage and 80% retrieval design.
3. Episodic memory
Episodic memory is the most underappreciated type. While external memory stores facts, episodic memory stores events, specifically the outcomes of past actions.
The simplest form is a structured log: every time the agent completes a task, it records what happened. Over time, this log becomes a rich source of self-knowledge the agent can consult before making decisions.
What an episode looks like:
{
"episode_id": "ep_20240315_003",
"timestamp": "2024-03-15T14:23:11Z",
"task": "Summarize 50-page PDF into 3 bullet points",
"approach": "Sequential chunking, 2000 tokens per chunk",
"outcome": "success",
"duration_ms": 4820,
"token_cost": 12400,
"quality_score": 0.91,
"notes": "Worked well. Hierarchical chunking would be faster.",
"embedding": [0.023, -0.441, 0.182, /* ... 1536 dims */]
}
When a new task comes in, the agent retrieves the most semantically similar past episodes and uses them to pick a strategy. This is essentially few-shot learning from personal history rather than from a handcrafted dataset.
The reflection loop👇
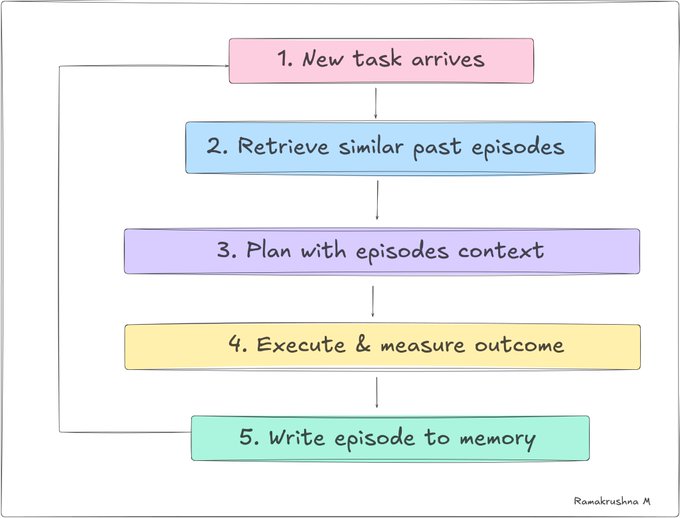
Designed by author @techwith_ram
Semantic/parametric memory
This is the memory the model was born with. Everything is encoded in weights during training, facts about the world, language patterns, reasoning strategies, coding conventions, and cultural knowledge.
It's always there. The agent never has to retrieve it. But it comes with hard limitations:
- Frozen at training time: the model doesn't know what happened after its cutoff date
- Can't be updated at runtime: you can't inject new permanent facts without retraining or fine-tuning
- Opaque: you can't inspect exactly what the model "knows" or doesn't
- Hallucination-prone: the model fills gaps with plausible-but-wrong completions.
For anything time-sensitive, domain-specific, or private, don't rely on parametric memory. Use external retrieval. Parametric memory is your fallback for general world knowledge when no better source exists.
The right mental model: parametric memory is the agent's general education. External, episodic, and in-context memory are the agent's on-the-job experience. The best agents combine both.
How does memory flow through an agent loop?
Let's put it all together. Here's what happens every single time an agent processes a request—showing every memory system in action.
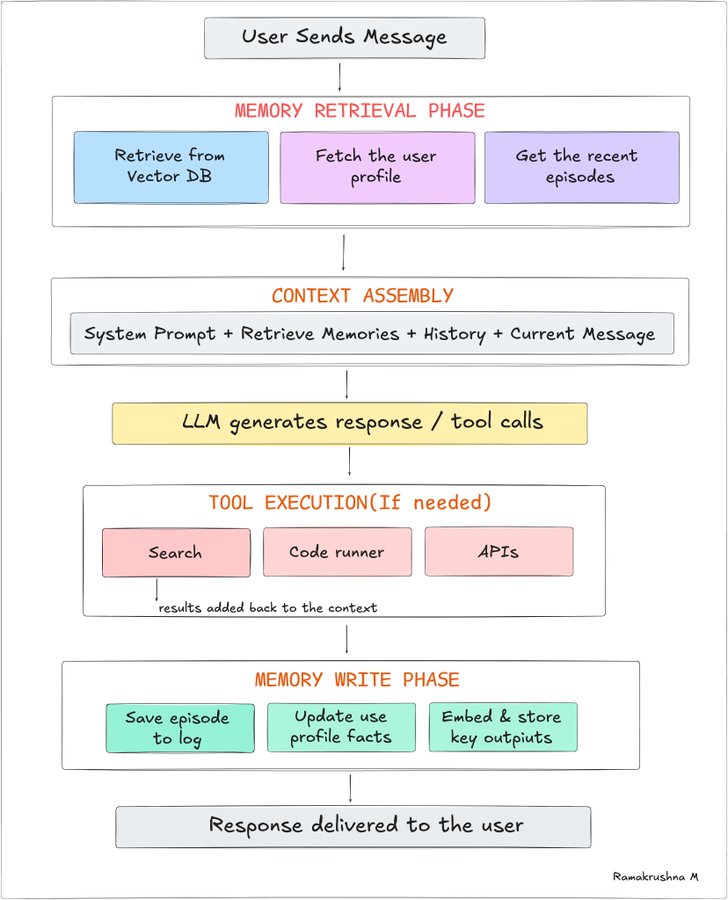
Designed by author @techwith_ram
Notice that memory operations bookend the LLM call: retrieval before, writing after. The model itself is stateless; the memory system is what gives the illusion of a stateful, aware agent.
Building a memory layer
Let's build this. We'll use Python with OpenAI for embeddings and ChromaDB as our local vector store. The same concepts apply to any other stack—swap the libraries.
Let's build this. We'll use Python with OpenAI for embeddings and ChromaDB as our local vector store. The same concepts apply to any other stack—swap the libraries.
pip install chromadb openai anthropic python-dotenv
The MemoryStore class
This handles writing memories (with embeddings) and semantic retrieval. It's the foundation everything else sits on.
import chromadb
from openai import OpenAI
from datetime import datetime
import json, uuid
class MemoryStore:
"""Persistent vector memory for an AI agent."""
def __init__(self, agent_id: str, persist_dir: str = "./memory_db"):
self.agent_id = agent_id
self.openai = OpenAI()
# ChromaDB stores vectors on disk, persists across restarts
self.client = chromadb.PersistentClient(path=persist_dir)
self.collection = self.client.get_or_create_collection(
name=f"agent_{agent_id}_memories",
metadata={"hnsw:space": "cosine"} # cosine similarity
)
def _embed(self, text: str) -> list[float]:
"""Convert text to embedding vector using OpenAI."""
response = self.openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def remember(
self,
content: str,
memory_type: str = "general",
metadata: dict = None
) -> str:
"""Store a memory. Returns the memory ID."""
memory_id = str(uuid.uuid4())
embedding = self._embed(content)
meta = {
"type": memory_type,
"timestamp": datetime.utcnow().isoformat(),
"agent_id": self.agent_id,
**(metadata or {})
}
self.collection.add(
ids=[memory_id],
embeddings=[embedding],
documents=[content],
metadatas=[meta]
)
return memory_id
def recall(
self,
query: str,
k: int = 5,
memory_type: str = None,
min_relevance: float = 0.6
) -> list[dict]:
"""Retrieve the k most relevant memories for a query."""
query_embedding = self._embed(query)
where = {"type": memory_type} if memory_type else None
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=k,
where=where,
include=["documents", "metadatas", "distances"]
)
memories = []
for doc, meta, dist in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
relevance = 1 - dist # cosine distance → similarity
if relevance >= min_relevance:
memories.append({
"content": doc,
"metadata": meta,
"relevance": round(relevance, 3)
})
return sorted(memories, key=lambda x: x["relevance"], reverse=True)
def forget(self, memory_id: str):
"""Delete a specific memory (GDPR compliance, stale data, etc.)"""
self.collection.delete(ids=[memory_id])
The EpisodicLogger class
Now let's add the episode logging layer on top.
from .store import MemoryStore
from dataclasses import dataclass, asdict
from typing import Optional
import time
@dataclass
class Episode:
task: str
approach: str
outcome: str # "success" | "partial" | "failure"
duration_ms: int
token_cost: int
quality_score: float # 0.0 – 1.0, set by evaluator or user
notes: str = ""
error: Optional[str] = None
class EpisodicLogger:
def __init__(self, memory_store: MemoryStore):
self.store = memory_store
def log(self, episode: Episode):
"""Save an episode to memory as a searchable document."""
# Build a rich text representation for semantic search
doc = (
f"Task: {episode.task}\n"
f"Approach: {episode.approach}\n"
f"Outcome: {episode.outcome}\n"
f"Notes: {episode.notes}"
)
self.store.remember(
content=doc,
memory_type="episode",
metadata={
"outcome": episode.outcome,
"quality_score": episode.quality_score,
"duration_ms": episode.duration_ms,
"token_cost": episode.token_cost,
}
)
def recall_similar(self, task: str, k: int = 3) -> list[dict]:
"""Find past episodes similar to the current task."""
return self.store.recall(
query=task,
k=k,
memory_type="episode",
min_relevance=0.65
)
Putting it together: a memory-augmented agent
import anthropic
from memory.store import MemoryStore
from memory.episodic import EpisodicLogger, Episode
import time
class MemoryAugmentedAgent:
def __init__(self, agent_id: str):
self.client = anthropic.Anthropic()
self.memory = MemoryStore(agent_id)
self.episodes = EpisodicLogger(self.memory)
def _build_memory_context(self, user_message: str) -> str:
"""Retrieve relevant memories and format them for injection."""
# Semantic search for related facts
memories = self.memory.recall(user_message, k=4)
# Similar past task approaches
episodes = self.episodes.recall_similar(user_message, k=2)
context_parts = []
if memories:
context_parts.append("## Relevant memories\n" +
"\n".join([
f"- [{m['metadata']['type']}] {m['content']}"
f" (relevance: {m['relevance']})"
for m in memories
])
)
if episodes:
context_parts.append("## Past similar tasks\n" +
"\n".join([
f"- {e['content'][:200]}..."
for e in episodes
])
)
return "\n\n".join(context_parts) if context_parts else ""
def run(self, user_message: str) -> str:
start = time.time()
# 1. Retrieve relevant memory
memory_context = self._build_memory_context(user_message)
# 2. Build system prompt with injected memory
system = """You are a helpful agent with memory.
You have access to relevant context from past interactions.
Use this context to give better, more personalized responses.
"""
if memory_context:
system += f"\n\n{memory_context}"
# 3. Call the model
response = self.client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
system=system,
messages=[{"role": "user", "content": user_message}]
)
answer = response.content[0].text
duration = int((time.time() - start) * 1000)
# 4. Save useful info to memory for next time
self.memory.remember(
content=f"User asked: {user_message[:200]}",
memory_type="interaction"
)
# 5. Log the episode
self.episodes.log(Episode(
task=user_message[:200],
approach="single-turn with memory retrieval",
outcome="success",
duration_ms=duration,
token_cost=response.usage.input_tokens + response.usage.output_tokens,
quality_score=1.0, # would come from evaluation in prod
))
return answer
Vector databases
It's the heart of any serious memory system. Instead of querying by exact match (like SQL), it finds the nearest neighbors of a vector in high-dimensional space. This is what enables semantic search — finding memories that are conceptually related even if they share no words.
How similarity search works
Every memory is converted to a vector (an array of 1,536 floats with OpenAI's embedding model). Conceptually similar texts produce similar vectors. When you query, you embed the query and find the closest vectors using cosine similarity.
import numpy as np
def cosine_similarity(a: list, b: list) -> float:
"""
1.0 = identical meaning
0.0 = unrelated
-1.0 = opposite meaning
"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Example: these two sentences will have high similarity
embedding_a = embed("The user prefers dark mode")
embedding_b = embed("They like their interface theme to be dark")
score = cosine_similarity(embedding_a, embedding_b)
# → ~0.91 (very similar)
Start with ChromaDB for local development. When you're ready to deploy, evaluate pgvector if you're already on Postgres with zero extra infrastructure. Use Pinecone or Qdrant when you need serious scale.
Memory management
Real memory systems don't just accumulate. They curate. An ever-growing, unfocused store degrades over time—retrieval gets noisier, latency climbs, and contradictory memories confuse the agent.
You need a forgetting strategy. Here are the three main approaches:
1. Time-based decay
Older memories are less relevant. Score memories by a combination of recency and semantic relevance. The formula used in research:
import math
from datetime import datetime
def memory_score(
relevance: float, # cosine similarity 0–1
importance: float, # stored at write time 0–1
created_at: datetime, # when memory was formed
recency_weight: float = 0.3,
decay_factor: float = 0.995
) -> float:
"""
Inspired by the Generative Agents paper (Park et al., 2023).
Balances: how relevant, how important, how recent.
"""
hours_old = (datetime.utcnow() - created_at).total_seconds() / 3600
recency = math.pow(decay_factor, hours_old)
return (
relevance * 0.4 +
importance * 0.3 +
recency * recency_weight
)
2. Importance scoring at write time
When storing a memory, ask the model to score its own output for importance. Only store high-scoring items. This filters noise at the source.
import re
async def score_importance(client, content: str) -> float:
"""Ask the LLM if information is worth saving (0.0 to 1.0)."""
prompt = f"""Rate the importance of saving this for future interactions.
0.0 = trivial (greeting)
0.5 = moderately useful
1.0 = critical (preferences, errors, decisions)
Information: {content}
Reply with ONLY the number."""
try:
response = await client.messages.create(
model="claude-3-haiku-20240307", # Use the current available Haiku model
max_tokens=10,
messages=[{"role": "user", "content": prompt}]
)
# Extract the first string that looks like a float/int
text = response.content[0].text.strip()
match = re.search(r"[-+]?\d*\.\d+|\d+", text)
if match:
score = float(match.group())
return max(0.0, min(1.0, score))
except Exception:
pass
return 0.5 # Default fallback
3. Periodic consolidation
Run a nightly job that merges duplicate or highly similar memories into a single canonical summary. This is analogous to how human sleep consolidates memories.
async def consolidate_memories(store: MemoryStore, similarity_threshold: float = 0.92):
"""Efficiently merge near-duplicate memories using vector search."""
all_mems = store.collection.get(include=["documents", "embeddings", "ids"])
if not all_mems["ids"]:
return
visited = set()
consolidated_docs = []
for i, (mem_id, doc, emb) in enumerate(zip(
all_mems["ids"], all_mems["documents"], all_mems["embeddings"]
)):
if mem_id in visited:
continue
# Use the vector store's built-in search to find neighbors
# this is much faster than a manual nested loop
results = store.collection.query(
query_embeddings=[emb],
n_results=10, # Adjust based on expected density
include=["documents", "distances"]
)
# Identify group members (1.0 - distance = cosine similarity)
group = [doc]
visited.add(mem_id)
for res_id, res_doc, dist in zip(results["ids"][0], results["documents"][0], results["distances"][0]):
sim = 1.0 - dist
if res_id != mem_id and res_id not in visited and sim >= similarity_threshold:
group.append(res_doc)
visited.add(res_id)
# Process the group
if len(group) > 1:
summary = await summarize_group(group) # Likely needs to be async
consolidated_docs.append(summary)
else:
consolidated_docs.append(doc)
# Atomic-ish replacement: Clear and Re-populate
store.collection.delete(where={})
for doc in consolidated_docs:
await store.remember(doc)
FInal Thoughts
At the end of the day, memory is what makes an AI feel less like a tool & more like a partner. Without it, every interaction starts from zero. With it, an agent can understand, adapt, and improve over time.
The real power isn’t just in the model; it’s in how you design what the model remembers, what it forgets, and how it uses that information.
Build the memory layer right, and everything else becomes smarter.
Codes are AI-generated.
Follow @techwith_ram for more such posts.